 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWorld Reconstruction From Inconsistent Views
Mar 17, 2026Video diffusion models generate high-quality and diverse worlds; however, individual frames often lack 3D consistency across the output sequence, which makes the reconstruction of 3D worlds difficult. To this end, we propose a new method that handles these inconsistencies by non-rigidly aligning the video frames into a globally-consistent coordinate frame that produces sharp and detailed pointcloud reconstructions. First, a geometric foundation model lifts each frame into a pixel-wise 3D pointcloud, which contains unaligned surfaces due to these inconsistencies. We then propose a tailored non-rigid iterative frame-to-model ICP to obtain an initial alignment across all frames, followed by a global optimization that further sharpens the pointcloud. Finally, we leverage this pointcloud as initialization for 3D reconstruction and propose a novel inverse deformation rendering loss to create high quality and explorable 3D environments from inconsistent views. We demonstrate that our 3D scenes achieve higher quality than baselines, effectively turning video models into 3D-consistent world generators.
Intrinsic Image Fusion for Multi-View 3D Material Reconstruction
Dec 15, 2025We introduce Intrinsic Image Fusion, a method that reconstructs high-quality physically based materials from multi-view images. Material reconstruction is highly underconstrained and typically relies on analysis-by-synthesis, which requires expensive and noisy path tracing. To better constrain the optimization, we incorporate single-view priors into the reconstruction process. We leverage a diffusion-based material estimator that produces multiple, but often inconsistent, candidate decompositions per view. To reduce the inconsistency, we fit an explicit low-dimensional parametric function to the predictions. We then propose a robust optimization framework using soft per-view prediction selection together with confidence-based soft multi-view inlier set to fuse the most consistent predictions of the most confident views into a consistent parametric material space. Finally, we use inverse path tracing to optimize for the low-dimensional parameters. Our results outperform state-of-the-art methods in material disentanglement on both synthetic and real scenes, producing sharp and clean reconstructions suitable for high-quality relighting.
QuickSplat: Fast 3D Surface Reconstruction via Learned Gaussian Initialization
May 08, 2025Surface reconstruction is fundamental to computer vision and graphics, enabling applications in 3D modeling, mixed reality, robotics, and more. Existing approaches based on volumetric rendering obtain promising results, but optimize on a per-scene basis, resulting in a slow optimization that can struggle to model under-observed or textureless regions. We introduce QuickSplat, which learns data-driven priors to generate dense initializations for 2D gaussian splatting optimization of large-scale indoor scenes. This provides a strong starting point for the reconstruction, which accelerates the convergence of the optimization and improves the geometry of flat wall structures. We further learn to jointly estimate the densification and update of the scene parameters during each iteration; our proposed densifier network predicts new Gaussians based on the rendering gradients of existing ones, removing the needs of heuristics for densification. Extensive experiments on large-scale indoor scene reconstruction demonstrate the superiority of our data-driven optimization. Concretely, we accelerate runtime by 8x, while decreasing depth errors by up to 48% in comparison to state of the art methods.
IntrinsiX: High-Quality PBR Generation using Image Priors
Apr 01, 2025We introduce IntrinsiX, a novel method that generates high-quality intrinsic images from text description. In contrast to existing text-to-image models whose outputs contain baked-in scene lighting, our approach predicts physically-based rendering (PBR) maps. This enables the generated outputs to be used for content creation scenarios in core graphics applications that facilitate re-lighting, editing, and texture generation tasks. In order to train our generator, we exploit strong image priors, and pre-train separate models for each PBR material component (albedo, roughness, metallic, normals). We then align these models with a new cross-intrinsic attention formulation that concatenates key and value features in a consistent fashion. This allows us to exchange information between each output modality and to obtain semantically coherent PBR predictions. To ground each intrinsic component, we propose a rendering loss which provides image-space signals to constrain the model, thus facilitating sharp details also in the output BRDF properties. Our results demonstrate detailed intrinsic generation with strong generalization capabilities that outperforms existing intrinsic image decomposition methods used with generated images by a significant margin. Finally, we show a series of applications, including re-lighting, editing, and text-conditioned room-scale PBR texture generation.
ViewDiff: 3D-Consistent Image Generation with Text-to-Image Models
Mar 04, 2024



3D asset generation is getting massive amounts of attention, inspired by the recent success of text-guided 2D content creation. Existing text-to-3D methods use pretrained text-to-image diffusion models in an optimization problem or fine-tune them on synthetic data, which often results in non-photorealistic 3D objects without backgrounds. In this paper, we present a method that leverages pretrained text-to-image models as a prior, and learn to generate multi-view images in a single denoising process from real-world data. Concretely, we propose to integrate 3D volume-rendering and cross-frame-attention layers into each block of the existing U-Net network of the text-to-image model. Moreover, we design an autoregressive generation that renders more 3D-consistent images at any viewpoint. We train our model on real-world datasets of objects and showcase its capabilities to generate instances with a variety of high-quality shapes and textures in authentic surroundings. Compared to the existing methods, the results generated by our method are consistent, and have favorable visual quality (-30% FID, -37% KID).
ControlRoom3D: Room Generation using Semantic Proxy Rooms
Dec 08, 2023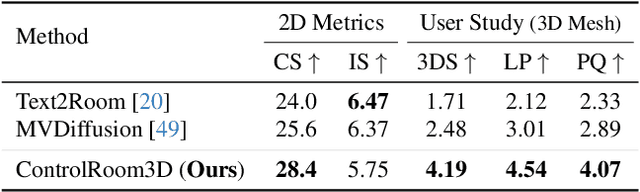
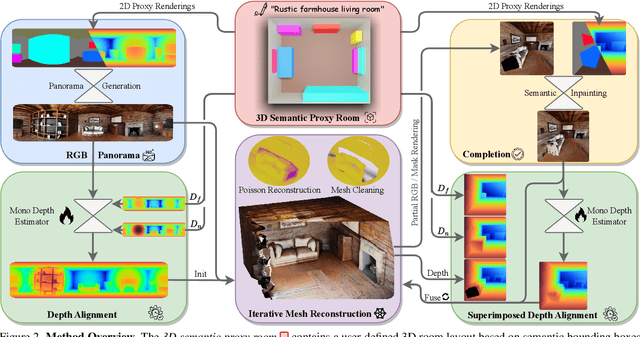
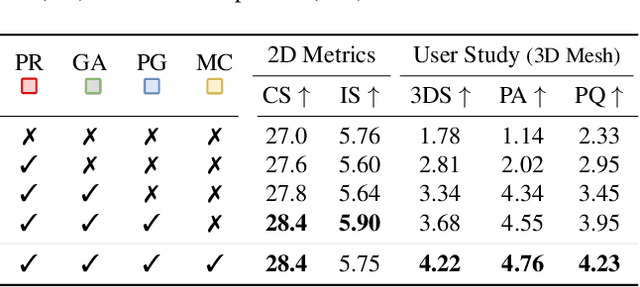
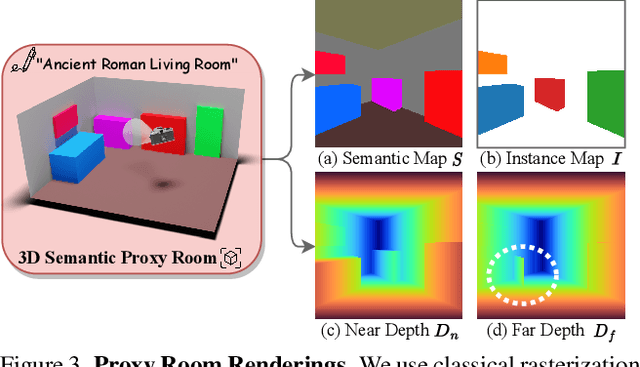
Manually creating 3D environments for AR/VR applications is a complex process requiring expert knowledge in 3D modeling software. Pioneering works facilitate this process by generating room meshes conditioned on textual style descriptions. Yet, many of these automatically generated 3D meshes do not adhere to typical room layouts, compromising their plausibility, e.g., by placing several beds in one bedroom. To address these challenges, we present ControlRoom3D, a novel method to generate high-quality room meshes. Central to our approach is a user-defined 3D semantic proxy room that outlines a rough room layout based on semantic bounding boxes and a textual description of the overall room style. Our key insight is that when rendered to 2D, this 3D representation provides valuable geometric and semantic information to control powerful 2D models to generate 3D consistent textures and geometry that aligns well with the proxy room. Backed up by an extensive study including quantitative metrics and qualitative user evaluations, our method generates diverse and globally plausible 3D room meshes, thus empowering users to design 3D rooms effortlessly without specialized knowledge.
Text2Room: Extracting Textured 3D Meshes from 2D Text-to-Image Models
Mar 21, 2023We present Text2Room, a method for generating room-scale textured 3D meshes from a given text prompt as input. To this end, we leverage pre-trained 2D text-to-image models to synthesize a sequence of images from different poses. In order to lift these outputs into a consistent 3D scene representation, we combine monocular depth estimation with a text-conditioned inpainting model. The core idea of our approach is a tailored viewpoint selection such that the content of each image can be fused into a seamless, textured 3D mesh. More specifically, we propose a continuous alignment strategy that iteratively fuses scene frames with the existing geometry to create a seamless mesh. Unlike existing works that focus on generating single objects or zoom-out trajectories from text, our method generates complete 3D scenes with multiple objects and explicit 3D geometry. We evaluate our approach using qualitative and quantitative metrics, demonstrating it as the first method to generate room-scale 3D geometry with compelling textures from only text as input.
StyleMesh: Style Transfer for Indoor 3D Scene Reconstructions
Dec 02, 2021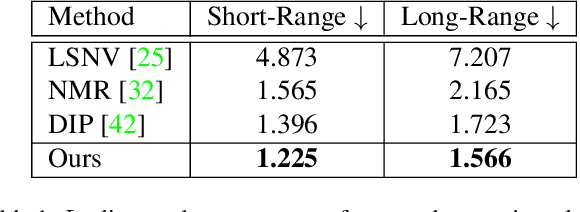
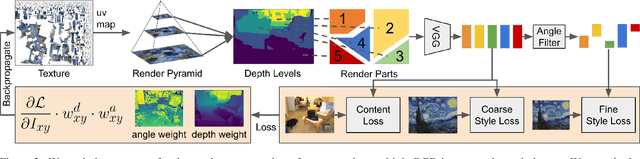
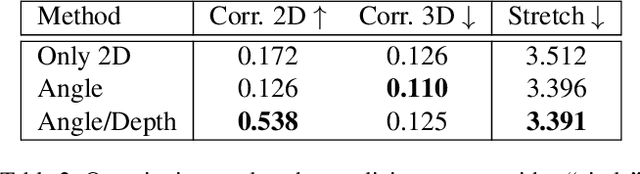
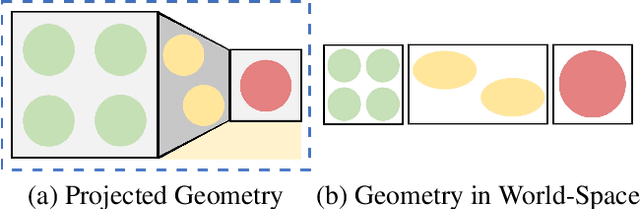
We apply style transfer on mesh reconstructions of indoor scenes. This enables VR applications like experiencing 3D environments painted in the style of a favorite artist. Style transfer typically operates on 2D images, making stylization of a mesh challenging. When optimized over a variety of poses, stylization patterns become stretched out and inconsistent in size. On the other hand, model-based 3D style transfer methods exist that allow stylization from a sparse set of images, but they require a network at inference time. To this end, we optimize an explicit texture for the reconstructed mesh of a scene and stylize it jointly from all available input images. Our depth- and angle-aware optimization leverages surface normal and depth data of the underlying mesh to create a uniform and consistent stylization for the whole scene. Our experiments show that our method creates sharp and detailed results for the complete scene without view-dependent artifacts. Through extensive ablation studies, we show that the proposed 3D awareness enables style transfer to be applied to the 3D domain of a mesh. Our method can be used to render a stylized mesh in real-time with traditional rendering pipelines.