 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Learning to Complete Anything in Lidar
Apr 16, 2025We propose CAL (Complete Anything in Lidar) for Lidar-based shape-completion in-the-wild. This is closely related to Lidar-based semantic/panoptic scene completion. However, contemporary methods can only complete and recognize objects from a closed vocabulary labeled in existing Lidar datasets. Different to that, our zero-shot approach leverages the temporal context from multi-modal sensor sequences to mine object shapes and semantic features of observed objects. These are then distilled into a Lidar-only instance-level completion and recognition model. Although we only mine partial shape completions, we find that our distilled model learns to infer full object shapes from multiple such partial observations across the dataset. We show that our model can be prompted on standard benchmarks for Semantic and Panoptic Scene Completion, localize objects as (amodal) 3D bounding boxes, and recognize objects beyond fixed class vocabularies. Our project page is https://research.nvidia.com/labs/dvl/projects/complete-anything-lidar
Zero-Shot 4D Lidar Panoptic Segmentation
Apr 01, 2025Zero-shot 4D segmentation and recognition of arbitrary objects in Lidar is crucial for embodied navigation, with applications ranging from streaming perception to semantic mapping and localization. However, the primary challenge in advancing research and developing generalized, versatile methods for spatio-temporal scene understanding in Lidar lies in the scarcity of datasets that provide the necessary diversity and scale of annotations.To overcome these challenges, we propose SAL-4D (Segment Anything in Lidar--4D), a method that utilizes multi-modal robotic sensor setups as a bridge to distill recent developments in Video Object Segmentation (VOS) in conjunction with off-the-shelf Vision-Language foundation models to Lidar. We utilize VOS models to pseudo-label tracklets in short video sequences, annotate these tracklets with sequence-level CLIP tokens, and lift them to the 4D Lidar space using calibrated multi-modal sensory setups to distill them to our SAL-4D model. Due to temporal consistent predictions, we outperform prior art in 3D Zero-Shot Lidar Panoptic Segmentation (LPS) over $5$ PQ, and unlock Zero-Shot 4D-LPS.
BEV-SUSHI: Multi-Target Multi-Camera 3D Detection and Tracking in Bird's-Eye View
Dec 01, 2024



Object perception from multi-view cameras is crucial for intelligent systems, particularly in indoor environments, e.g., warehouses, retail stores, and hospitals. Most traditional multi-target multi-camera (MTMC) detection and tracking methods rely on 2D object detection, single-view multi-object tracking (MOT), and cross-view re-identification (ReID) techniques, without properly handling important 3D information by multi-view image aggregation. In this paper, we propose a 3D object detection and tracking framework, named BEV-SUSHI, which first aggregates multi-view images with necessary camera calibration parameters to obtain 3D object detections in bird's-eye view (BEV). Then, we introduce hierarchical graph neural networks (GNNs) to track these 3D detections in BEV for MTMC tracking results. Unlike existing methods, BEV-SUSHI has impressive generalizability across different scenes and diverse camera settings, with exceptional capability for long-term association handling. As a result, our proposed BEV-SUSHI establishes the new state-of-the-art on the AICity'24 dataset with 81.22 HOTA, and 95.6 IDF1 on the WildTrack dataset.
SPAMming Labels: Efficient Annotations for the Trackers of Tomorrow
Apr 17, 2024Increasing the annotation efficiency of trajectory annotations from videos has the potential to enable the next generation of data-hungry tracking algorithms to thrive on large-scale datasets. Despite the importance of this task, there are currently very few works exploring how to efficiently label tracking datasets comprehensively. In this work, we introduce SPAM, a tracking data engine that provides high-quality labels with minimal human intervention. SPAM is built around two key insights: i) most tracking scenarios can be easily resolved. To take advantage of this, we utilize a pre-trained model to generate high-quality pseudo-labels, reserving human involvement for a smaller subset of more difficult instances; ii) handling the spatiotemporal dependencies of track annotations across time can be elegantly and efficiently formulated through graphs. Therefore, we use a unified graph formulation to address the annotation of both detections and identity association for tracks across time. Based on these insights, SPAM produces high-quality annotations with a fraction of ground truth labeling cost. We demonstrate that trackers trained on SPAM labels achieve comparable performance to those trained on human annotations while requiring only 3-20% of the human labeling effort. Hence, SPAM paves the way towards highly efficient labeling of large-scale tracking datasets. Our code and models will be available upon acceptance.
Better Call SAL: Towards Learning to Segment Anything in Lidar
Mar 19, 2024



We propose $\texttt{SAL}$ ($\texttt{S}$egment $\texttt{A}$nything in $\texttt{L}$idar) method consisting of a text-promptable zero-shot model for segmenting and classifying any object in Lidar, and a pseudo-labeling engine that facilitates model training without manual supervision. While the established paradigm for $\textit{Lidar Panoptic Segmentation}$ (LPS) relies on manual supervision for a handful of object classes defined a priori, we utilize 2D vision foundation models to generate 3D supervision "for free". Our pseudo-labels consist of instance masks and corresponding CLIP tokens, which we lift to Lidar using calibrated multi-modal data. By training our model on these labels, we distill the 2D foundation models into our Lidar $\texttt{SAL}$ model. Even without manual labels, our model achieves $91\%$ in terms of class-agnostic segmentation and $44\%$ in terms of zero-shot LPS of the fully supervised state-of-the-art. Furthermore, we outperform several baselines that do not distill but only lift image features to 3D. More importantly, we demonstrate that $\texttt{SAL}$ supports arbitrary class prompts, can be easily extended to new datasets, and shows significant potential to improve with increasing amounts of self-labeled data.
NOVIS: A Case for End-to-End Near-Online Video Instance Segmentation
Aug 29, 2023



Until recently, the Video Instance Segmentation (VIS) community operated under the common belief that offline methods are generally superior to a frame by frame online processing. However, the recent success of online methods questions this belief, in particular, for challenging and long video sequences. We understand this work as a rebuttal of those recent observations and an appeal to the community to focus on dedicated near-online VIS approaches. To support our argument, we present a detailed analysis on different processing paradigms and the new end-to-end trainable NOVIS (Near-Online Video Instance Segmentation) method. Our transformer-based model directly predicts spatio-temporal mask volumes for clips of frames and performs instance tracking between clips via overlap embeddings. NOVIS represents the first near-online VIS approach which avoids any handcrafted tracking heuristics. We outperform all existing VIS methods by large margins and provide new state-of-the-art results on both YouTube-VIS (2019/2021) and the OVIS benchmarks.
Data-Driven but Privacy-Conscious: Pedestrian Dataset De-identification via Full-Body Person Synthesis
Jun 22, 2023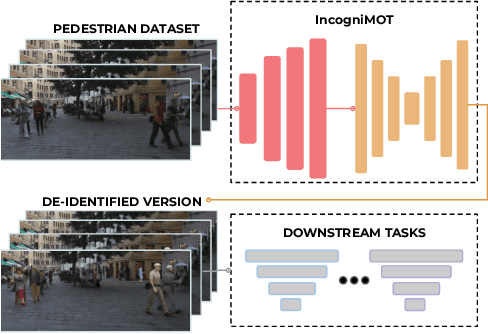

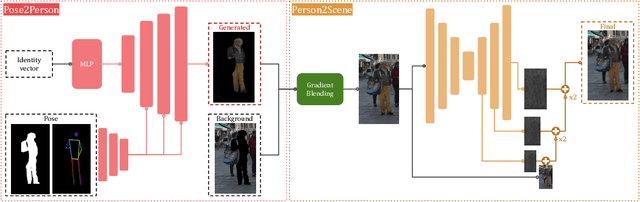

The advent of data-driven technology solutions is accompanied by an increasing concern with data privacy. This is of particular importance for human-centered image recognition tasks, such as pedestrian detection, re-identification, and tracking. To highlight the importance of privacy issues and motivate future research, we motivate and introduce the Pedestrian Dataset De-Identification (PDI) task. PDI evaluates the degree of de-identification and downstream task training performance for a given de-identification method. As a first baseline, we propose IncogniMOT, a two-stage full-body de-identification pipeline based on image synthesis via generative adversarial networks. The first stage replaces target pedestrians with synthetic identities. To improve downstream task performance, we then apply stage two, which blends and adapts the synthetic image parts into the data. To demonstrate the effectiveness of IncogniMOT, we generate a fully de-identified version of the MOT17 pedestrian tracking dataset and analyze its application as training data for pedestrian re-identification, detection, and tracking models. Furthermore, we show how our data is able to narrow the synthetic-to-real performance gap in a privacy-conscious manner.
DeVIS: Making Deformable Transformers Work for Video Instance Segmentation
Jul 22, 2022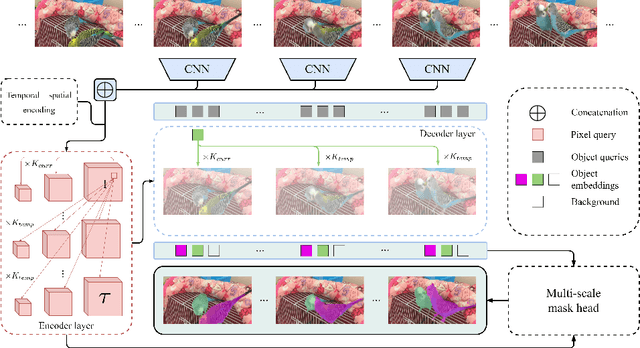
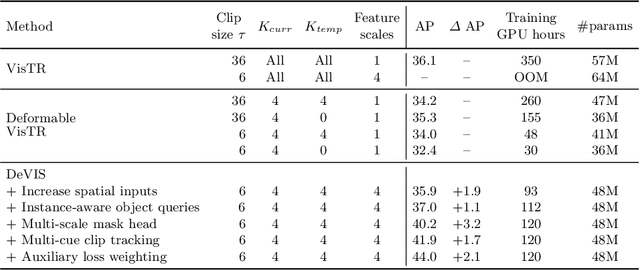
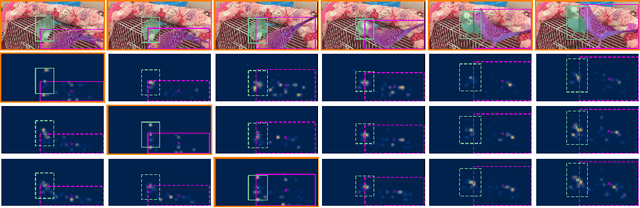
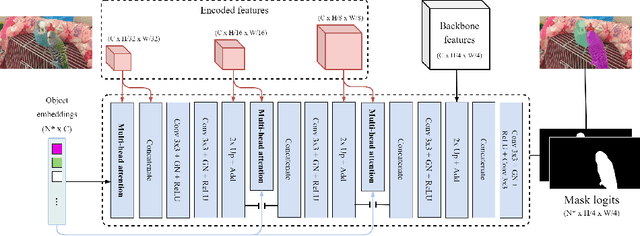
Video Instance Segmentation (VIS) jointly tackles multi-object detection, tracking, and segmentation in video sequences. In the past, VIS methods mirrored the fragmentation of these subtasks in their architectural design, hence missing out on a joint solution. Transformers recently allowed to cast the entire VIS task as a single set-prediction problem. Nevertheless, the quadratic complexity of existing Transformer-based methods requires long training times, high memory requirements, and processing of low-single-scale feature maps. Deformable attention provides a more efficient alternative but its application to the temporal domain or the segmentation task have not yet been explored. In this work, we present Deformable VIS (DeVIS), a VIS method which capitalizes on the efficiency and performance of deformable Transformers. To reason about all VIS subtasks jointly over multiple frames, we present temporal multi-scale deformable attention with instance-aware object queries. We further introduce a new image and video instance mask head with multi-scale features, and perform near-online video processing with multi-cue clip tracking. DeVIS reduces memory as well as training time requirements, and achieves state-of-the-art results on the YouTube-VIS 2021, as well as the challenging OVIS dataset. Code is available at https://github.com/acaelles97/DeVIS.
TrackFormer: Multi-Object Tracking with Transformers
Jan 07, 2021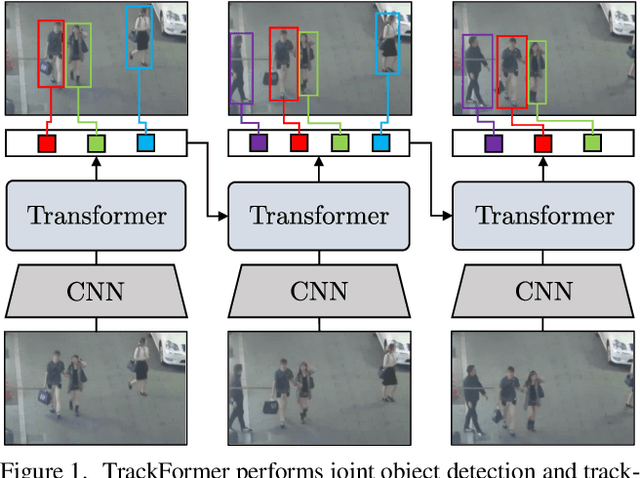



We present TrackFormer, an end-to-end multi-object tracking and segmentation model based on an encoder-decoder Transformer architecture. Our approach introduces track query embeddings which follow objects through a video sequence in an autoregressive fashion. New track queries are spawned by the DETR object detector and embed the position of their corresponding object over time. The Transformer decoder adjusts track query embeddings from frame to frame, thereby following the changing object positions. TrackFormer achieves a seamless data association between frames in a new tracking-by-attention paradigm by self- and encoder-decoder attention mechanisms which simultaneously reason about location, occlusion, and object identity. TrackFormer yields state-of-the-art performance on the tasks of multi-object tracking (MOT17) and segmentation (MOTS20). We hope our unified way of performing detection and tracking will foster future research in multi-object tracking and video understanding. Code will be made publicly available.
Make One-Shot Video Object Segmentation Efficient Again
Dec 03, 2020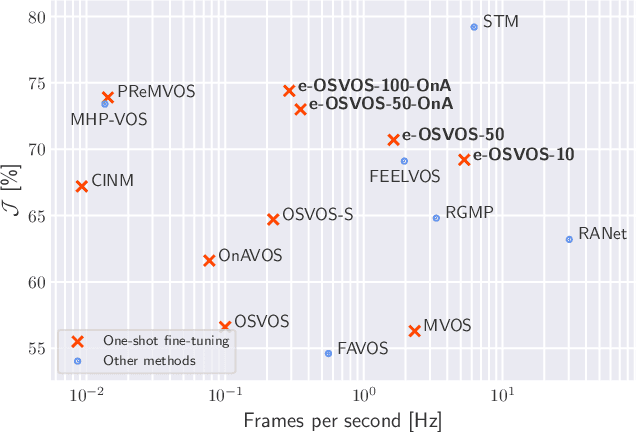
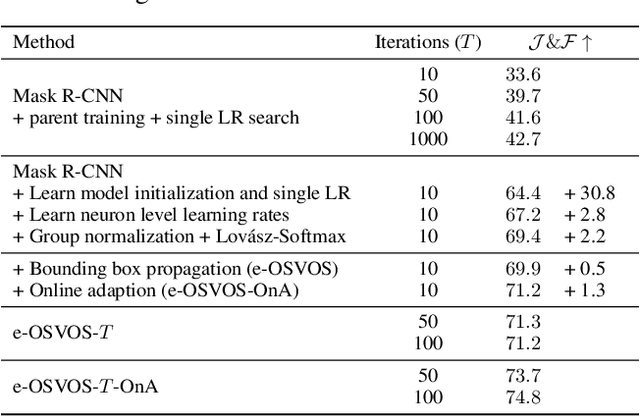

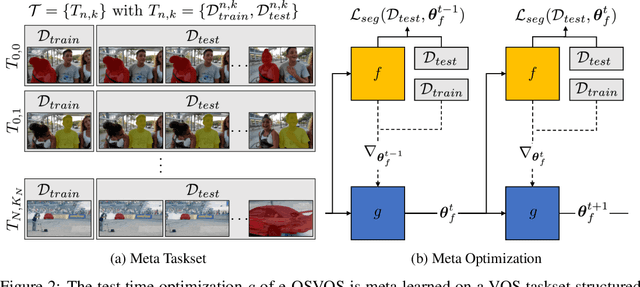
Video object segmentation (VOS) describes the task of segmenting a set of objects in each frame of a video. In the semi-supervised setting, the first mask of each object is provided at test time. Following the one-shot principle, fine-tuning VOS methods train a segmentation model separately on each given object mask. However, recently the VOS community has deemed such a test time optimization and its impact on the test runtime as unfeasible. To mitigate the inefficiencies of previous fine-tuning approaches, we present efficient One-Shot Video Object Segmentation (e-OSVOS). In contrast to most VOS approaches, e-OSVOS decouples the object detection task and predicts only local segmentation masks by applying a modified version of Mask R-CNN. The one-shot test runtime and performance are optimized without a laborious and handcrafted hyperparameter search. To this end, we meta learn the model initialization and learning rates for the test time optimization. To achieve optimal learning behavior, we predict individual learning rates at a neuron level. Furthermore, we apply an online adaptation to address the common performance degradation throughout a sequence by continuously fine-tuning the model on previous mask predictions supported by a frame-to-frame bounding box propagation. e-OSVOS provides state-of-the-art results on DAVIS 2016, DAVIS 2017, and YouTube-VOS for one-shot fine-tuning methods while reducing the test runtime substantially. Code is available at https://github.com/dvl-tum/e-osvos.