 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBEV-SUSHI: Multi-Target Multi-Camera 3D Detection and Tracking in Bird's-Eye View
Dec 01, 2024



Object perception from multi-view cameras is crucial for intelligent systems, particularly in indoor environments, e.g., warehouses, retail stores, and hospitals. Most traditional multi-target multi-camera (MTMC) detection and tracking methods rely on 2D object detection, single-view multi-object tracking (MOT), and cross-view re-identification (ReID) techniques, without properly handling important 3D information by multi-view image aggregation. In this paper, we propose a 3D object detection and tracking framework, named BEV-SUSHI, which first aggregates multi-view images with necessary camera calibration parameters to obtain 3D object detections in bird's-eye view (BEV). Then, we introduce hierarchical graph neural networks (GNNs) to track these 3D detections in BEV for MTMC tracking results. Unlike existing methods, BEV-SUSHI has impressive generalizability across different scenes and diverse camera settings, with exceptional capability for long-term association handling. As a result, our proposed BEV-SUSHI establishes the new state-of-the-art on the AICity'24 dataset with 81.22 HOTA, and 95.6 IDF1 on the WildTrack dataset.
Hyperspectral Neural Radiance Fields
Mar 21, 2024Hyperspectral Imagery (HSI) has been used in many applications to non-destructively determine the material and/or chemical compositions of samples. There is growing interest in creating 3D hyperspectral reconstructions, which could provide both spatial and spectral information while also mitigating common HSI challenges such as non-Lambertian surfaces and translucent objects. However, traditional 3D reconstruction with HSI is difficult due to technological limitations of hyperspectral cameras. In recent years, Neural Radiance Fields (NeRFs) have seen widespread success in creating high quality volumetric 3D representations of scenes captured by a variety of camera models. Leveraging recent advances in NeRFs, we propose computing a hyperspectral 3D reconstruction in which every point in space and view direction is characterized by wavelength-dependent radiance and transmittance spectra. To evaluate our approach, a dataset containing nearly 2000 hyperspectral images across 8 scenes and 2 cameras was collected. We perform comparisons against traditional RGB NeRF baselines and apply ablation testing with alternative spectra representations. Finally, we demonstrate the potential of hyperspectral NeRFs for hyperspectral super-resolution and imaging sensor simulation. We show that our hyperspectral NeRF approach enables creating fast, accurate volumetric 3D hyperspectral scenes and enables several new applications and areas for future study.
Map-aided annotation for pole base detection
Mar 04, 2024For autonomous navigation, high definition maps are a widely used source of information. Pole-like features encoded in HD maps such as traffic signs, traffic lights or street lights can be used as landmarks for localization. For this purpose, they first need to be detected by the vehicle using its embedded sensors. While geometric models can be used to process 3D point clouds retrieved by lidar sensors, modern image-based approaches rely on deep neural network and therefore heavily depend on annotated training data. In this paper, a 2D HD map is used to automatically annotate pole-like features in images. In the absence of height information, the map features are represented as pole bases at the ground level. We show how an additional lidar sensor can be used to filter out occluded features and refine the ground projection. We also demonstrate how an object detector can be trained to detect a pole base. To evaluate our methodology, it is first validated with data manually annotated from semantic segmentation and then compared to our own automatically generated annotated data recorded in the city of Compi{\`e}gne, France. Erratum: In the original version [1], an error occurred in the accuracy evaluation of the different models studied and the evaluation method applied on the detection results was not clearly defined. In this revision, we offer a rectification to this segment, presenting updated results, especially in terms of Mean Absolute Errors (MAE).
SAMCLR: Contrastive pre-training on complex scenes using SAM for view sampling
Oct 29, 2023



In Computer Vision, self-supervised contrastive learning enforces similar representations between different views of the same image. The pre-training is most often performed on image classification datasets, like ImageNet, where images mainly contain a single class of objects. However, when dealing with complex scenes with multiple items, it becomes very unlikely for several views of the same image to represent the same object category. In this setting, we propose SAMCLR, an add-on to SimCLR which uses SAM to segment the image into semantic regions, then sample the two views from the same region. Preliminary results show empirically that when pre-training on Cityscapes and ADE20K, then evaluating on classification on CIFAR-10, STL10 and ImageNette, SAMCLR performs at least on par with, and most often significantly outperforms not only SimCLR, but also DINO and MoCo.
Data refinement for fully unsupervised visual inspection using pre-trained networks
Feb 25, 2022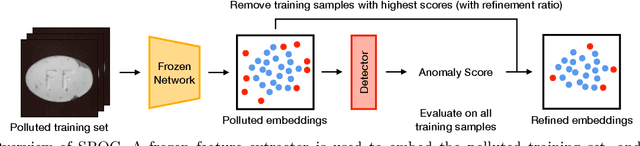
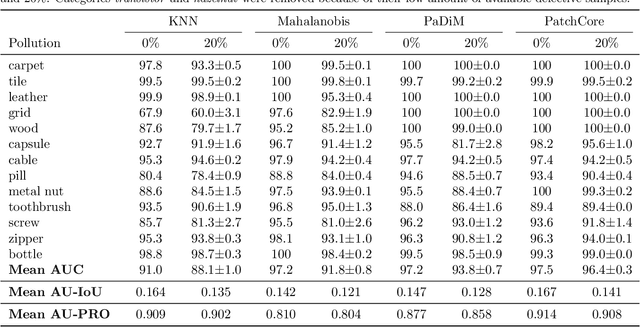
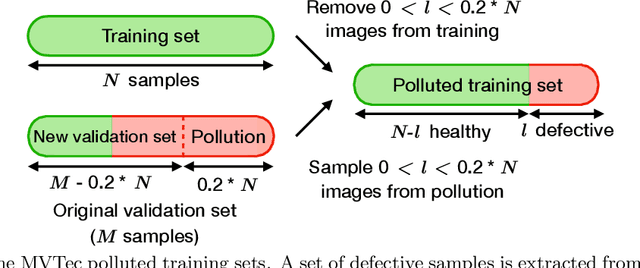
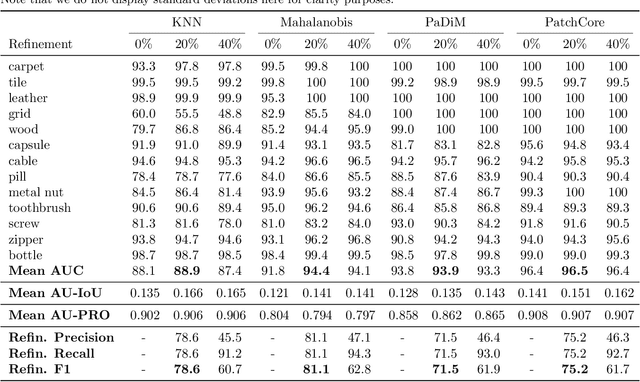
Anomaly detection has recently seen great progress in the field of visual inspection. More specifically, the use of classical outlier detection techniques on features extracted by deep pre-trained neural networks have been shown to deliver remarkable performances on the MVTec Anomaly Detection (MVTec AD) dataset. However, like most other anomaly detection strategies, these pre-trained methods assume all training data to be normal. As a consequence, they cannot be considered as fully unsupervised. There exists to our knowledge no work studying these pre-trained methods under fully unsupervised setting. In this work, we first assess the robustness of these pre-trained methods to fully unsupervised context, using polluted training sets (i.e. containing defective samples), and show that these methods are more robust to pollution compared to methods such as CutPaste. We then propose SROC, a Simple Refinement strategy for One Class classification. SROC enables to remove most of the polluted images from the training set, and to recover some of the lost AUC. We further show that our simple heuristic competes with, and even outperforms much more complex strategies from the existing literature.