 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTorch-Uncertainty: A Deep Learning Framework for Uncertainty Quantification
Nov 13, 2025Deep Neural Networks (DNNs) have demonstrated remarkable performance across various domains, including computer vision and natural language processing. However, they often struggle to accurately quantify the uncertainty of their predictions, limiting their broader adoption in critical real-world applications. Uncertainty Quantification (UQ) for Deep Learning seeks to address this challenge by providing methods to improve the reliability of uncertainty estimates. Although numerous techniques have been proposed, a unified tool offering a seamless workflow to evaluate and integrate these methods remains lacking. To bridge this gap, we introduce Torch-Uncertainty, a PyTorch and Lightning-based framework designed to streamline DNN training and evaluation with UQ techniques and metrics. In this paper, we outline the foundational principles of our library and present comprehensive experimental results that benchmark a diverse set of UQ methods across classification, segmentation, and regression tasks. Our library is available at https://github.com/ENSTA-U2IS-AI/Torch-Uncertainty
Understanding Why Label Smoothing Degrades Selective Classification and How to Fix It
Mar 19, 2024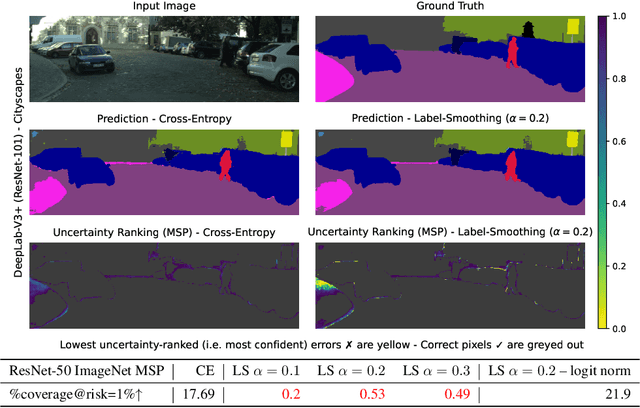
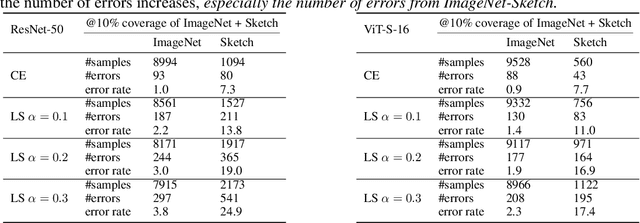


Label smoothing (LS) is a popular regularisation method for training deep neural network classifiers due to its effectiveness in improving test accuracy and its simplicity in implementation. "Hard" one-hot labels are "smoothed" by uniformly distributing probability mass to other classes, reducing overfitting. In this work, we reveal that LS negatively affects selective classification (SC) - where the aim is to reject misclassifications using a model's predictive uncertainty. We first demonstrate empirically across a range of tasks and architectures that LS leads to a consistent degradation in SC. We then explain this by analysing logit-level gradients, showing that LS exacerbates overconfidence and underconfidence by regularising the max logit more when the probability of error is low, and less when the probability of error is high. This elucidates previously reported experimental results where strong classifiers underperform in SC. We then demonstrate the empirical effectiveness of logit normalisation for recovering lost SC performance caused by LS. Furthermore, based on our gradient analysis, we explain why such normalisation is effective. We will release our code shortly.
Make Me a BNN: A Simple Strategy for Estimating Bayesian Uncertainty from Pre-trained Models
Dec 23, 2023



Deep Neural Networks (DNNs) are powerful tools for various computer vision tasks, yet they often struggle with reliable uncertainty quantification - a critical requirement for real-world applications. Bayesian Neural Networks (BNN) are equipped for uncertainty estimation but cannot scale to large DNNs that are highly unstable to train. To address this challenge, we introduce the Adaptable Bayesian Neural Network (ABNN), a simple and scalable strategy to seamlessly transform DNNs into BNNs in a post-hoc manner with minimal computational and training overheads. ABNN preserves the main predictive properties of DNNs while enhancing their uncertainty quantification abilities through simple BNN adaptation layers (attached to normalization layers) and a few fine-tuning steps on pre-trained models. We conduct extensive experiments across multiple datasets for image classification and semantic segmentation tasks, and our results demonstrate that ABNN achieves state-of-the-art performance without the computational budget typically associated with ensemble methods.
A Symmetry-Aware Exploration of Bayesian Neural Network Posteriors
Oct 12, 2023



The distribution of the weights of modern deep neural networks (DNNs) - crucial for uncertainty quantification and robustness - is an eminently complex object due to its extremely high dimensionality. This paper proposes one of the first large-scale explorations of the posterior distribution of deep Bayesian Neural Networks (BNNs), expanding its study to real-world vision tasks and architectures. Specifically, we investigate the optimal approach for approximating the posterior, analyze the connection between posterior quality and uncertainty quantification, delve into the impact of modes on the posterior, and explore methods for visualizing the posterior. Moreover, we uncover weight-space symmetries as a critical aspect for understanding the posterior. To this extent, we develop an in-depth assessment of the impact of both permutation and scaling symmetries that tend to obfuscate the Bayesian posterior. While the first type of transformation is known for duplicating modes, we explore the relationship between the latter and L2 regularization, challenging previous misconceptions. Finally, to help the community improve our understanding of the Bayesian posterior, we will shortly release the first large-scale checkpoint dataset, including thousands of real-world models and our codes.
Learning to Generate Training Datasets for Robust Semantic Segmentation
Aug 18, 2023



Semantic segmentation techniques have shown significant progress in recent years, but their robustness to real-world perturbations and data samples not seen during training remains a challenge, particularly in safety-critical applications. In this paper, we propose a novel approach to improve the robustness of semantic segmentation techniques by leveraging the synergy between label-to-image generators and image-to-label segmentation models. Specifically, we design and train Robusta, a novel robust conditional generative adversarial network to generate realistic and plausible perturbed or outlier images that can be used to train reliable segmentation models. We conduct in-depth studies of the proposed generative model, assess the performance and robustness of the downstream segmentation network, and demonstrate that our approach can significantly enhance the robustness of semantic segmentation techniques in the face of real-world perturbations, distribution shifts, and out-of-distribution samples. Our results suggest that this approach could be valuable in safety-critical applications, where the reliability of semantic segmentation techniques is of utmost importance and comes with a limited computational budget in inference. We will release our code shortly.
Packed-Ensembles for Efficient Uncertainty Estimation
Oct 17, 2022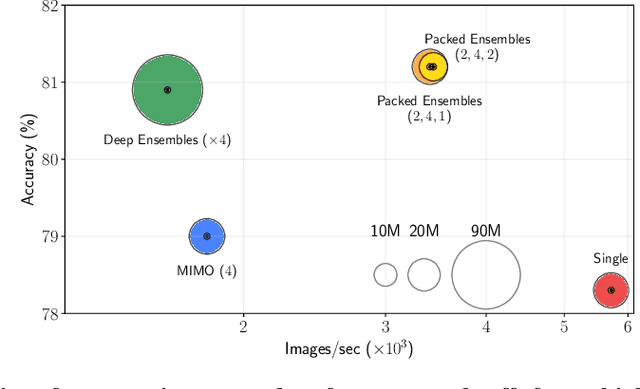
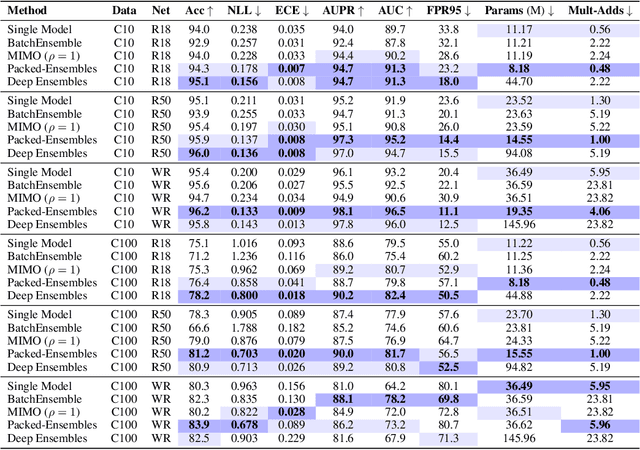
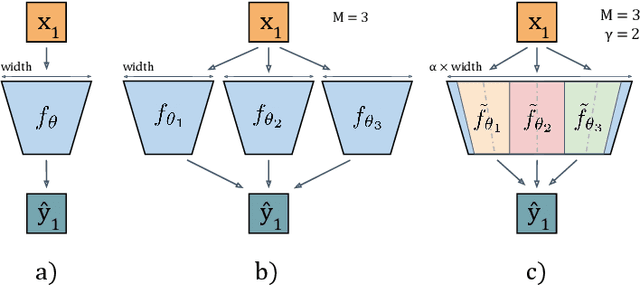

Deep Ensembles (DE) are a prominent approach achieving excellent performance on key metrics such as accuracy, calibration, uncertainty estimation, and out-of-distribution detection. However, hardware limitations of real-world systems constrain to smaller ensembles and lower capacity networks, significantly deteriorating their performance and properties. We introduce Packed-Ensembles (PE), a strategy to design and train lightweight structured ensembles by carefully modulating the dimension of their encoding space. We leverage grouped convolutions to parallelize the ensemble into a single common backbone and forward pass to improve training and inference speeds. PE is designed to work under the memory budget of a single standard neural network. Through extensive studies we show that PE faithfully preserve the properties of DE, e.g., diversity, and match their performance in terms of accuracy, calibration, out-of-distribution detection and robustness to distribution shift.