 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrackFormer: Multi-Object Tracking with Transformers
Paper and Code
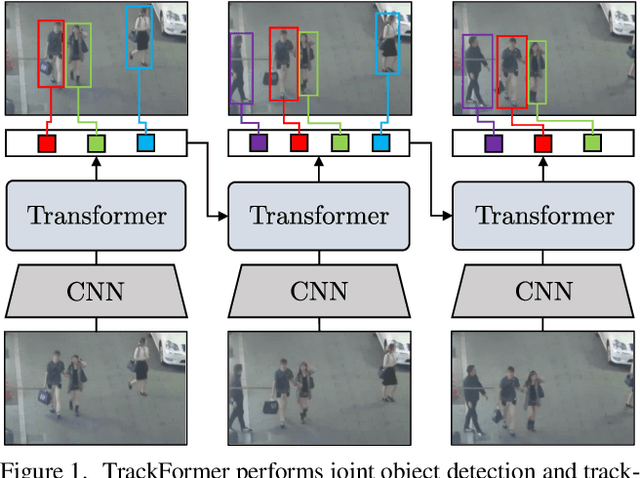



We present TrackFormer, an end-to-end multi-object tracking and segmentation model based on an encoder-decoder Transformer architecture. Our approach introduces track query embeddings which follow objects through a video sequence in an autoregressive fashion. New track queries are spawned by the DETR object detector and embed the position of their corresponding object over time. The Transformer decoder adjusts track query embeddings from frame to frame, thereby following the changing object positions. TrackFormer achieves a seamless data association between frames in a new tracking-by-attention paradigm by self- and encoder-decoder attention mechanisms which simultaneously reason about location, occlusion, and object identity. TrackFormer yields state-of-the-art performance on the tasks of multi-object tracking (MOT17) and segmentation (MOTS20). We hope our unified way of performing detection and tracking will foster future research in multi-object tracking and video understanding. Code will be made publicly available.