 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAre Pose Estimators Ready for the Open World? STAGE: Synthetic Data Generation Toolkit for Auditing 3D Human Pose Estimators
Aug 28, 2024



The estimation of 3D human poses from images has progressed tremendously over the last few years as measured on standard benchmarks. However, performance in the open world remains underexplored, as current benchmarks cannot capture its full extent. Especially in safety-critical systems, it is crucial that 3D pose estimators are audited before deployment, and their sensitivity towards single factors or attributes occurring in the operational domain is thoroughly examined. Nevertheless, we currently lack a benchmark that would enable such fine-grained analysis. We thus present STAGE, a GenAI data toolkit for auditing 3D human pose estimators. We enable a text-to-image model to control the 3D human body pose in the generated image. This allows us to create customized annotated data covering a wide range of open-world attributes. We leverage STAGE and generate a series of benchmarks to audit the sensitivity of popular pose estimators towards attributes such as gender, ethnicity, age, clothing, location, and weather. Our results show that the presence of such naturally occurring attributes can cause severe degradation in the performance of pose estimators and leads us to question if they are ready for open-world deployment.
The Center of Attention: Center-Keypoint Grouping via Attention for Multi-Person Pose Estimation
Oct 11, 2021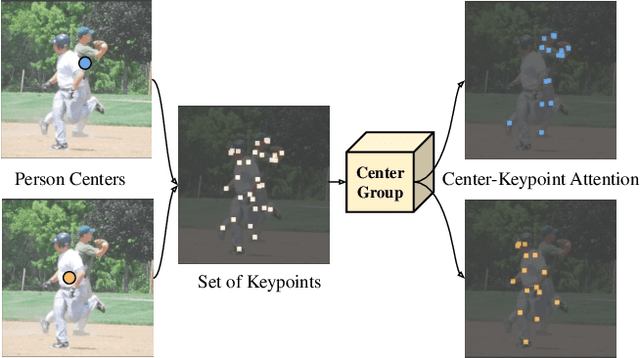

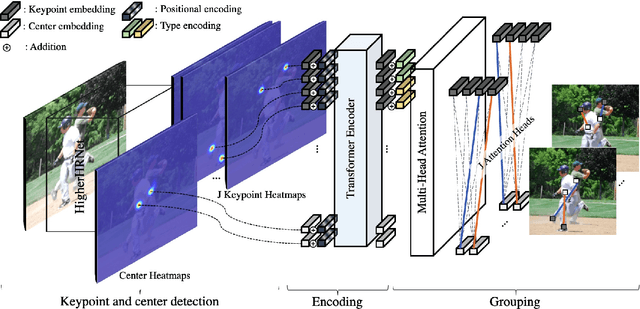

We introduce CenterGroup, an attention-based framework to estimate human poses from a set of identity-agnostic keypoints and person center predictions in an image. Our approach uses a transformer to obtain context-aware embeddings for all detected keypoints and centers and then applies multi-head attention to directly group joints into their corresponding person centers. While most bottom-up methods rely on non-learnable clustering at inference, CenterGroup uses a fully differentiable attention mechanism that we train end-to-end together with our keypoint detector. As a result, our method obtains state-of-the-art performance with up to 2.5x faster inference time than competing bottom-up methods. Our code is available at https://github.com/dvl-tum/center-group .
Assessment of Deep Convolutional Neural Networks for Road Surface Classification
Aug 07, 2018
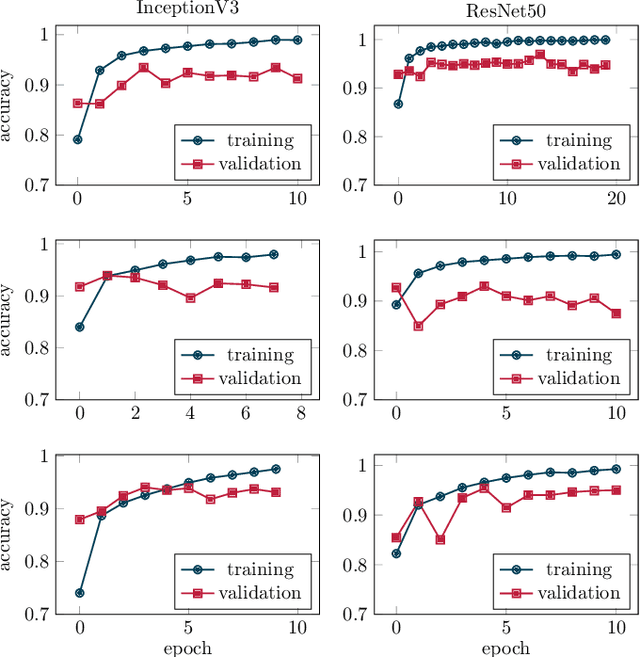


When parameterizing vehicle control algorithms for stability or trajectory control, the road-tire friction coefficient is an essential model parameter when it comes to control performance. One major impact on the friction coefficient is the condition of the road surface. A camera-based, forward-looking classification of the road-surface helps enabling an early parametrization of vehicle control algorithms. In this paper, we train and compare two different Deep Convolutional Neural Network models, regarding their application for road friction estimation and describe the challenges for training the classifier in terms of available training data and the construction of suitable datasets.