 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOrganizing Unstructured Image Collections using Natural Language
Paper and Code



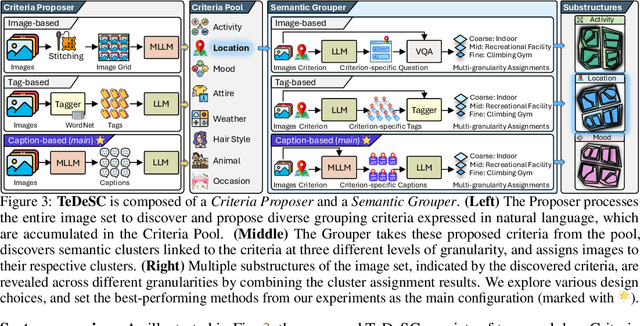
Organizing unstructured visual data into semantic clusters is a key challenge in computer vision. Traditional deep clustering (DC) approaches focus on a single partition of data, while multiple clustering (MC) methods address this limitation by uncovering distinct clustering solutions. The rise of large language models (LLMs) and multimodal LLMs (MLLMs) has enhanced MC by allowing users to define clustering criteria in natural language. However, manually specifying criteria for large datasets is impractical. In this work, we introduce the task Semantic Multiple Clustering (SMC) that aims to automatically discover clustering criteria from large image collections, uncovering interpretable substructures without requiring human input. Our framework, Text Driven Semantic Multiple Clustering (TeDeSC), uses text as a proxy to concurrently reason over large image collections, discover partitioning criteria, expressed in natural language, and reveal semantic substructures. To evaluate TeDeSC, we introduce the COCO-4c and Food-4c benchmarks, each containing four grouping criteria and ground-truth annotations. We apply TeDeSC to various applications, such as discovering biases and analyzing social media image popularity, demonstrating its utility as a tool for automatically organizing image collections and revealing novel insights.