 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntrinsic Image Fusion for Multi-View 3D Material Reconstruction
Dec 15, 2025We introduce Intrinsic Image Fusion, a method that reconstructs high-quality physically based materials from multi-view images. Material reconstruction is highly underconstrained and typically relies on analysis-by-synthesis, which requires expensive and noisy path tracing. To better constrain the optimization, we incorporate single-view priors into the reconstruction process. We leverage a diffusion-based material estimator that produces multiple, but often inconsistent, candidate decompositions per view. To reduce the inconsistency, we fit an explicit low-dimensional parametric function to the predictions. We then propose a robust optimization framework using soft per-view prediction selection together with confidence-based soft multi-view inlier set to fuse the most consistent predictions of the most confident views into a consistent parametric material space. Finally, we use inverse path tracing to optimize for the low-dimensional parameters. Our results outperform state-of-the-art methods in material disentanglement on both synthetic and real scenes, producing sharp and clean reconstructions suitable for high-quality relighting.
IntrinsiX: High-Quality PBR Generation using Image Priors
Apr 01, 2025We introduce IntrinsiX, a novel method that generates high-quality intrinsic images from text description. In contrast to existing text-to-image models whose outputs contain baked-in scene lighting, our approach predicts physically-based rendering (PBR) maps. This enables the generated outputs to be used for content creation scenarios in core graphics applications that facilitate re-lighting, editing, and texture generation tasks. In order to train our generator, we exploit strong image priors, and pre-train separate models for each PBR material component (albedo, roughness, metallic, normals). We then align these models with a new cross-intrinsic attention formulation that concatenates key and value features in a consistent fashion. This allows us to exchange information between each output modality and to obtain semantically coherent PBR predictions. To ground each intrinsic component, we propose a rendering loss which provides image-space signals to constrain the model, thus facilitating sharp details also in the output BRDF properties. Our results demonstrate detailed intrinsic generation with strong generalization capabilities that outperforms existing intrinsic image decomposition methods used with generated images by a significant margin. Finally, we show a series of applications, including re-lighting, editing, and text-conditioned room-scale PBR texture generation.
LightIt: Illumination Modeling and Control for Diffusion Models
Mar 25, 2024We introduce LightIt, a method for explicit illumination control for image generation. Recent generative methods lack lighting control, which is crucial to numerous artistic aspects of image generation such as setting the overall mood or cinematic appearance. To overcome these limitations, we propose to condition the generation on shading and normal maps. We model the lighting with single bounce shading, which includes cast shadows. We first train a shading estimation module to generate a dataset of real-world images and shading pairs. Then, we train a control network using the estimated shading and normals as input. Our method demonstrates high-quality image generation and lighting control in numerous scenes. Additionally, we use our generated dataset to train an identity-preserving relighting model, conditioned on an image and a target shading. Our method is the first that enables the generation of images with controllable, consistent lighting and performs on par with specialized relighting state-of-the-art methods.
Intrinsic Image Diffusion for Single-view Material Estimation
Dec 19, 2023We present Intrinsic Image Diffusion, a generative model for appearance decomposition of indoor scenes. Given a single input view, we sample multiple possible material explanations represented as albedo, roughness, and metallic maps. Appearance decomposition poses a considerable challenge in computer vision due to the inherent ambiguity between lighting and material properties and the lack of real datasets. To address this issue, we advocate for a probabilistic formulation, where instead of attempting to directly predict the true material properties, we employ a conditional generative model to sample from the solution space. Furthermore, we show that utilizing the strong learned prior of recent diffusion models trained on large-scale real-world images can be adapted to material estimation and highly improves the generalization to real images. Our method produces significantly sharper, more consistent, and more detailed materials, outperforming state-of-the-art methods by $1.5dB$ on PSNR and by $45\%$ better FID score on albedo prediction. We demonstrate the effectiveness of our approach through experiments on both synthetic and real-world datasets.
The Unreasonable Effectiveness of Fully-Connected Layers for Low-Data Regimes
Oct 13, 2022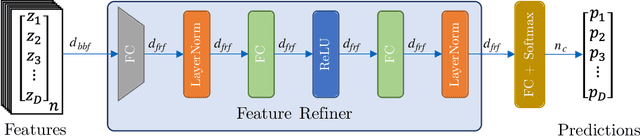
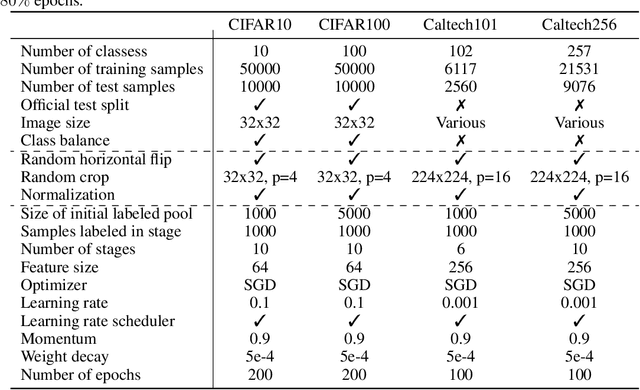
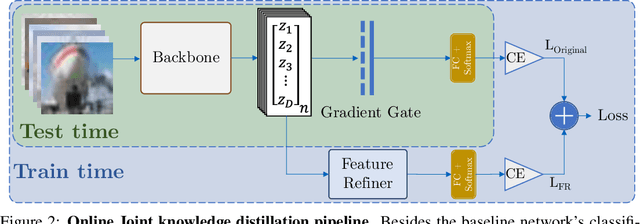

Convolutional neural networks were the standard for solving many computer vision tasks until recently, when Transformers of MLP-based architectures have started to show competitive performance. These architectures typically have a vast number of weights and need to be trained on massive datasets; hence, they are not suitable for their use in low-data regimes. In this work, we propose a simple yet effective framework to improve generalization from small amounts of data. We augment modern CNNs with fully-connected (FC) layers and show the massive impact this architectural change has in low-data regimes. We further present an online joint knowledge-distillation method to utilize the extra FC layers at train time but avoid them during test time. This allows us to improve the generalization of a CNN-based model without any increase in the number of weights at test time. We perform classification experiments for a large range of network backbones and several standard datasets on supervised learning and active learning. Our experiments significantly outperform the networks without fully-connected layers, reaching a relative improvement of up to $16\%$ validation accuracy in the supervised setting without adding any extra parameters during inference.
SSR-PR: Single-shot Super-Resolution Phase Retrieval based two prior calibration tests
Aug 12, 2021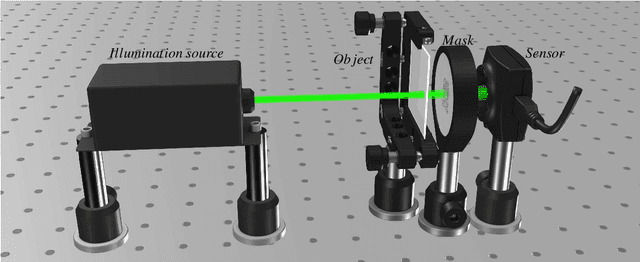


We propose a novel approach and algorithm based on two preliminary tests of the optical system elements to enhance the super-resolved complex-valued imaging. The approach is developed for inverse phase imaging in a single-shot lensless optical setup. Imaging is based on wavefront modulation by a single binary phase mask. The preliminary tests compensate errors in the optical system and correct a carrying wavefront, reducing the gap between real-life experiments and computational modeling, which improve imaging significantly both qualitatively and quantitatively. These two tests are performed for observation of the laser beam and phase mask along, and might be considered as a preliminary system calibration. The corrected carrying wavefront is embedded into the proposed iterative Single-shot Super-Resolution Phase Retrieval (SSR-PR) algorithm. Improved initial diffraction pattern upsampling, and a combination of sparse and deep learning based filters achieves the super-resolved reconstructions. Simulations and physical experiments demonstrate the high-quality super-resolution phase imaging. In the simulations, we showed that the SSR-PR algorithm corrects the errors of the proposed optical system and reconstructs phase details 4x smaller than the sensor pixel size. In physical experiment 2um thick lines of USAF phase-target were resolved, which is almost 2x smaller than the sensor pixel size and corresponds to the smallest resolvable group of used test target. For phase bio-imaging, we provide Buccal Epithelial Cells reconstructed in computational super-resolution and the quality was of the same level as a digital holographic system with 40x magnification objective. Furthermore, the single-shot advantage provides the possibility to record dynamic scenes, where the framerate is limited only by the used camera. We provide amplitude-phase video clip of a moving alive single-celled eukaryote.