 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAre Pose Estimators Ready for the Open World? STAGE: Synthetic Data Generation Toolkit for Auditing 3D Human Pose Estimators
Aug 28, 2024



The estimation of 3D human poses from images has progressed tremendously over the last few years as measured on standard benchmarks. However, performance in the open world remains underexplored, as current benchmarks cannot capture its full extent. Especially in safety-critical systems, it is crucial that 3D pose estimators are audited before deployment, and their sensitivity towards single factors or attributes occurring in the operational domain is thoroughly examined. Nevertheless, we currently lack a benchmark that would enable such fine-grained analysis. We thus present STAGE, a GenAI data toolkit for auditing 3D human pose estimators. We enable a text-to-image model to control the 3D human body pose in the generated image. This allows us to create customized annotated data covering a wide range of open-world attributes. We leverage STAGE and generate a series of benchmarks to audit the sensitivity of popular pose estimators towards attributes such as gender, ethnicity, age, clothing, location, and weather. Our results show that the presence of such naturally occurring attributes can cause severe degradation in the performance of pose estimators and leads us to question if they are ready for open-world deployment.
Neural Localizer Fields for Continuous 3D Human Pose and Shape Estimation
Jul 10, 2024With the explosive growth of available training data, single-image 3D human modeling is ahead of a transition to a data-centric paradigm. A key to successfully exploiting data scale is to design flexible models that can be supervised from various heterogeneous data sources produced by different researchers or vendors. To this end, we propose a simple yet powerful paradigm for seamlessly unifying different human pose and shape-related tasks and datasets. Our formulation is centered on the ability - both at training and test time - to query any arbitrary point of the human volume, and obtain its estimated location in 3D. We achieve this by learning a continuous neural field of body point localizer functions, each of which is a differently parameterized 3D heatmap-based convolutional point localizer (detector). For generating parametric output, we propose an efficient post-processing step for fitting SMPL-family body models to nonparametric joint and vertex predictions. With this approach, we can naturally exploit differently annotated data sources including mesh, 2D/3D skeleton and dense pose, without having to convert between them, and thereby train large-scale 3D human mesh and skeleton estimation models that outperform the state-of-the-art on several public benchmarks including 3DPW, EMDB and SSP-3D by a considerable margin.
Learning 3D Human Pose Estimation from Dozens of Datasets using a Geometry-Aware Autoencoder to Bridge Between Skeleton Formats
Dec 29, 2022
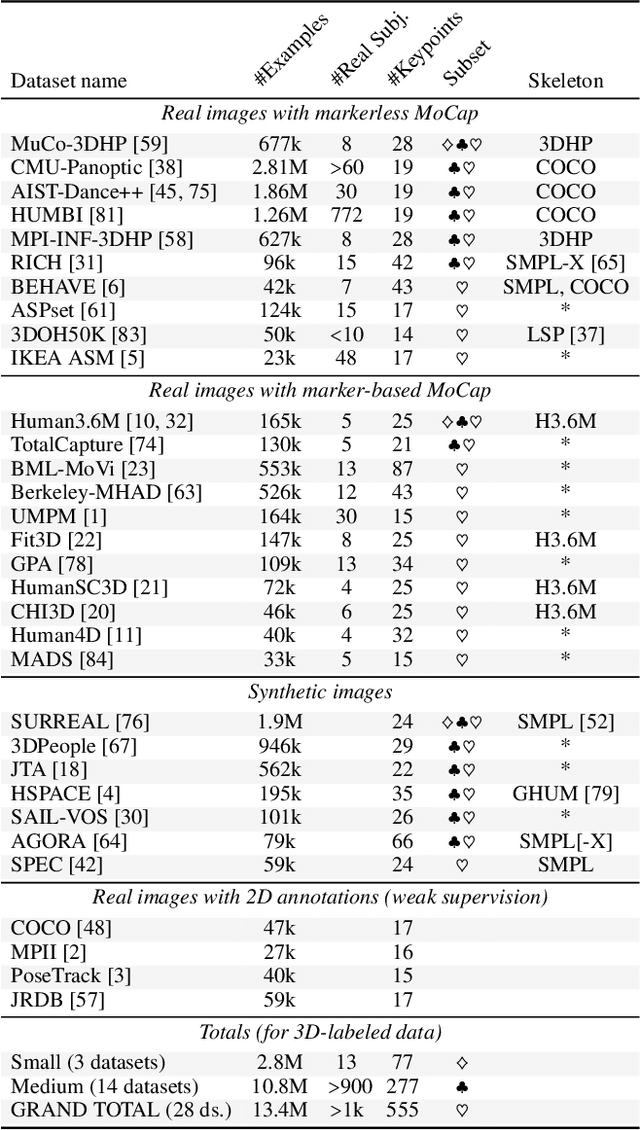


Deep learning-based 3D human pose estimation performs best when trained on large amounts of labeled data, making combined learning from many datasets an important research direction. One obstacle to this endeavor are the different skeleton formats provided by different datasets, i.e., they do not label the same set of anatomical landmarks. There is little prior research on how to best supervise one model with such discrepant labels. We show that simply using separate output heads for different skeletons results in inconsistent depth estimates and insufficient information sharing across skeletons. As a remedy, we propose a novel affine-combining autoencoder (ACAE) method to perform dimensionality reduction on the number of landmarks. The discovered latent 3D points capture the redundancy among skeletons, enabling enhanced information sharing when used for consistency regularization. Our approach scales to an extreme multi-dataset regime, where we use 28 3D human pose datasets to supervise one model, which outperforms prior work on a range of benchmarks, including the challenging 3D Poses in the Wild (3DPW) dataset. Our code and models are available for research purposes.
MeTRAbs: Metric-Scale Truncation-Robust Heatmaps for Absolute 3D Human Pose Estimation
Jul 12, 2020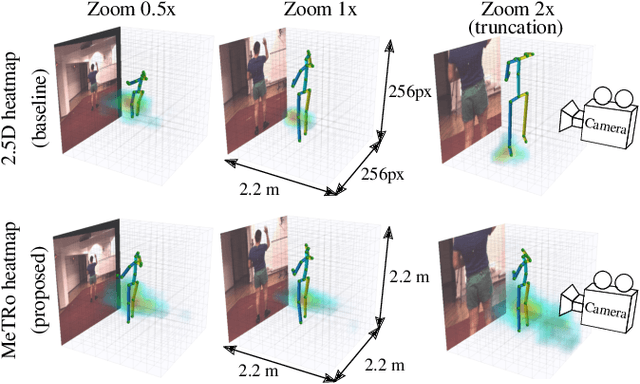
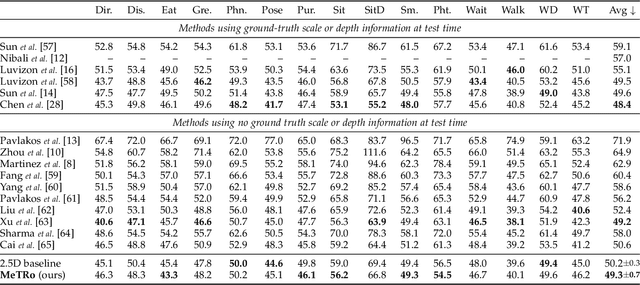
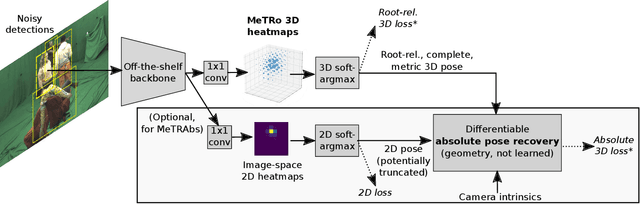
Heatmap representations have formed the basis of human pose estimation systems for many years, and their extension to 3D has been a fruitful line of recent research. This includes 2.5D volumetric heatmaps, whose X and Y axes correspond to image space and Z to metric depth around the subject. To obtain metric-scale predictions, 2.5D methods need a separate post-processing step to resolve scale ambiguity. Further, they cannot localize body joints outside the image boundaries, leading to incomplete estimates for truncated images. To address these limitations, we propose metric-scale truncation-robust (MeTRo) volumetric heatmaps, whose dimensions are all defined in metric 3D space, instead of being aligned with image space. This reinterpretation of heatmap dimensions allows us to directly estimate complete, metric-scale poses without test-time knowledge of distance or relying on anthropometric heuristics, such as bone lengths. To further demonstrate the utility our representation, we present a differentiable combination of our 3D metric-scale heatmaps with 2D image-space ones to estimate absolute 3D pose (our MeTRAbs architecture). We find that supervision via absolute pose loss is crucial for accurate non-root-relative localization. Using a ResNet-50 backbone without further learned layers, we obtain state-of-the-art results on Human3.6M, MPI-INF-3DHP and MuPoTS-3D. Our code will be made publicly available to facilitate further research.
Reposing Humans by Warping 3D Features
Jun 08, 2020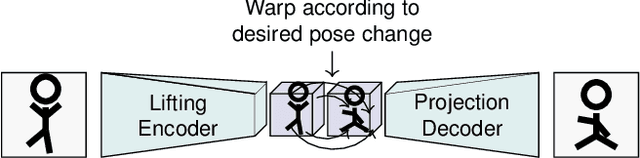
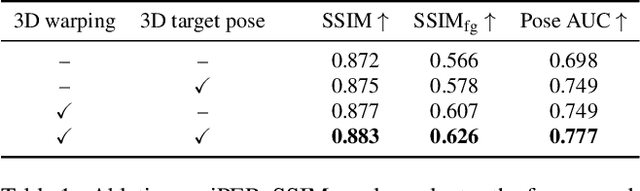

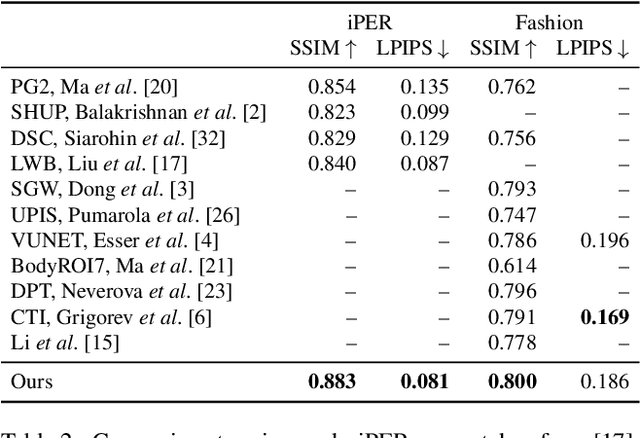
We address the problem of reposing an image of a human into any desired novel pose. This conditional image-generation task requires reasoning about the 3D structure of the human, including self-occluded body parts. Most prior works are either based on 2D representations or require fitting and manipulating an explicit 3D body mesh. Based on the recent success in deep learning-based volumetric representations, we propose to implicitly learn a dense feature volume from human images, which lends itself to simple and intuitive manipulation through explicit geometric warping. Once the latent feature volume is warped according to the desired pose change, the volume is mapped back to RGB space by a convolutional decoder. Our state-of-the-art results on the DeepFashion and the iPER benchmarks indicate that dense volumetric human representations are worth investigating in more detail.
Metric-Scale Truncation-Robust Heatmaps for 3D Human Pose Estimation
Mar 05, 2020
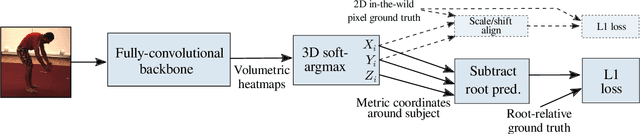


Heatmap representations have formed the basis of 2D human pose estimation systems for many years, but their generalizations for 3D pose have only recently been considered. This includes 2.5D volumetric heatmaps, whose X and Y axes correspond to image space and the Z axis to metric depth around the subject. To obtain metric-scale predictions, these methods must include a separate, explicit post-processing step to resolve scale ambiguity. Further, they cannot encode body joint positions outside of the image boundaries, leading to incomplete pose estimates in case of image truncation. We address these limitations by proposing metric-scale truncation-robust (MeTRo) volumetric heatmaps, whose dimensions are defined in metric 3D space near the subject, instead of being aligned with image space. We train a fully-convolutional network to estimate such heatmaps from monocular RGB in an end-to-end manner. This reinterpretation of the heatmap dimensions allows us to estimate complete metric-scale poses without test-time knowledge of the focal length or person distance and without relying on anthropometric heuristics in post-processing. Furthermore, as the image space is decoupled from the heatmap space, the network can learn to reason about joints beyond the image boundary. Using ResNet-50 without any additional learned layers, we obtain state-of-the-art results on the Human3.6M and MPI-INF-3DHP benchmarks. As our method is simple and fast, it can become a useful component for real-time top-down multi-person pose estimation systems. We make our code publicly available to facilitate further research (see https://vision.rwth-aachen.de/metro-pose3d).
Visual Person Understanding through Multi-Task and Multi-Dataset Learning
Jun 07, 2019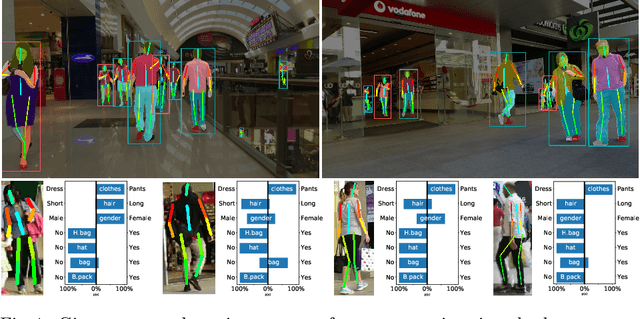
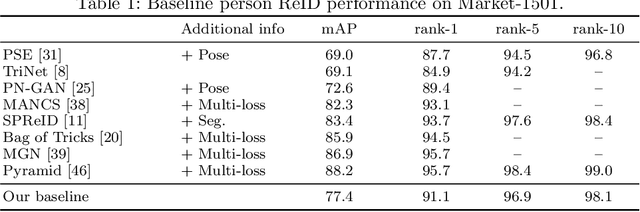
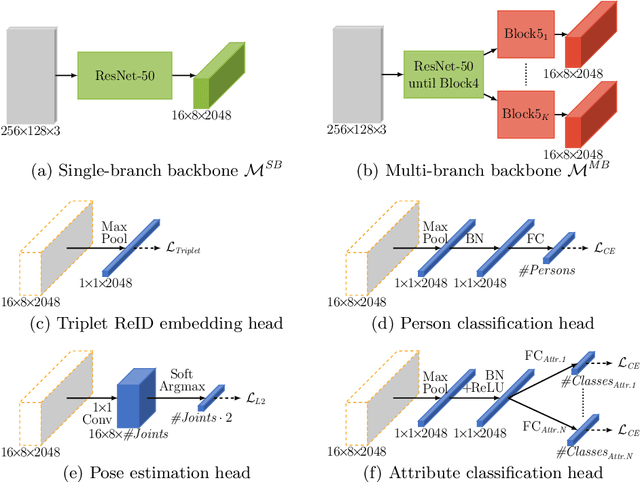

We address the problem of learning a single model for person re-identification, attribute classification, body part segmentation, and pose estimation. With predictions for these tasks we gain a more holistic understanding of persons, which is valuable for many applications. This is a classical multi-task learning problem. However, no dataset exists that these tasks could be jointly learned from. Hence several datasets need to be combined during training, which in other contexts has often led to reduced performance in the past. We extensively evaluate how the different task and datasets influence each other and how different degrees of parameter sharing between the tasks affect performance. Our final model matches or outperforms its single-task counterparts without creating significant computational overhead, rendering it highly interesting for resource-constrained scenarios such as mobile robotics.
Synthetic Occlusion Augmentation with Volumetric Heatmaps for the 2018 ECCV PoseTrack Challenge on 3D Human Pose Estimation
Nov 06, 2018
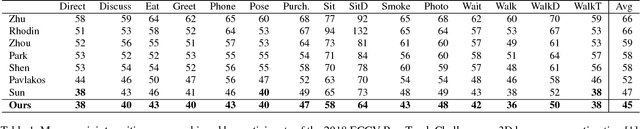
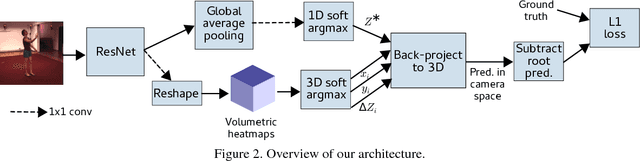
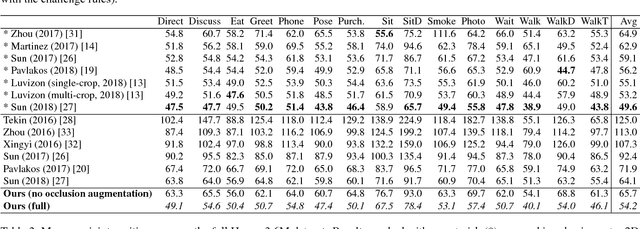
In this paper we present our winning entry at the 2018 ECCV PoseTrack Challenge on 3D human pose estimation. Using a fully-convolutional backbone architecture, we obtain volumetric heatmaps per body joint, which we convert to coordinates using soft-argmax. Absolute person center depth is estimated by a 1D heatmap prediction head. The coordinates are back-projected to 3D camera space, where we minimize the L1 loss. Key to our good results is the training data augmentation with randomly placed occluders from the Pascal VOC dataset. In addition to reaching first place in the Challenge, our method also surpasses the state-of-the-art on the full Human3.6M benchmark among methods that use no additional pose datasets in training. Code for applying synthetic occlusions is availabe at https://github.com/isarandi/synthetic-occlusion.
How Robust is 3D Human Pose Estimation to Occlusion?
Aug 29, 2018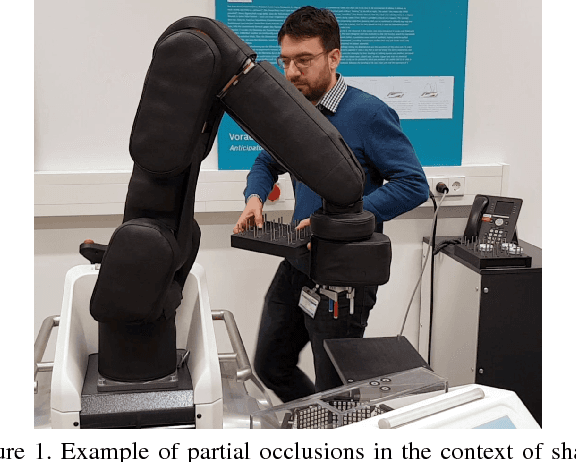



Occlusion is commonplace in realistic human-robot shared environments, yet its effects are not considered in standard 3D human pose estimation benchmarks. This leaves the question open: how robust are state-of-the-art 3D pose estimation methods against partial occlusions? We study several types of synthetic occlusions over the Human3.6M dataset and find a method with state-of-the-art benchmark performance to be sensitive even to low amounts of occlusion. Addressing this issue is key to progress in applications such as collaborative and service robotics. We take a first step in this direction by improving occlusion-robustness through training data augmentation with synthetic occlusions. This also turns out to be an effective regularizer that is beneficial even for non-occluded test cases.