 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynOMo: Online Point Tracking by Dynamic Online Monocular Gaussian Reconstruction
Sep 03, 2024



Reconstructing scenes and tracking motion are two sides of the same coin. Tracking points allow for geometric reconstruction [14], while geometric reconstruction of (dynamic) scenes allows for 3D tracking of points over time [24, 39]. The latter was recently also exploited for 2D point tracking to overcome occlusion ambiguities by lifting tracking directly into 3D [38]. However, above approaches either require offline processing or multi-view camera setups both unrealistic for real-world applications like robot navigation or mixed reality. We target the challenge of online 2D and 3D point tracking from unposed monocular camera input introducing Dynamic Online Monocular Reconstruction (DynOMo). We leverage 3D Gaussian splatting to reconstruct dynamic scenes in an online fashion. Our approach extends 3D Gaussians to capture new content and object motions while estimating camera movements from a single RGB frame. DynOMo stands out by enabling emergence of point trajectories through robust image feature reconstruction and a novel similarity-enhanced regularization term, without requiring any correspondence-level supervision. It sets the first baseline for online point tracking with monocular unposed cameras, achieving performance on par with existing methods. We aim to inspire the community to advance online point tracking and reconstruction, expanding the applicability to diverse real-world scenarios.
SeMoLi: What Moves Together Belongs Together
Feb 29, 2024



We tackle semi-supervised object detection based on motion cues. Recent results suggest that heuristic-based clustering methods in conjunction with object trackers can be used to pseudo-label instances of moving objects and use these as supervisory signals to train 3D object detectors in Lidar data without manual supervision. We re-think this approach and suggest that both, object detection, as well as motion-inspired pseudo-labeling, can be tackled in a data-driven manner. We leverage recent advances in scene flow estimation to obtain point trajectories from which we extract long-term, class-agnostic motion patterns. Revisiting correlation clustering in the context of message passing networks, we learn to group those motion patterns to cluster points to object instances. By estimating the full extent of the objects, we obtain per-scan 3D bounding boxes that we use to supervise a Lidar object detection network. Our method not only outperforms prior heuristic-based approaches (57.5 AP, +14 improvement over prior work), more importantly, we show we can pseudo-label and train object detectors across datasets.
Simple Cues Lead to a Strong Multi-Object Tracker
Jun 13, 2022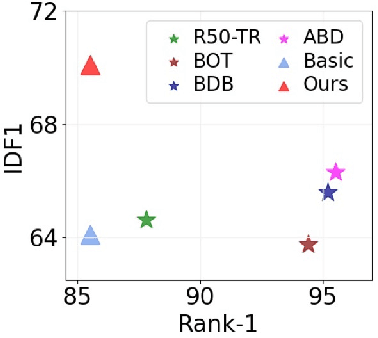

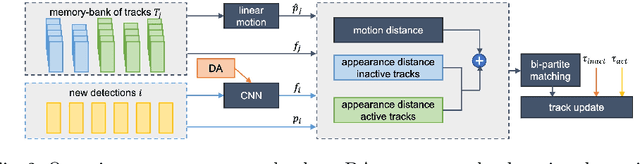
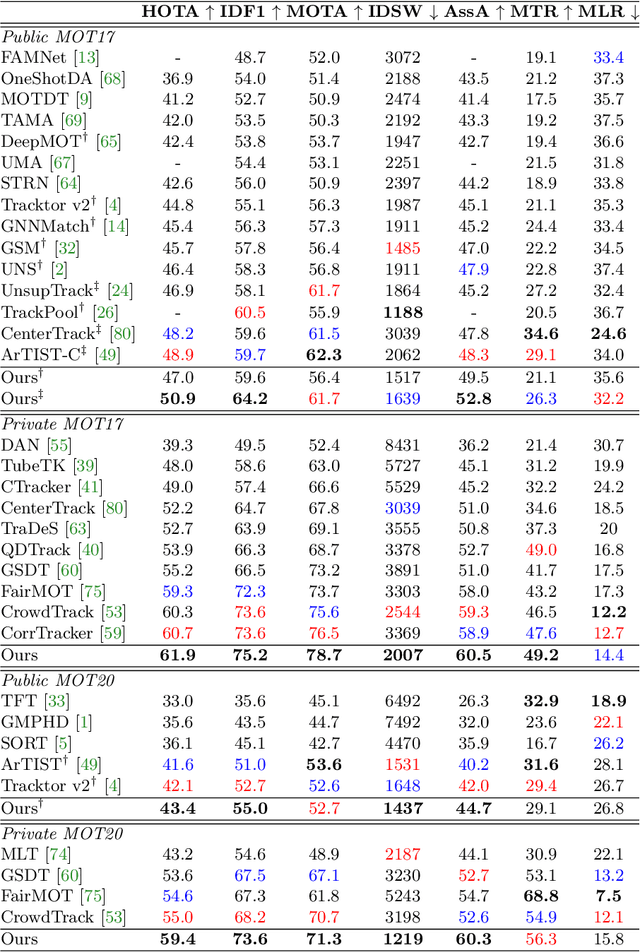
For a long time, the most common paradigm in Multi-Object Tracking was tracking-by-detection (TbD), where objects are first detected and then associated over video frames. For association, most models resource to motion and appearance cues. While still relying on these cues, recent approaches based on, e.g., attention have shown an ever-increasing need for training data and overall complex frameworks. We claim that 1) strong cues can be obtained from little amounts of training data if some key design choices are applied, 2) given these strong cues, standard Hungarian matching-based association is enough to obtain impressive results. Our main insight is to identify key components that allow a standard reidentification network to excel at appearance-based tracking. We extensively analyze its failure cases and show that a combination of our appearance features with a simple motion model leads to strong tracking results. Our model achieves state-of-the-art performance on MOT17 and MOT20 datasets outperforming previous state-of-the-art trackers by up to 5.4pp in IDF1 and 4.4pp in HOTA. We will release the code and models after the paper's acceptance.
The Group Loss++: A deeper look into group loss for deep metric learning
Apr 04, 2022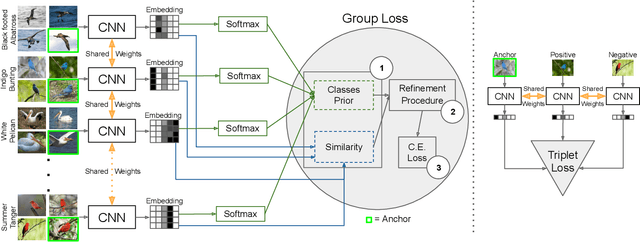
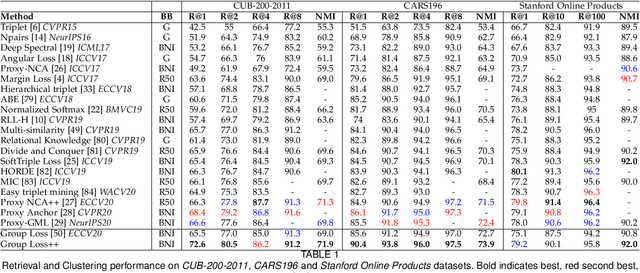
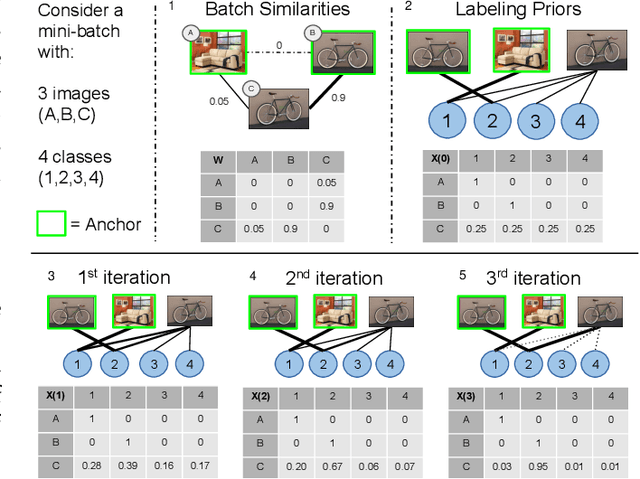
Deep metric learning has yielded impressive results in tasks such as clustering and image retrieval by leveraging neural networks to obtain highly discriminative feature embeddings, which can be used to group samples into different classes. Much research has been devoted to the design of smart loss functions or data mining strategies for training such networks. Most methods consider only pairs or triplets of samples within a mini-batch to compute the loss function, which is commonly based on the distance between embeddings. We propose Group Loss, a loss function based on a differentiable label-propagation method that enforces embedding similarity across all samples of a group while promoting, at the same time, low-density regions amongst data points belonging to different groups. Guided by the smoothness assumption that "similar objects should belong to the same group", the proposed loss trains the neural network for a classification task, enforcing a consistent labelling amongst samples within a class. We design a set of inference strategies tailored towards our algorithm, named Group Loss++ that further improve the results of our model. We show state-of-the-art results on clustering and image retrieval on four retrieval datasets, and present competitive results on two person re-identification datasets, providing a unified framework for retrieval and re-identification.
Learning Intra-Batch Connections for Deep Metric Learning
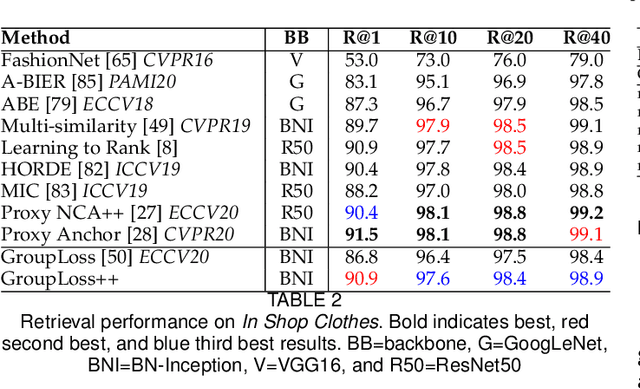
Feb 15, 2021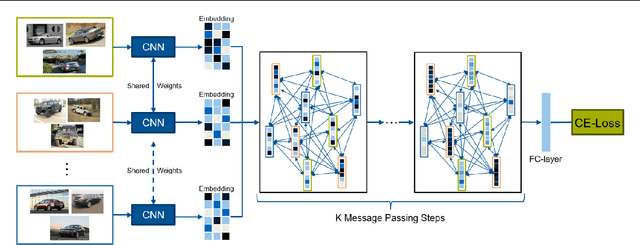
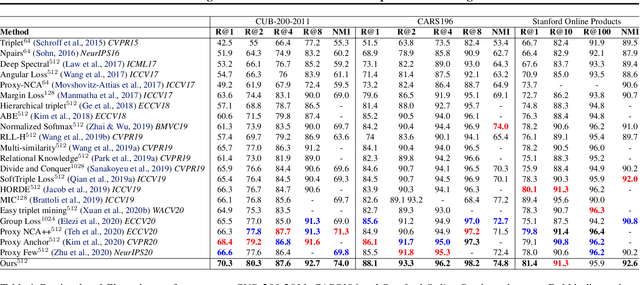
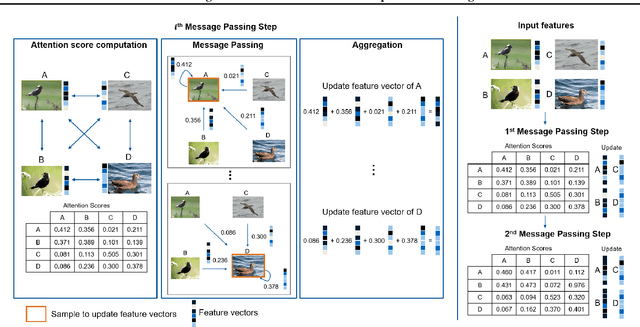
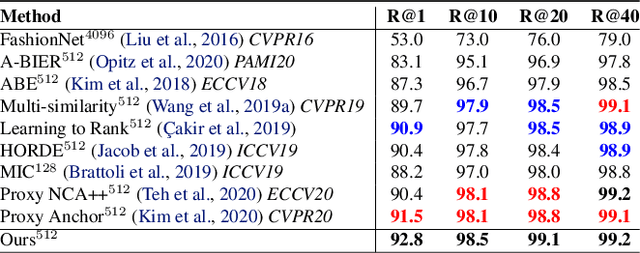
The goal of metric learning is to learn a function that maps samples to a lower-dimensional space where similar samples lie closer than dissimilar ones. In the case of deep metric learning, the mapping is performed by training a neural network. Most approaches rely on losses that only take the relations between pairs or triplets of samples into account, which either belong to the same class or to two different classes. However, these approaches do not explore the embedding space in its entirety. To this end, we propose an approach based on message passing networks that takes into account all the relations in a mini-batch. We refine embedding vectors by exchanging messages among all samples in a given batch allowing the training process to be aware of the overall structure. Since not all samples are equally important to predict a decision boundary, we use dot-product self-attention during message passing to allow samples to weight the importance of each neighbor accordingly. We achieve state-of-the-art results on clustering and image retrieval on the CUB-200-2011, Cars196, Stanford Online Products, and In-Shop Clothes datasets.