 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving generalization with synthetic training data for deep learning based quality inspection
Paper and Code
Feb 25, 2022
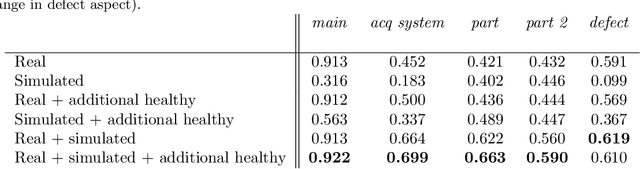


Automating quality inspection with computer vision techniques is often a very data-demanding task. Specifically, supervised deep learning requires a large amount of annotated images for training. In practice, collecting and annotating such data is not only costly and laborious, but also inefficient, given the fact that only a few instances may be available for certain defect classes. If working with video frames can increase the number of these instances, it has a major disadvantage: the resulting images will be highly correlated with one another. As a consequence, models trained under such constraints are expected to be very sensitive to input distribution changes, which may be caused in practice by changes in the acquisition system (cameras, lights), in the parts or in the defects aspect. In this work, we demonstrate the use of randomly generated synthetic training images can help tackle domain instability issues, making the trained models more robust to contextual changes. We detail both our synthetic data generation pipeline and our deep learning methodology for answering these questions.