 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFoundation Models Meet Low-Cost Sensors: Test-Time Adaptation for Rescaling Disparity for Zero-Shot Metric Depth Estimation
Dec 18, 2024



The recent development of foundation models for monocular depth estimation such as Depth Anything paved the way to zero-shot monocular depth estimation. Since it returns an affine-invariant disparity map, the favored technique to recover the metric depth consists in fine-tuning the model. However, this stage is costly to perform because of the training but also due to the creation of the dataset. It must contain images captured by the camera that will be used at test time and the corresponding ground truth. Moreover, the fine-tuning may also degrade the generalizing capacity of the original model. Instead, we propose in this paper a new method to rescale Depth Anything predictions using 3D points provided by low-cost sensors or techniques such as low-resolution LiDAR, stereo camera, structure-from-motion where poses are given by an IMU. Thus, this approach avoids fine-tuning and preserves the generalizing power of the original depth estimation model while being robust to the noise of the sensor or of the depth model. Our experiments highlight improvements relative to other metric depth estimation methods and competitive results compared to fine-tuned approaches. Code available at https://gitlab.ensta.fr/ssh/monocular-depth-rescaling.
Automatic Image Annotation for Mapped Features Detection
Dec 11, 2024
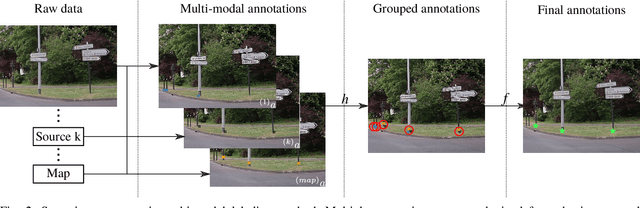

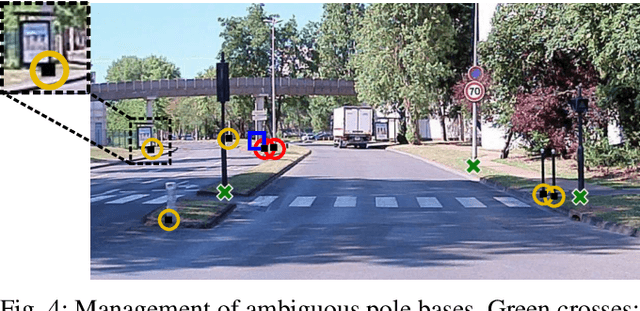
Detecting road features is a key enabler for autonomous driving and localization. For instance, a reliable detection of poles which are widespread in road environments can improve localization. Modern deep learning-based perception systems need a significant amount of annotated data. Automatic annotation avoids time-consuming and costly manual annotation. Because automatic methods are prone to errors, managing annotation uncertainty is crucial to ensure a proper learning process. Fusing multiple annotation sources on the same dataset can be an efficient way to reduce the errors. This not only improves the quality of annotations, but also improves the learning of perception models. In this paper, we consider the fusion of three automatic annotation methods in images: feature projection from a high accuracy vector map combined with a lidar, image segmentation and lidar segmentation. Our experimental results demonstrate the significant benefits of multi-modal automatic annotation for pole detection through a comparative evaluation on manually annotated images. Finally, the resulting multi-modal fusion is used to fine-tune an object detection model for pole base detection using unlabeled data, showing overall improvements achieved by enhancing network specialization. The dataset is publicly available.
Pole-based Vehicle Localization with Vector Maps: A Camera-LiDAR Comparative Study
Dec 11, 2024



For autonomous navigation, accurate localization with respect to a map is needed. In urban environments, infrastructure such as buildings or bridges cause major difficulties to Global Navigation Satellite Systems (GNSS) and, despite advances in inertial navigation, it is necessary to support them with other sources of exteroceptive information. In road environments, many common furniture such as traffic signs, traffic lights and street lights take the form of poles. By georeferencing these features in vector maps, they can be used within a localization filter that includes a detection pipeline and a data association method. Poles, having discriminative vertical structures, can be extracted from 3D geometric information using LiDAR sensors. Alternatively, deep neural networks can be employed to detect them from monocular cameras. The lack of depth information induces challenges in associating camera detections with map features. Yet, multi-camera integration provides a cost-efficient solution. This paper quantitatively evaluates the efficacy of these approaches in terms of localization. It introduces a real-time method for camera-based pole detection using a lightweight neural network trained on automatically annotated images. The proposed methods' efficiency is assessed on a challenging sequence with a vector map. The results highlight the high accuracy of the vision-based approach in open road conditions.
Map-aided annotation for pole base detection
Mar 04, 2024For autonomous navigation, high definition maps are a widely used source of information. Pole-like features encoded in HD maps such as traffic signs, traffic lights or street lights can be used as landmarks for localization. For this purpose, they first need to be detected by the vehicle using its embedded sensors. While geometric models can be used to process 3D point clouds retrieved by lidar sensors, modern image-based approaches rely on deep neural network and therefore heavily depend on annotated training data. In this paper, a 2D HD map is used to automatically annotate pole-like features in images. In the absence of height information, the map features are represented as pole bases at the ground level. We show how an additional lidar sensor can be used to filter out occluded features and refine the ground projection. We also demonstrate how an object detector can be trained to detect a pole base. To evaluate our methodology, it is first validated with data manually annotated from semantic segmentation and then compared to our own automatically generated annotated data recorded in the city of Compi{\`e}gne, France. Erratum: In the original version [1], an error occurred in the accuracy evaluation of the different models studied and the evaluation method applied on the detection results was not clearly defined. In this revision, we offer a rectification to this segment, presenting updated results, especially in terms of Mean Absolute Errors (MAE).
Collaborative Grid Mapping for Moving Object Tracking Evaluation
Nov 17, 2023
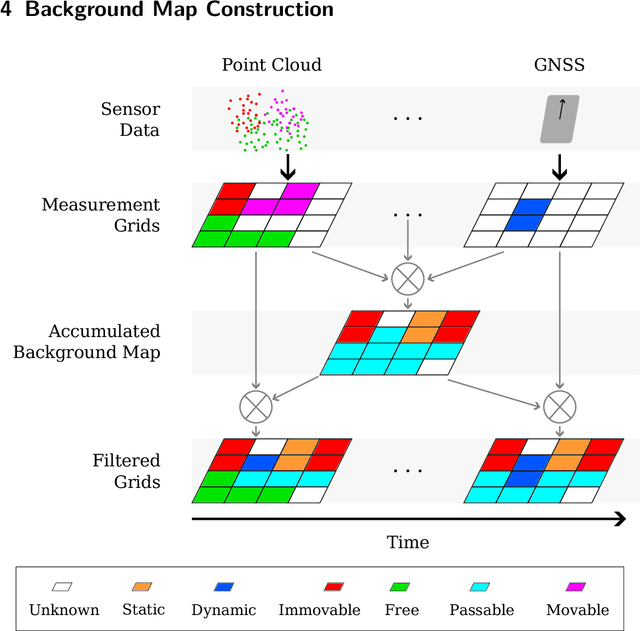


Perception of other road users is a crucial task for intelligent vehicles. Perception systems can use on-board sensors only or be in cooperation with other vehicles or with roadside units. In any case, the performance of perception systems has to be evaluated against ground-truth data, which is a particularly tedious task and requires numerous manual operations. In this article, we propose a novel semi-automatic method for pseudo ground-truth estimation. The principle consists in carrying out experiments with several vehicles equipped with LiDAR sensors and with fixed perception systems located at the roadside in order to collaboratively build reference dynamic data. The method is based on grid mapping and in particular on the elaboration of a background map that holds relevant information that remains valid during a whole dataset sequence. Data from all agents is converted in time-stamped observations grids. A data fusion method that manages uncertainties combines the background map with observations to produce dynamic reference information at each instant. Several datasets have been acquired with three experimental vehicles and a roadside unit. An evaluation of this method is finally provided in comparison to a handmade ground truth.
Lane level context and hidden space characterization for autonomous driving
Aug 31, 2021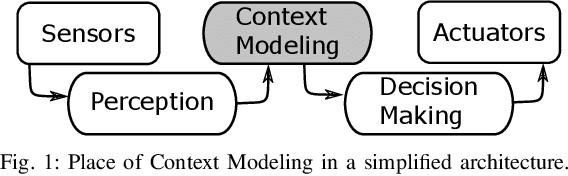

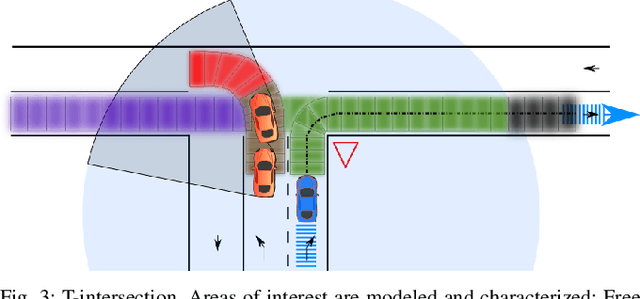
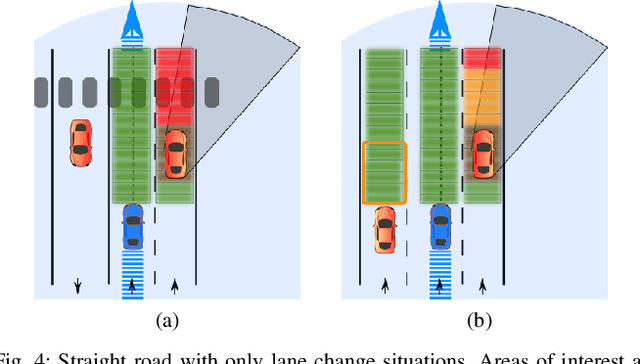
For an autonomous vehicle, situation understand-ing is a key capability towards safe and comfortable decision-making and navigation. Information is in general provided bymultiple sources. Prior information about the road topology andtraffic laws can be given by a High Definition (HD) map whilethe perception system provides the description of the spaceand of road entities evolving in the vehicle surroundings. Incomplex situations such as those encountered in urban areas,the road user behaviors are governed by strong interactionswith the others, and with the road network. In such situations,reliable situation understanding is therefore mandatory to avoidinappropriate decisions. Nevertheless, situation understandingis a complex task that requires access to a consistent andnon-misleading representation of the vehicle surroundings. Thispaper proposes a formalism (an interaction lane grid) whichallows to represent, with different levels of abstraction, thenavigable and interacting spaces which must be considered forsafe navigation. A top-down approach is chosen to assess andcharacterize the relevant information of the situation. On a highlevel of abstraction, the identification of the areas of interestwhere the vehicle should pay attention is depicted. On a lowerlevel, it enables to characterize the spatial information in aunified representation and to infer additional information inoccluded areas by reasoning with dynamic objects.
Fusion of evidential CNN classifiers for image classification
Aug 23, 2021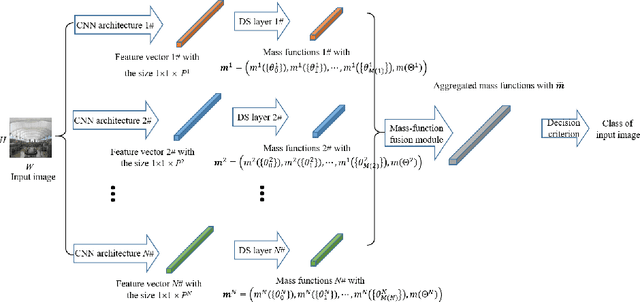


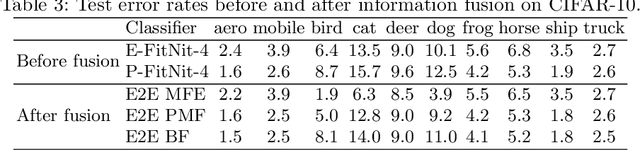
We propose an information-fusion approach based on belief functions to combine convolutional neural networks. In this approach, several pre-trained DS-based CNN architectures extract features from input images and convert them into mass functions on different frames of discernment. A fusion module then aggregates these mass functions using Dempster's rule. An end-to-end learning procedure allows us to fine-tune the overall architecture using a learning set with soft labels, which further improves the classification performance. The effectiveness of this approach is demonstrated experimentally using three benchmark databases.
An evidential classifier based on Dempster-Shafer theory and deep learning
Mar 25, 2021


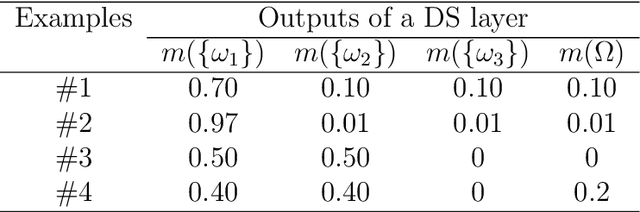
We propose a new classifier based on Dempster-Shafer (DS) theory and a convolutional neural network (CNN) architecture for set-valued classification. In this classifier, called the evidential deep-learning classifier, convolutional and pooling layers first extract high-dimensional features from input data. The features are then converted into mass functions and aggregated by Dempster's rule in a DS layer. Finally, an expected utility layer performs set-valued classification based on mass functions. We propose an end-to-end learning strategy for jointly updating the network parameters. Additionally, an approach for selecting partial multi-class acts is proposed. Experiments on image recognition, signal processing, and semantic-relationship classification tasks demonstrate that the proposed combination of deep CNN, DS layer, and expected utility layer makes it possible to improve classification accuracy and to make cautious decisions by assigning confusing patterns to multi-class sets.
Evidential fully convolutional network for semantic segmentation
Mar 25, 2021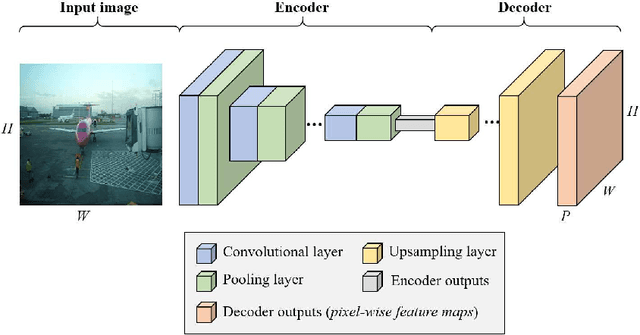

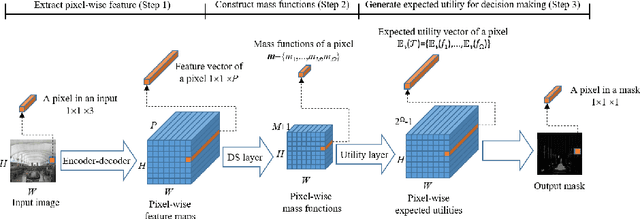

We propose a hybrid architecture composed of a fully convolutional network (FCN) and a Dempster-Shafer layer for image semantic segmentation. In the so-called evidential FCN (E-FCN), an encoder-decoder architecture first extracts pixel-wise feature maps from an input image. A Dempster-Shafer layer then computes mass functions at each pixel location based on distances to prototypes. Finally, a utility layer performs semantic segmentation from mass functions and allows for imprecise classification of ambiguous pixels and outliers. We propose an end-to-end learning strategy for jointly updating the network parameters, which can make use of soft (imprecise) labels. Experiments using three databases (Pascal VOC 2011, MIT-scene Parsing and SIFT Flow) show that the proposed combination improves the accuracy and calibration of semantic segmentation by assigning confusing pixels to multi-class sets.