 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSS3D: End2End Self-Supervised 3D from Web Videos
Apr 24, 2026We present SS3D, a web-scale SfM-based self-supervision pretraining pipeline for feed-forward 3D estimation from monocular video. Our model jointly predicts depth, ego-motion, and intrinsics in a single forward pass and is trained/evaluated as a coherent end-to-end 3D estimator. To stabilize joint learning, we use an intrinsics-first two-stage schedule and a unified single-checkpoint evaluation protocol. Scaling SfM self-supervision to unconstrained web video is challenging due to weak multi-view observability and strong corpus heterogeneity; we address these with a multi-view signal proxy (MVS) used for filtering and curriculum sampling, and with expert training distilled into a single student. Pretraining on YouTube-8M (~100M frames after filtering) yields strong cross-domain zero-shot transfer and improved fine-tuning performance over prior self-supervised baselines. We release the pretrained checkpoint and code.
Multimodal embodiment-aware navigation transformer
Apr 21, 2026Goal-conditioned navigation models for ground robots trained using supervised learning show promising zero-shot transfer, but their collision-avoidance capability nevertheless degrades under distribution shift, i.e. environmental, robot or sensor configuration changes. We propose ViLiNT a multimodal, attention-based policy for goal navigation, trained on heterogeneous data from multiple platforms and environments, which improves robustness with two key features. First, we fuse RGB images, 3D LiDAR point clouds, a goal embedding and a robot's embodiment descriptor with a transformer architecture to capture complementary geometry and appearance cues. The transformer's output is used to condition a diffusion model that generates navigable trajectories. Second, using automatically generated offline labels, we train a path clearance prediction head for scoring and ranking trajectories produced by the diffusion model. The diffusion conditioning as well as the trajectory ranking head depend on a robot's embodiment token that allows our model to generate and select trajectories with respect to the robot's dimensions. Across three simulated environments, ViLiNT improves Success Rate on average by 166\% over equivalent state-of-the-art vision-only baseline (NoMaD). This increase in performance is confirmed through real-world deployments of a rover navigating in obstacle fields. These results highlight that combining multimodal fusion with our collision prediction mechanism leads to improved off-road navigation robustness.
An Open-Source LiDAR and Monocular Off-Road Autonomous Navigation Stack
Apr 03, 2026Off-road autonomous navigation demands reliable 3D perception for robust obstacle detection in challenging unstructured terrain. While LiDAR is accurate, it is costly and power-intensive. Monocular depth estimation using foundation models offers a lightweight alternative, but its integration into outdoor navigation stacks remains underexplored. We present an open-source off-road navigation stack supporting both LiDAR and monocular 3D perception without task-specific training. For the monocular setup, we combine zero-shot depth prediction (Depth Anything V2) with metric depth rescaling using sparse SLAM measurements (VINS-Mono). Two key enhancements improve robustness: edge-masking to reduce obstacle hallucination and temporal smoothing to mitigate the impact of SLAM instability. The resulting point cloud is used to generate a robot-centric 2.5D elevation map for costmap-based planning. Evaluated in photorealistic simulations (Isaac Sim) and real-world unstructured environments, the monocular configuration matches high-resolution LiDAR performance in most scenarios, demonstrating that foundation-model-based monocular depth estimation is a viable LiDAR alternative for robust off-road navigation. By open-sourcing the navigation stack and the simulation environment, we provide a complete pipeline for off-road navigation as well as a reproducible benchmark. Code available at https://github.com/LARIAD/Offroad-Nav.
Foundation Models Meet Low-Cost Sensors: Test-Time Adaptation for Rescaling Disparity for Zero-Shot Metric Depth Estimation
Dec 18, 2024



The recent development of foundation models for monocular depth estimation such as Depth Anything paved the way to zero-shot monocular depth estimation. Since it returns an affine-invariant disparity map, the favored technique to recover the metric depth consists in fine-tuning the model. However, this stage is costly to perform because of the training but also due to the creation of the dataset. It must contain images captured by the camera that will be used at test time and the corresponding ground truth. Moreover, the fine-tuning may also degrade the generalizing capacity of the original model. Instead, we propose in this paper a new method to rescale Depth Anything predictions using 3D points provided by low-cost sensors or techniques such as low-resolution LiDAR, stereo camera, structure-from-motion where poses are given by an IMU. Thus, this approach avoids fine-tuning and preserves the generalizing power of the original depth estimation model while being robust to the noise of the sensor or of the depth model. Our experiments highlight improvements relative to other metric depth estimation methods and competitive results compared to fine-tuned approaches. Code available at https://gitlab.ensta.fr/ssh/monocular-depth-rescaling.
Hierarchical Light Transformer Ensembles for Multimodal Trajectory Forecasting
Mar 26, 2024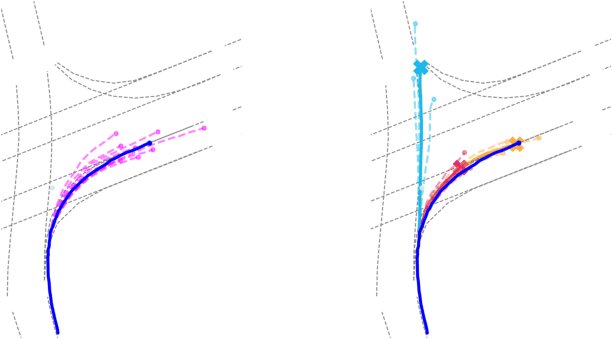
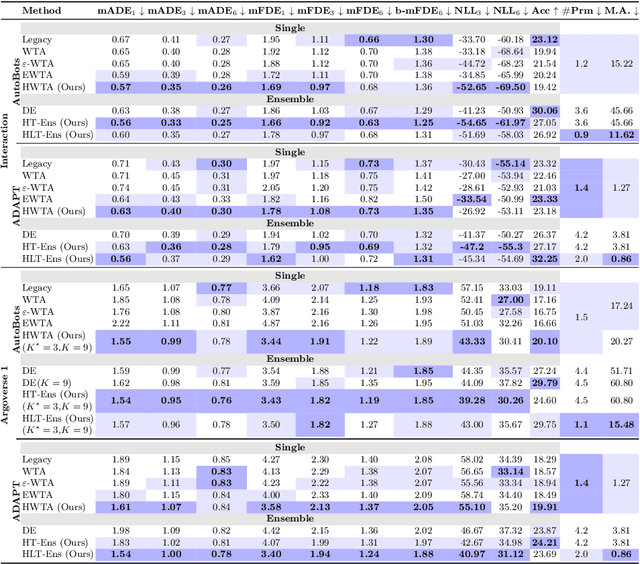
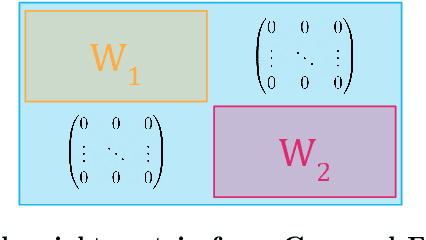
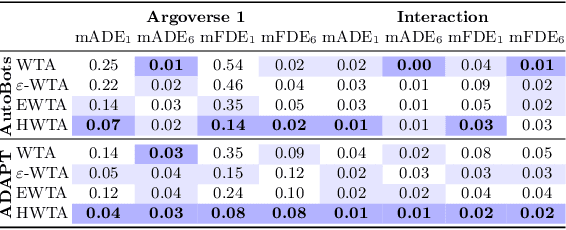
Accurate trajectory forecasting is crucial for the performance of various systems, such as advanced driver-assistance systems and self-driving vehicles. These forecasts allow to anticipate events leading to collisions and, therefore, to mitigate them. Deep Neural Networks have excelled in motion forecasting, but issues like overconfidence and uncertainty quantification persist. Deep Ensembles address these concerns, yet applying them to multimodal distributions remains challenging. In this paper, we propose a novel approach named Hierarchical Light Transformer Ensembles (HLT-Ens), aimed at efficiently training an ensemble of Transformer architectures using a novel hierarchical loss function. HLT-Ens leverages grouped fully connected layers, inspired by grouped convolution techniques, to capture multimodal distributions, effectively. Through extensive experimentation, we demonstrate that HLT-Ens achieves state-of-the-art performance levels, offering a promising avenue for improving trajectory forecasting techniques.
On Double Descent in Reinforcement Learning with LSTD and Random Features
Oct 20, 2023



Temporal Difference (TD) algorithms are widely used in Deep Reinforcement Learning (RL). Their performance is heavily influenced by the size of the neural network. While in supervised learning, the regime of over-parameterization and its benefits are well understood, the situation in RL is much less clear. In this paper, we present a theoretical analysis of the influence of network size and $l_2$-regularization on performance. We identify the ratio between the number of parameters and the number of visited states as a crucial factor and define over-parameterization as the regime when it is larger than one. Furthermore, we observe a double descent phenomenon, i.e., a sudden drop in performance around the parameter/state ratio of one. Leveraging random features and the lazy training regime, we study the regularized Least-Square Temporal Difference (LSTD) algorithm in an asymptotic regime, as both the number of parameters and states go to infinity, maintaining a constant ratio. We derive deterministic limits of both the empirical and the true Mean-Square Bellman Error (MSBE) that feature correction terms responsible for the double-descent. Correction terms vanish when the $l_2$-regularization is increased or the number of unvisited states goes to zero. Numerical experiments with synthetic and small real-world environments closely match the theoretical predictions.
InfraParis: A multi-modal and multi-task autonomous driving dataset
Sep 27, 2023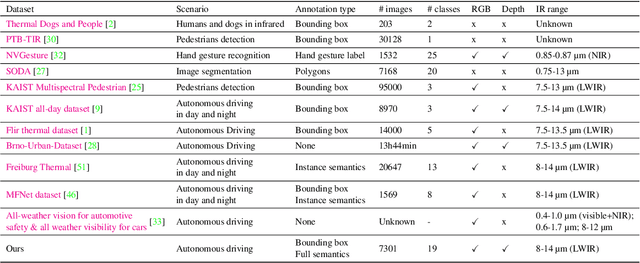

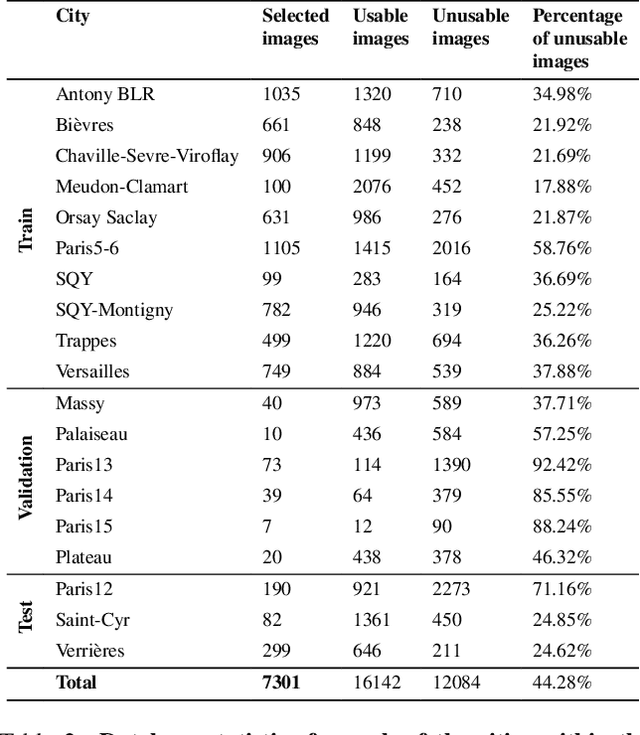
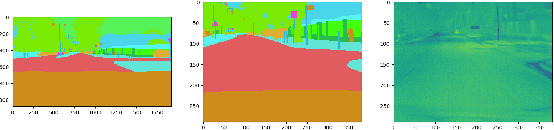
Current deep neural networks (DNNs) for autonomous driving computer vision are typically trained on specific datasets that only involve a single type of data and urban scenes. Consequently, these models struggle to handle new objects, noise, nighttime conditions, and diverse scenarios, which is essential for safety-critical applications. Despite ongoing efforts to enhance the resilience of computer vision DNNs, progress has been sluggish, partly due to the absence of benchmarks featuring multiple modalities. We introduce a novel and versatile dataset named InfraParis that supports multiple tasks across three modalities: RGB, depth, and infrared. We assess various state-of-the-art baseline techniques, encompassing models for the tasks of semantic segmentation, object detection, and depth estimation.
VIBR: Learning View-Invariant Value Functions for Robust Visual Control
Jun 14, 2023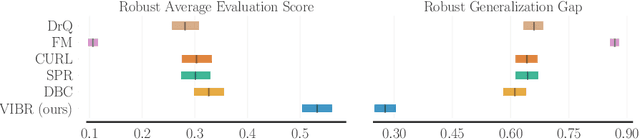
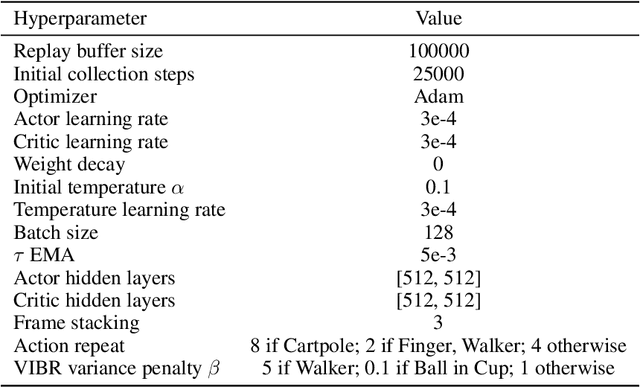
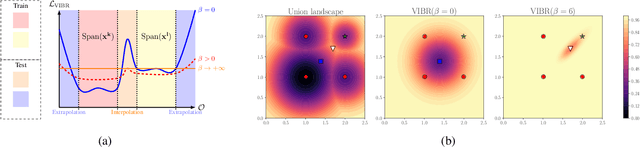
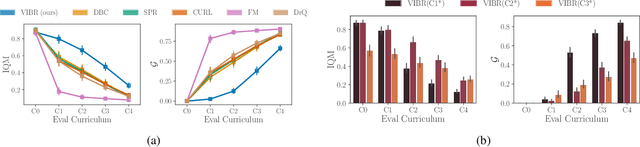
End-to-end reinforcement learning on images showed significant progress in the recent years. Data-based approach leverage data augmentation and domain randomization while representation learning methods use auxiliary losses to learn task-relevant features. Yet, reinforcement still struggles in visually diverse environments full of distractions and spurious noise. In this work, we tackle the problem of robust visual control at its core and present VIBR (View-Invariant Bellman Residuals), a method that combines multi-view training and invariant prediction to reduce out-of-distribution (OOD) generalization gap for RL based visuomotor control. Our model-free approach improve baselines performances without the need of additional representation learning objectives and with limited additional computational cost. We show that VIBR outperforms existing methods on complex visuo-motor control environment with high visual perturbation. Our approach achieves state-of the-art results on the Distracting Control Suite benchmark, a challenging benchmark still not solved by current methods, where we evaluate the robustness to a number of visual perturbators, as well as OOD generalization and extrapolation capabilities.
Latent Discriminant deterministic Uncertainty
Jul 20, 2022
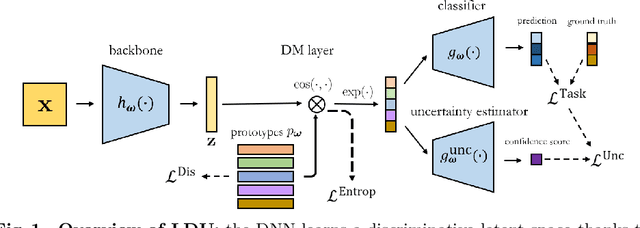
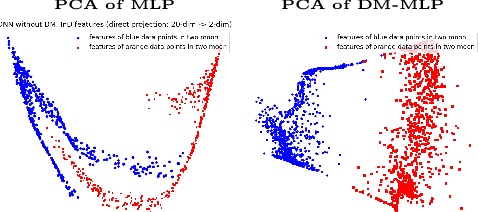
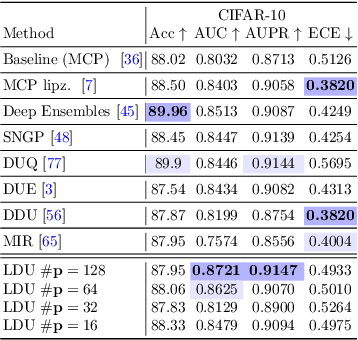
Predictive uncertainty estimation is essential for deploying Deep Neural Networks in real-world autonomous systems. However, most successful approaches are computationally intensive. In this work, we attempt to address these challenges in the context of autonomous driving perception tasks. Recently proposed Deterministic Uncertainty Methods (DUM) can only partially meet such requirements as their scalability to complex computer vision tasks is not obvious. In this work we advance a scalable and effective DUM for high-resolution semantic segmentation, that relaxes the Lipschitz constraint typically hindering practicality of such architectures. We learn a discriminant latent space by leveraging a distinction maximization layer over an arbitrarily-sized set of trainable prototypes. Our approach achieves competitive results over Deep Ensembles, the state-of-the-art for uncertainty prediction, on image classification, segmentation and monocular depth estimation tasks. Our code is available at https://github.com/ENSTA-U2IS/LDU
MUAD: Multiple Uncertainties for Autonomous Driving benchmark for multiple uncertainty types and tasks
Mar 02, 2022
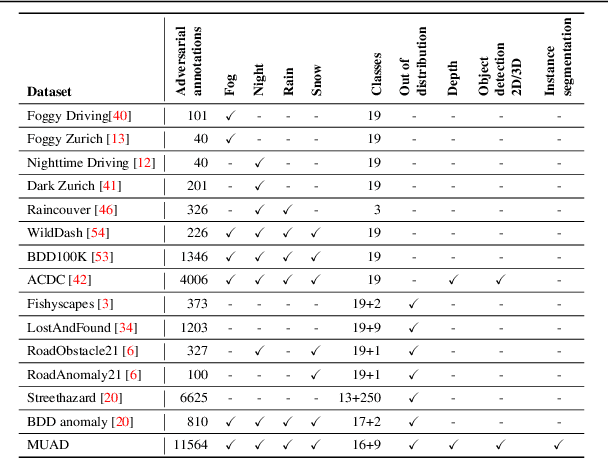
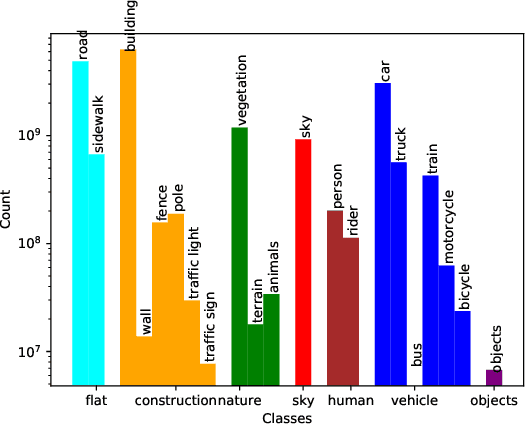
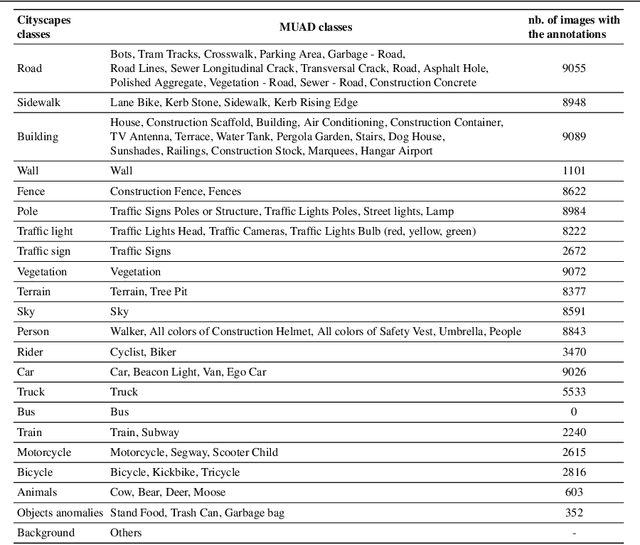
Predictive uncertainty estimation is essential for deploying Deep Neural Networks in real-world autonomous systems. However, disentangling the different types and sources of uncertainty is non trivial in most datasets, especially since there is no ground truth for uncertainty. In addition, different degrees of weather conditions can disrupt neural networks, resulting in inconsistent training data quality. Thus, we introduce the MUAD dataset (Multiple Uncertainties for Autonomous Driving), consisting of 8,500 realistic synthetic images with diverse adverse weather conditions (night, fog, rain, snow), out-of-distribution objects and annotations for semantic segmentation, depth estimation, object and instance detection. MUAD allows to better assess the impact of different sources of uncertainty on model performance. We propose a study that shows the importance of having reliable Deep Neural Networks (DNNs) in multiple experiments, and will release our dataset to allow researchers to benchmark their algorithm methodically in ad-verse conditions. More information and the download link for MUAD are available at https://muad-dataset.github.io/ .