 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCrisperWhisper: Accurate Timestamps on Verbatim Speech Transcriptions
Aug 29, 2024We demonstrate that carefully adjusting the tokenizer of the Whisper speech recognition model significantly improves the precision of word-level timestamps when applying dynamic time warping to the decoder's cross-attention scores. We fine-tune the model to produce more verbatim speech transcriptions and employ several techniques to increase robustness against multiple speakers and background noise. These adjustments achieve state-of-the-art performance on benchmarks for verbatim speech transcription, word segmentation, and the timed detection of filler events, and can further mitigate transcription hallucinations. The code is available open https://github.com/nyrahealth/CrisperWhisper.
Careful Whisper -- leveraging advances in automatic speech recognition for robust and interpretable aphasia subtype classification
Aug 02, 2023This paper presents a fully automated approach for identifying speech anomalies from voice recordings to aid in the assessment of speech impairments. By combining Connectionist Temporal Classification (CTC) and encoder-decoder-based automatic speech recognition models, we generate rich acoustic and clean transcripts. We then apply several natural language processing methods to extract features from these transcripts to produce prototypes of healthy speech. Basic distance measures from these prototypes serve as input features for standard machine learning classifiers, yielding human-level accuracy for the distinction between recordings of people with aphasia and a healthy control group. Furthermore, the most frequently occurring aphasia types can be distinguished with 90% accuracy. The pipeline is directly applicable to other diseases and languages, showing promise for robustly extracting diagnostic speech biomarkers.
The Group Loss++: A deeper look into group loss for deep metric learning
Apr 04, 2022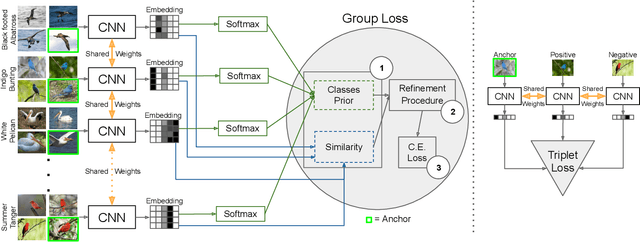
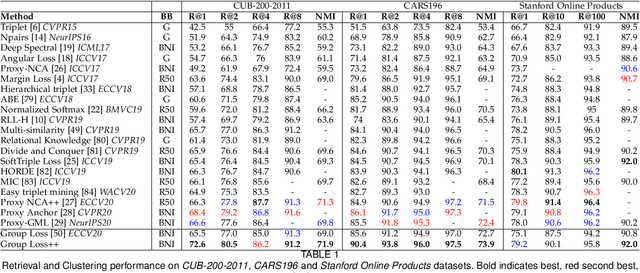
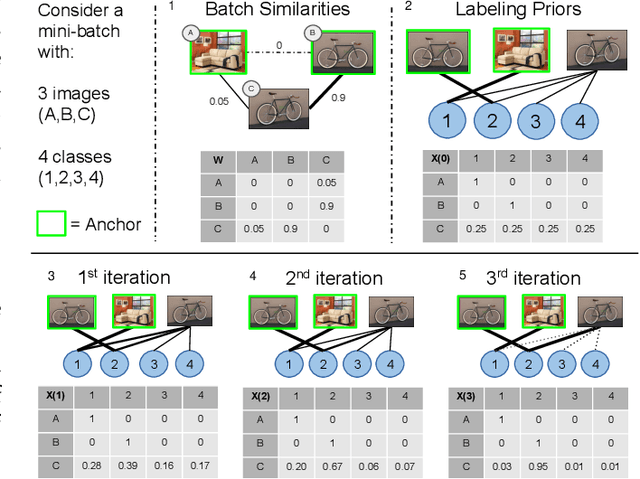
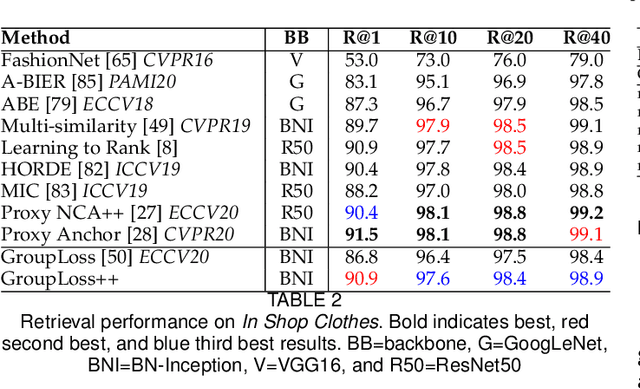
Deep metric learning has yielded impressive results in tasks such as clustering and image retrieval by leveraging neural networks to obtain highly discriminative feature embeddings, which can be used to group samples into different classes. Much research has been devoted to the design of smart loss functions or data mining strategies for training such networks. Most methods consider only pairs or triplets of samples within a mini-batch to compute the loss function, which is commonly based on the distance between embeddings. We propose Group Loss, a loss function based on a differentiable label-propagation method that enforces embedding similarity across all samples of a group while promoting, at the same time, low-density regions amongst data points belonging to different groups. Guided by the smoothness assumption that "similar objects should belong to the same group", the proposed loss trains the neural network for a classification task, enforcing a consistent labelling amongst samples within a class. We design a set of inference strategies tailored towards our algorithm, named Group Loss++ that further improve the results of our model. We show state-of-the-art results on clustering and image retrieval on four retrieval datasets, and present competitive results on two person re-identification datasets, providing a unified framework for retrieval and re-identification.