 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNative Segmentation Vision Transformers
May 22, 2025Uniform downsampling remains the de facto standard for reducing spatial resolution in vision backbones. In this work, we propose an alternative design built around a content-aware spatial grouping layer, that dynamically assigns tokens to a reduced set based on image boundaries and their semantic content. Stacking our grouping layer across consecutive backbone stages results in hierarchical segmentation that arises natively in the feature extraction process, resulting in our coined Native Segmentation Vision Transformer. We show that a careful design of our architecture enables the emergence of strong segmentation masks solely from grouping layers, that is, without additional segmentation-specific heads. This sets the foundation for a new paradigm of native, backbone-level segmentation, which enables strong zero-shot results without mask supervision, as well as a minimal and efficient standalone model design for downstream segmentation tasks. Our project page is https://research.nvidia.com/labs/dvl/projects/native-segmentation.
SPAMming Labels: Efficient Annotations for the Trackers of Tomorrow
Apr 17, 2024Increasing the annotation efficiency of trajectory annotations from videos has the potential to enable the next generation of data-hungry tracking algorithms to thrive on large-scale datasets. Despite the importance of this task, there are currently very few works exploring how to efficiently label tracking datasets comprehensively. In this work, we introduce SPAM, a tracking data engine that provides high-quality labels with minimal human intervention. SPAM is built around two key insights: i) most tracking scenarios can be easily resolved. To take advantage of this, we utilize a pre-trained model to generate high-quality pseudo-labels, reserving human involvement for a smaller subset of more difficult instances; ii) handling the spatiotemporal dependencies of track annotations across time can be elegantly and efficiently formulated through graphs. Therefore, we use a unified graph formulation to address the annotation of both detections and identity association for tracks across time. Based on these insights, SPAM produces high-quality annotations with a fraction of ground truth labeling cost. We demonstrate that trackers trained on SPAM labels achieve comparable performance to those trained on human annotations while requiring only 3-20% of the human labeling effort. Hence, SPAM paves the way towards highly efficient labeling of large-scale tracking datasets. Our code and models will be available upon acceptance.
Unifying Short and Long-Term Tracking with Graph Hierarchies
Dec 06, 2022Tracking objects over long videos effectively means solving a spectrum of problems, from short-term association for un-occluded objects to long-term association for objects that are occluded and then reappear in the scene. Methods tackling these two tasks are often disjoint and crafted for specific scenarios, and top-performing approaches are often a mix of techniques, which yields engineering-heavy solutions that lack generality. In this work, we question the need for hybrid approaches and introduce SUSHI, a unified and scalable multi-object tracker. Our approach processes long clips by splitting them into a hierarchy of subclips, which enables high scalability. We leverage graph neural networks to process all levels of the hierarchy, which makes our model unified across temporal scales and highly general. As a result, we obtain significant improvements over state-of-the-art on four diverse datasets. Our code and models will be made available.
The Unreasonable Effectiveness of Fully-Connected Layers for Low-Data Regimes
Oct 13, 2022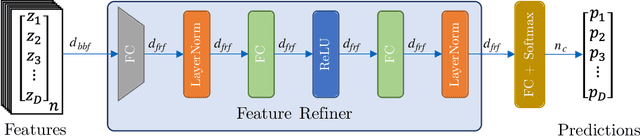
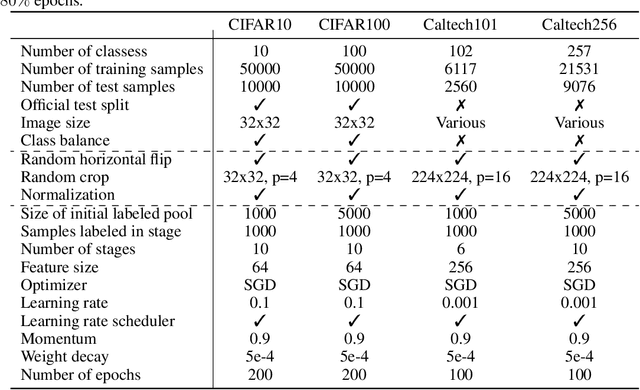
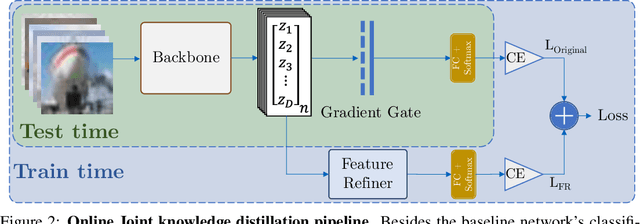

Convolutional neural networks were the standard for solving many computer vision tasks until recently, when Transformers of MLP-based architectures have started to show competitive performance. These architectures typically have a vast number of weights and need to be trained on massive datasets; hence, they are not suitable for their use in low-data regimes. In this work, we propose a simple yet effective framework to improve generalization from small amounts of data. We augment modern CNNs with fully-connected (FC) layers and show the massive impact this architectural change has in low-data regimes. We further present an online joint knowledge-distillation method to utilize the extra FC layers at train time but avoid them during test time. This allows us to improve the generalization of a CNN-based model without any increase in the number of weights at test time. We perform classification experiments for a large range of network backbones and several standard datasets on supervised learning and active learning. Our experiments significantly outperform the networks without fully-connected layers, reaching a relative improvement of up to $16\%$ validation accuracy in the supervised setting without adding any extra parameters during inference.
PolarMOT: How Far Can Geometric Relations Take Us in 3D Multi-Object Tracking?
Aug 03, 2022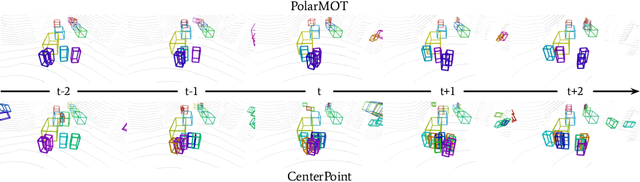
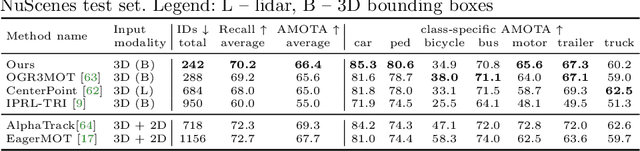
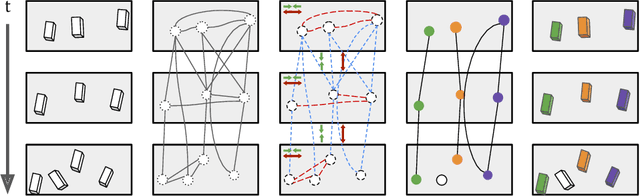

Most (3D) multi-object tracking methods rely on appearance-based cues for data association. By contrast, we investigate how far we can get by only encoding geometric relationships between objects in 3D space as cues for data-driven data association. We encode 3D detections as nodes in a graph, where spatial and temporal pairwise relations among objects are encoded via localized polar coordinates on graph edges. This representation makes our geometric relations invariant to global transformations and smooth trajectory changes, especially under non-holonomic motion. This allows our graph neural network to learn to effectively encode temporal and spatial interactions and fully leverage contextual and motion cues to obtain final scene interpretation by posing data association as edge classification. We establish a new state-of-the-art on nuScenes dataset and, more importantly, show that our method, PolarMOT, generalizes remarkably well across different locations (Boston, Singapore, Karlsruhe) and datasets (nuScenes and KITTI).
DeVIS: Making Deformable Transformers Work for Video Instance Segmentation
Jul 22, 2022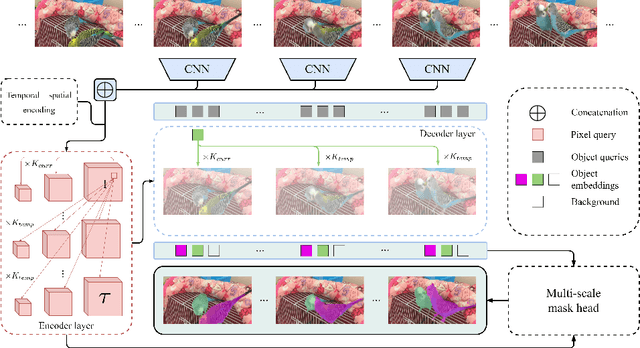
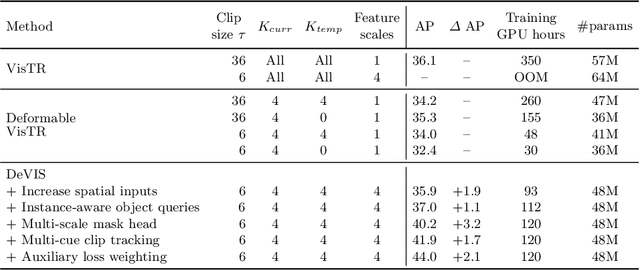
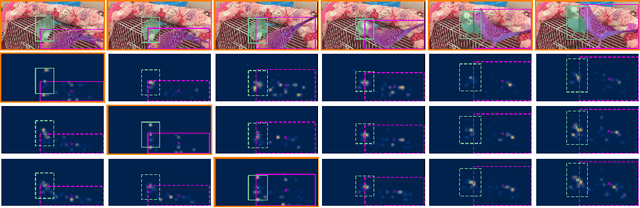
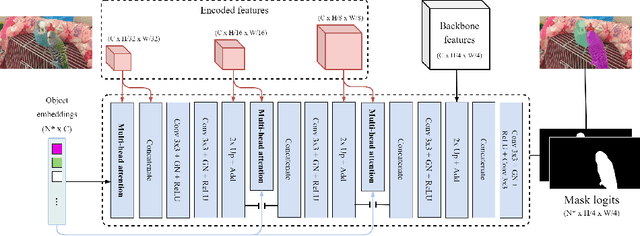
Video Instance Segmentation (VIS) jointly tackles multi-object detection, tracking, and segmentation in video sequences. In the past, VIS methods mirrored the fragmentation of these subtasks in their architectural design, hence missing out on a joint solution. Transformers recently allowed to cast the entire VIS task as a single set-prediction problem. Nevertheless, the quadratic complexity of existing Transformer-based methods requires long training times, high memory requirements, and processing of low-single-scale feature maps. Deformable attention provides a more efficient alternative but its application to the temporal domain or the segmentation task have not yet been explored. In this work, we present Deformable VIS (DeVIS), a VIS method which capitalizes on the efficiency and performance of deformable Transformers. To reason about all VIS subtasks jointly over multiple frames, we present temporal multi-scale deformable attention with instance-aware object queries. We further introduce a new image and video instance mask head with multi-scale features, and perform near-online video processing with multi-cue clip tracking. DeVIS reduces memory as well as training time requirements, and achieves state-of-the-art results on the YouTube-VIS 2021, as well as the challenging OVIS dataset. Code is available at https://github.com/acaelles97/DeVIS.
Simple Cues Lead to a Strong Multi-Object Tracker
Jun 13, 2022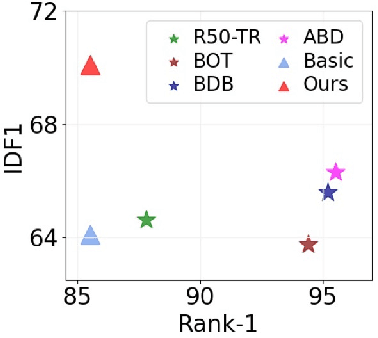

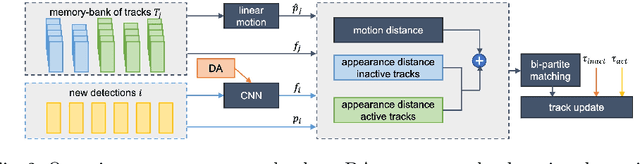
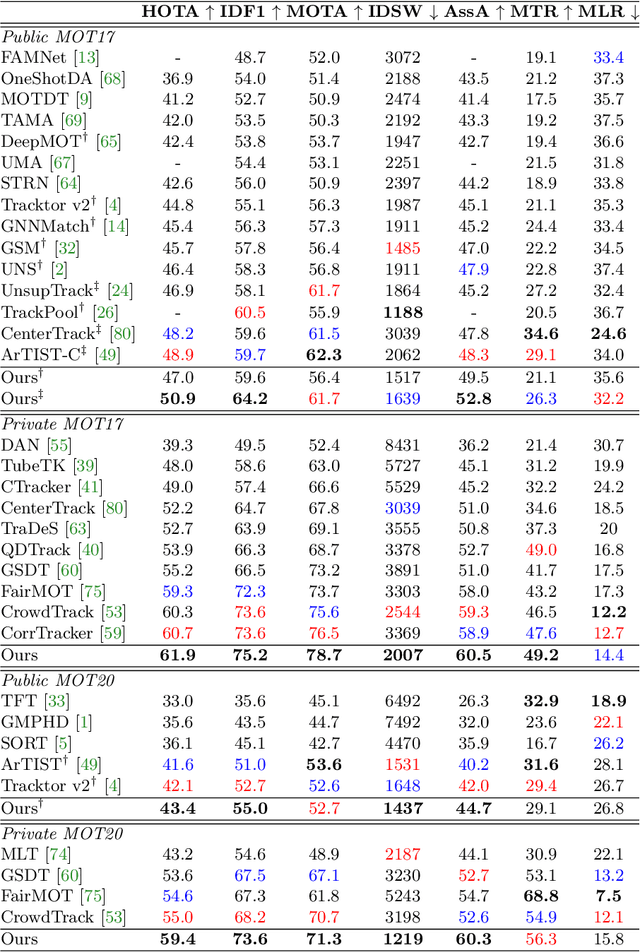
For a long time, the most common paradigm in Multi-Object Tracking was tracking-by-detection (TbD), where objects are first detected and then associated over video frames. For association, most models resource to motion and appearance cues. While still relying on these cues, recent approaches based on, e.g., attention have shown an ever-increasing need for training data and overall complex frameworks. We claim that 1) strong cues can be obtained from little amounts of training data if some key design choices are applied, 2) given these strong cues, standard Hungarian matching-based association is enough to obtain impressive results. Our main insight is to identify key components that allow a standard reidentification network to excel at appearance-based tracking. We extensively analyze its failure cases and show that a combination of our appearance features with a simple motion model leads to strong tracking results. Our model achieves state-of-the-art performance on MOT17 and MOT20 datasets outperforming previous state-of-the-art trackers by up to 5.4pp in IDF1 and 4.4pp in HOTA. We will release the code and models after the paper's acceptance.
The Center of Attention: Center-Keypoint Grouping via Attention for Multi-Person Pose Estimation
Oct 11, 2021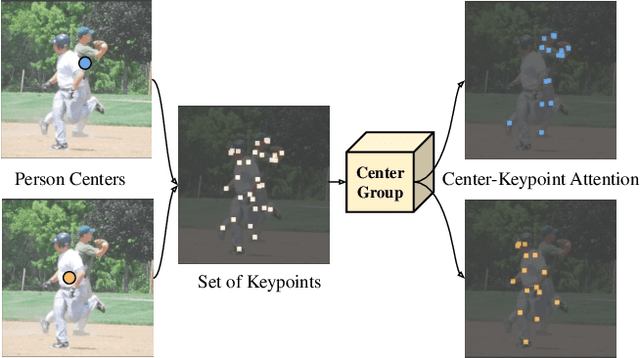

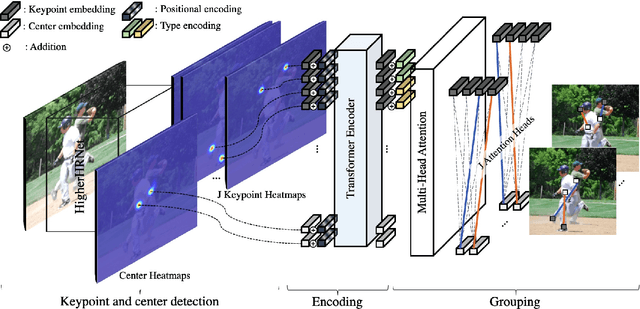

We introduce CenterGroup, an attention-based framework to estimate human poses from a set of identity-agnostic keypoints and person center predictions in an image. Our approach uses a transformer to obtain context-aware embeddings for all detected keypoints and centers and then applies multi-head attention to directly group joints into their corresponding person centers. While most bottom-up methods rely on non-learnable clustering at inference, CenterGroup uses a fully differentiable attention mechanism that we train end-to-end together with our keypoint detector. As a result, our method obtains state-of-the-art performance with up to 2.5x faster inference time than competing bottom-up methods. Our code is available at https://github.com/dvl-tum/center-group .
Learning a Neural Solver for Multiple Object Tracking
Dec 16, 2019

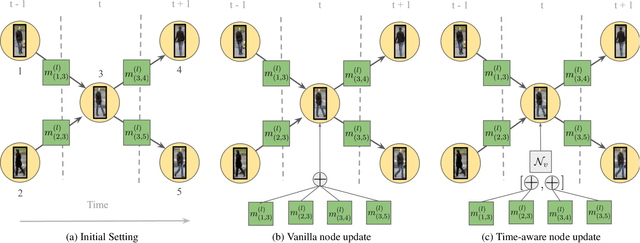

Graphs offer a natural way to formulate Multiple Object Tracking (MOT) within the tracking-by-detection paradigm. However, they also introduce a major challenge for learning methods, as defining a model that can operate on such a structured domain is not trivial. As a consequence, most learning-based work has been devoted to learning better features for MOT, and then using these with well-established optimization frameworks. In this work, we exploit the classical network flow formulation of MOT to define a fully differentiable framework based on Message Passing Networks (MPNs). By operating directly on the graph domain, our method can reason globally over an entire set of detections and predict final solutions. Hence, we show that learning in MOT does not need to be restricted to feature extraction, but it can also be applied to the data association step. We show a significant improvement in both MOTA and IDF1 on three publicly available benchmarks.