 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePole-based Vehicle Localization with Vector Maps: A Camera-LiDAR Comparative Study
Dec 11, 2024For autonomous navigation, accurate localization with respect to a map is needed. In urban environments, infrastructure such as buildings or bridges cause major difficulties to Global Navigation Satellite Systems (GNSS) and, despite advances in inertial navigation, it is necessary to support them with other sources of exteroceptive information. In road environments, many common furniture such as traffic signs, traffic lights and street lights take the form of poles. By georeferencing these features in vector maps, they can be used within a localization filter that includes a detection pipeline and a data association method. Poles, having discriminative vertical structures, can be extracted from 3D geometric information using LiDAR sensors. Alternatively, deep neural networks can be employed to detect them from monocular cameras. The lack of depth information induces challenges in associating camera detections with map features. Yet, multi-camera integration provides a cost-efficient solution. This paper quantitatively evaluates the efficacy of these approaches in terms of localization. It introduces a real-time method for camera-based pole detection using a lightweight neural network trained on automatically annotated images. The proposed methods' efficiency is assessed on a challenging sequence with a vector map. The results highlight the high accuracy of the vision-based approach in open road conditions.
Automatic Image Annotation for Mapped Features Detection
Dec 11, 2024
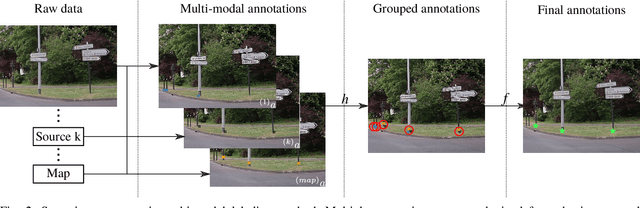

Detecting road features is a key enabler for autonomous driving and localization. For instance, a reliable detection of poles which are widespread in road environments can improve localization. Modern deep learning-based perception systems need a significant amount of annotated data. Automatic annotation avoids time-consuming and costly manual annotation. Because automatic methods are prone to errors, managing annotation uncertainty is crucial to ensure a proper learning process. Fusing multiple annotation sources on the same dataset can be an efficient way to reduce the errors. This not only improves the quality of annotations, but also improves the learning of perception models. In this paper, we consider the fusion of three automatic annotation methods in images: feature projection from a high accuracy vector map combined with a lidar, image segmentation and lidar segmentation. Our experimental results demonstrate the significant benefits of multi-modal automatic annotation for pole detection through a comparative evaluation on manually annotated images. Finally, the resulting multi-modal fusion is used to fine-tune an object detection model for pole base detection using unlabeled data, showing overall improvements achieved by enhancing network specialization. The dataset is publicly available.
Map-aided annotation for pole base detection
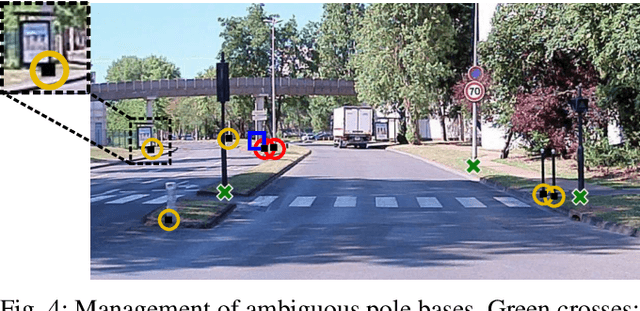
Mar 04, 2024For autonomous navigation, high definition maps are a widely used source of information. Pole-like features encoded in HD maps such as traffic signs, traffic lights or street lights can be used as landmarks for localization. For this purpose, they first need to be detected by the vehicle using its embedded sensors. While geometric models can be used to process 3D point clouds retrieved by lidar sensors, modern image-based approaches rely on deep neural network and therefore heavily depend on annotated training data. In this paper, a 2D HD map is used to automatically annotate pole-like features in images. In the absence of height information, the map features are represented as pole bases at the ground level. We show how an additional lidar sensor can be used to filter out occluded features and refine the ground projection. We also demonstrate how an object detector can be trained to detect a pole base. To evaluate our methodology, it is first validated with data manually annotated from semantic segmentation and then compared to our own automatically generated annotated data recorded in the city of Compi{\`e}gne, France. Erratum: In the original version [1], an error occurred in the accuracy evaluation of the different models studied and the evaluation method applied on the detection results was not clearly defined. In this revision, we offer a rectification to this segment, presenting updated results, especially in terms of Mean Absolute Errors (MAE).