 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInfraParis: A multi-modal and multi-task autonomous driving dataset
Sep 27, 2023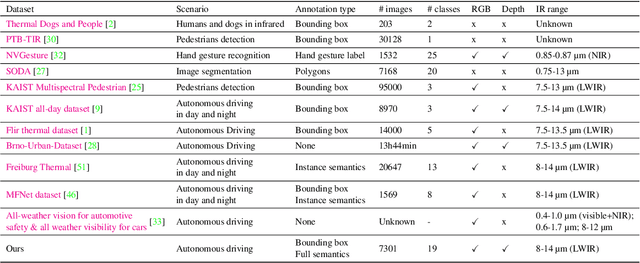

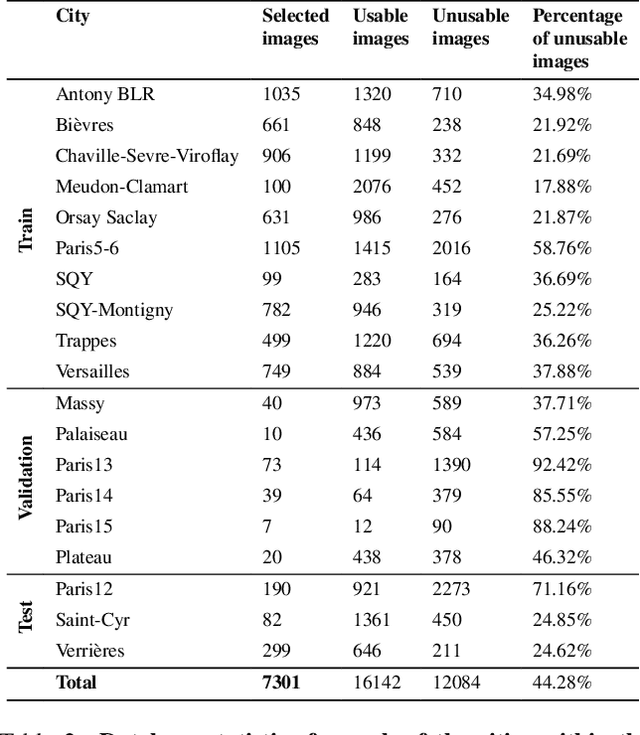
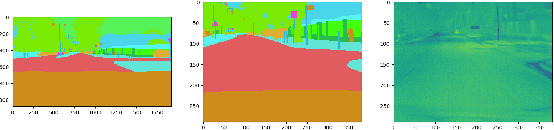
Current deep neural networks (DNNs) for autonomous driving computer vision are typically trained on specific datasets that only involve a single type of data and urban scenes. Consequently, these models struggle to handle new objects, noise, nighttime conditions, and diverse scenarios, which is essential for safety-critical applications. Despite ongoing efforts to enhance the resilience of computer vision DNNs, progress has been sluggish, partly due to the absence of benchmarks featuring multiple modalities. We introduce a novel and versatile dataset named InfraParis that supports multiple tasks across three modalities: RGB, depth, and infrared. We assess various state-of-the-art baseline techniques, encompassing models for the tasks of semantic segmentation, object detection, and depth estimation.
Learning to Generate Training Datasets for Robust Semantic Segmentation
Aug 18, 2023



Semantic segmentation techniques have shown significant progress in recent years, but their robustness to real-world perturbations and data samples not seen during training remains a challenge, particularly in safety-critical applications. In this paper, we propose a novel approach to improve the robustness of semantic segmentation techniques by leveraging the synergy between label-to-image generators and image-to-label segmentation models. Specifically, we design and train Robusta, a novel robust conditional generative adversarial network to generate realistic and plausible perturbed or outlier images that can be used to train reliable segmentation models. We conduct in-depth studies of the proposed generative model, assess the performance and robustness of the downstream segmentation network, and demonstrate that our approach can significantly enhance the robustness of semantic segmentation techniques in the face of real-world perturbations, distribution shifts, and out-of-distribution samples. Our results suggest that this approach could be valuable in safety-critical applications, where the reliability of semantic segmentation techniques is of utmost importance and comes with a limited computational budget in inference. We will release our code shortly.