 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving generalization with synthetic training data for deep learning based quality inspection
Feb 25, 2022
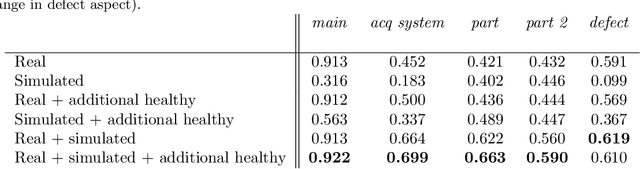


Automating quality inspection with computer vision techniques is often a very data-demanding task. Specifically, supervised deep learning requires a large amount of annotated images for training. In practice, collecting and annotating such data is not only costly and laborious, but also inefficient, given the fact that only a few instances may be available for certain defect classes. If working with video frames can increase the number of these instances, it has a major disadvantage: the resulting images will be highly correlated with one another. As a consequence, models trained under such constraints are expected to be very sensitive to input distribution changes, which may be caused in practice by changes in the acquisition system (cameras, lights), in the parts or in the defects aspect. In this work, we demonstrate the use of randomly generated synthetic training images can help tackle domain instability issues, making the trained models more robust to contextual changes. We detail both our synthetic data generation pipeline and our deep learning methodology for answering these questions.
Data refinement for fully unsupervised visual inspection using pre-trained networks
Feb 25, 2022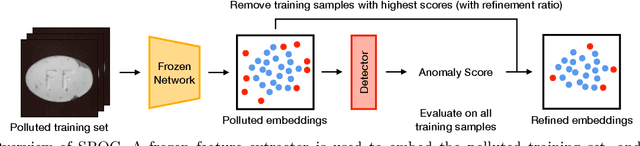
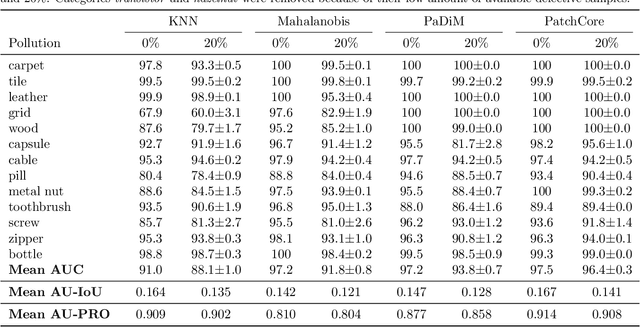
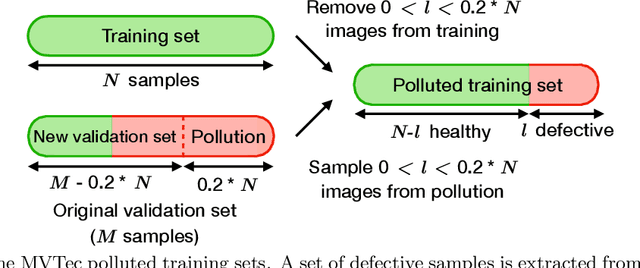
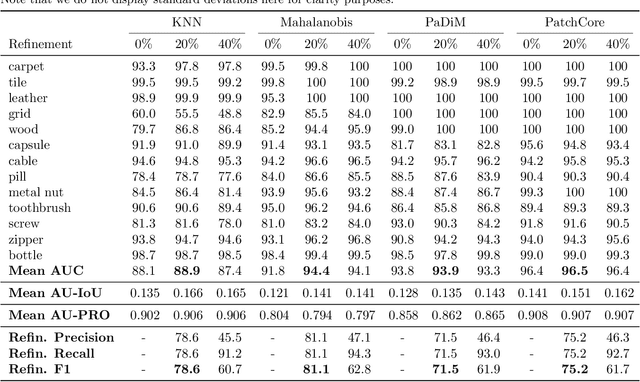
Anomaly detection has recently seen great progress in the field of visual inspection. More specifically, the use of classical outlier detection techniques on features extracted by deep pre-trained neural networks have been shown to deliver remarkable performances on the MVTec Anomaly Detection (MVTec AD) dataset. However, like most other anomaly detection strategies, these pre-trained methods assume all training data to be normal. As a consequence, they cannot be considered as fully unsupervised. There exists to our knowledge no work studying these pre-trained methods under fully unsupervised setting. In this work, we first assess the robustness of these pre-trained methods to fully unsupervised context, using polluted training sets (i.e. containing defective samples), and show that these methods are more robust to pollution compared to methods such as CutPaste. We then propose SROC, a Simple Refinement strategy for One Class classification. SROC enables to remove most of the polluted images from the training set, and to recover some of the lost AUC. We further show that our simple heuristic competes with, and even outperforms much more complex strategies from the existing literature.
Data augmentation and pre-trained networks for extremely low data regimes unsupervised visual inspection
Jun 02, 2021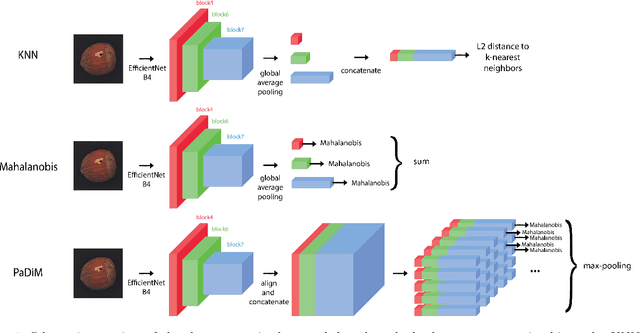
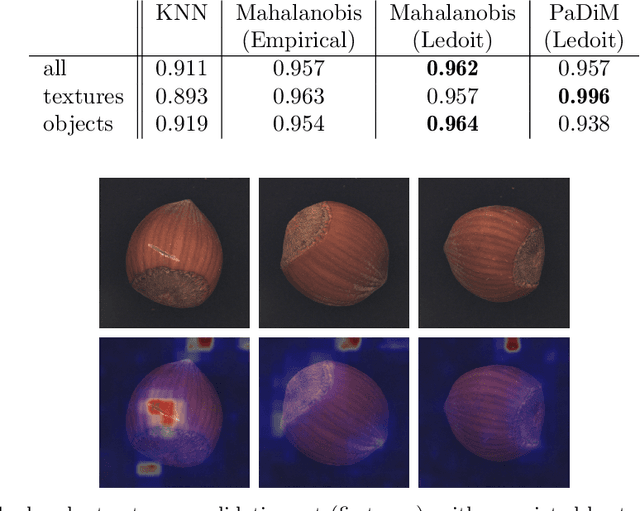
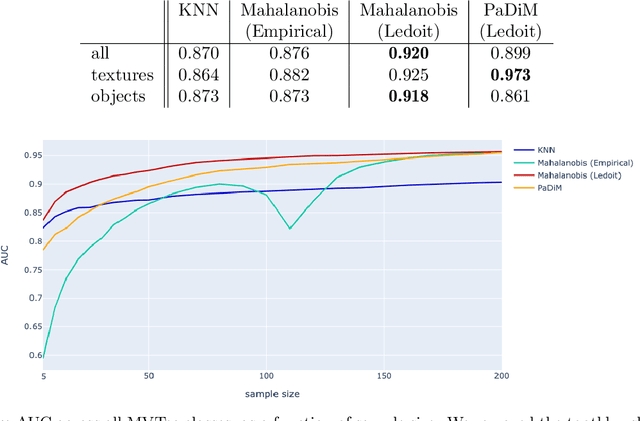
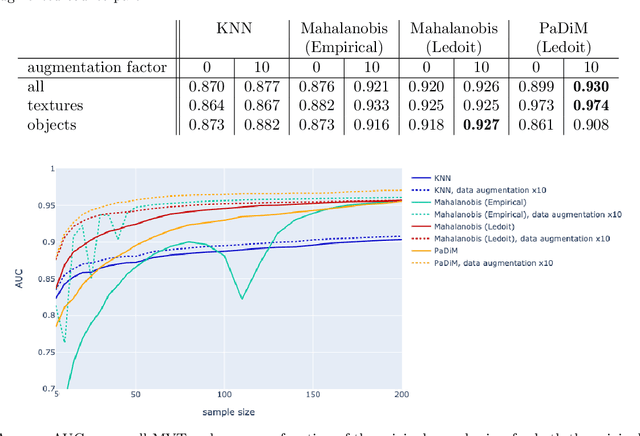
The use of deep features coming from pre-trained neural networks for unsupervised anomaly detection purposes has recently gathered momentum in the computer vision field. In particular, industrial inspection applications can take advantage of such features, as demonstrated by the multiple successes of related methods on the MVTec Anomaly Detection (MVTec AD) dataset. These methods make use of neural networks pre-trained on auxiliary classification tasks such as ImageNet. However, to our knowledge, no comparative study of robustness to the low data regimes between these approaches has been conducted yet. For quality inspection applications, the handling of limited sample sizes may be crucial as large quantities of images are not available for small series. In this work, we aim to compare three approaches based on deep pre-trained features when varying the quantity of available data in MVTec AD: KNN, Mahalanobis, and PaDiM. We show that although these methods are mostly robust to small sample sizes, they still can benefit greatly from using data augmentation in the original image space, which allows to deal with very small production runs.
Synthetic training data generation for deep learning based quality inspection
Apr 07, 2021
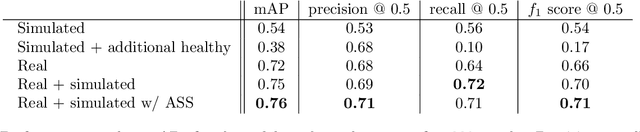


Deep learning is now the gold standard in computer vision-based quality inspection systems. In order to detect defects, supervised learning is often utilized, but necessitates a large amount of annotated images, which can be costly: collecting, cleaning, and annotating the data is tedious and limits the speed at which a system can be deployed as everything the system must detect needs to be observed first. This can impede the inspection of rare defects, since very few samples can be collected by the manufacturer. In this work, we focus on simulations to solve this issue. We first present a generic simulation pipeline to render images of defective or healthy (non defective) parts. As metallic parts can be highly textured with small defects like holes, we design a texture scanning and generation method. We assess the quality of the generated images by training deep learning networks and by testing them on real data from a manufacturer. We demonstrate that we can achieve encouraging results on real defect detection using purely simulated data. Additionally, we are able to improve global performances by concatenating simulated and real data, showing that simulations can complement real images to boost performances. Lastly, using domain adaptation techniques helps improving slightly our final results.
Active learning using weakly supervised signals for quality inspection
Apr 07, 2021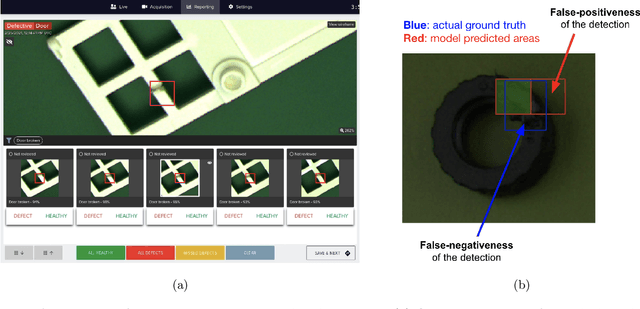

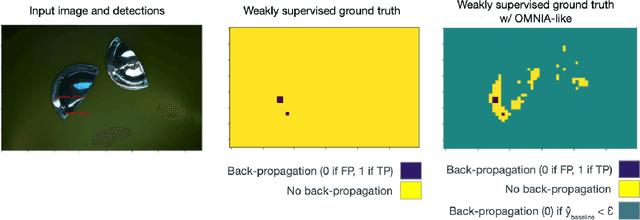
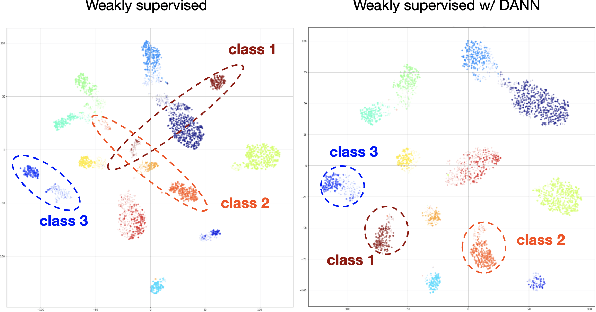
Because manufacturing processes evolve fast, and since production visual aspect can vary significantly on a daily basis, the ability to rapidly update machine vision based inspection systems is paramount. Unfortunately, supervised learning of convolutional neural networks requires a significant amount of annotated images for being able to learn effectively from new data. Acknowledging the abundance of continuously generated images coming from the production line and the cost of their annotation, we demonstrate it is possible to prioritize and accelerate the annotation process. In this work, we develop a methodology for learning actively, from rapidly mined, weakly (i.e. partially) annotated data, enabling a fast, direct feedback from the operators on the production line and tackling a big machine vision weakness: false positives. We also consider the problem of covariate shift, which arises inevitably due to changing conditions during data acquisition. In that regard, we show domain-adversarial training to be an efficient way to address this issue.
Dataiku's Solution to SPHERE's Activity Recognition Challenge
Oct 10, 2016
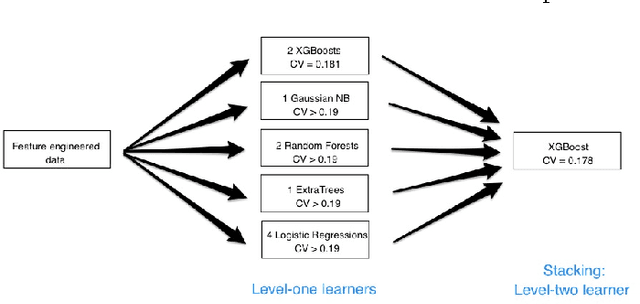
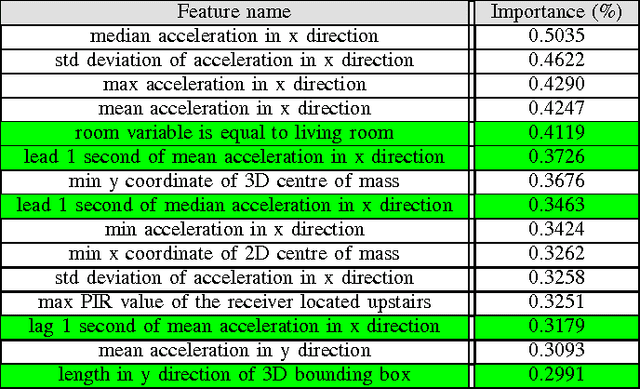
Our team won the second prize of the Safe Aging with SPHERE Challenge organized by SPHERE, in conjunction with ECML-PKDD and Driven Data. The goal of the competition was to recognize activities performed by humans, using sensor data. This paper presents our solution. It is based on a rich pre-processing and state of the art machine learning methods. From the raw train data, we generate a synthetic train set with the same statistical characteristics as the test set. We then perform feature engineering. The machine learning modeling part is based on stacking weak learners through a grid searched XGBoost algorithm. Finally, we use post-processing to smooth our predictions over time.