 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Learning to Complete Anything in Lidar
Apr 16, 2025We propose CAL (Complete Anything in Lidar) for Lidar-based shape-completion in-the-wild. This is closely related to Lidar-based semantic/panoptic scene completion. However, contemporary methods can only complete and recognize objects from a closed vocabulary labeled in existing Lidar datasets. Different to that, our zero-shot approach leverages the temporal context from multi-modal sensor sequences to mine object shapes and semantic features of observed objects. These are then distilled into a Lidar-only instance-level completion and recognition model. Although we only mine partial shape completions, we find that our distilled model learns to infer full object shapes from multiple such partial observations across the dataset. We show that our model can be prompted on standard benchmarks for Semantic and Panoptic Scene Completion, localize objects as (amodal) 3D bounding boxes, and recognize objects beyond fixed class vocabularies. Our project page is https://research.nvidia.com/labs/dvl/projects/complete-anything-lidar
Search3D: Hierarchical Open-Vocabulary 3D Segmentation
Sep 27, 2024
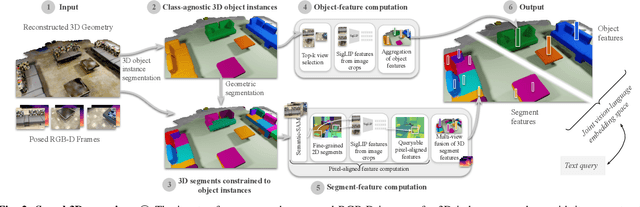
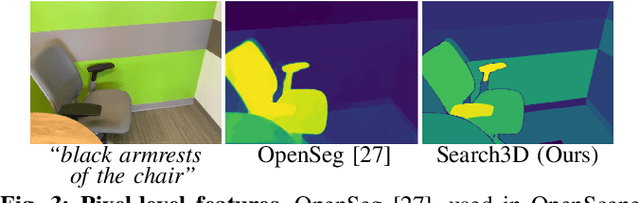

Open-vocabulary 3D segmentation enables the exploration of 3D spaces using free-form text descriptions. Existing methods for open-vocabulary 3D instance segmentation primarily focus on identifying object-level instances in a scene. However, they face challenges when it comes to understanding more fine-grained scene entities such as object parts, or regions described by generic attributes. In this work, we introduce Search3D, an approach that builds a hierarchical open-vocabulary 3D scene representation, enabling the search for entities at varying levels of granularity: fine-grained object parts, entire objects, or regions described by attributes like materials. Our method aims to expand the capabilities of open vocabulary instance-level 3D segmentation by shifting towards a more flexible open-vocabulary 3D search setting less anchored to explicit object-centric queries, compared to prior work. To ensure a systematic evaluation, we also contribute a scene-scale open-vocabulary 3D part segmentation benchmark based on MultiScan, along with a set of open-vocabulary fine-grained part annotations on ScanNet++. We verify the effectiveness of Search3D across several tasks, demonstrating that our approach outperforms baselines in scene-scale open-vocabulary 3D part segmentation, while maintaining strong performance in segmenting 3D objects and materials.
OpenSUN3D: 1st Workshop Challenge on Open-Vocabulary 3D Scene Understanding
Feb 23, 2024


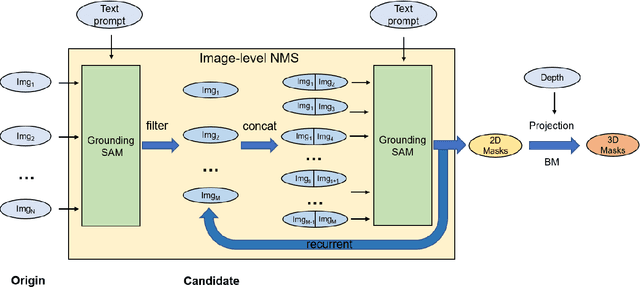
This report provides an overview of the challenge hosted at the OpenSUN3D Workshop on Open-Vocabulary 3D Scene Understanding held in conjunction with ICCV 2023. The goal of this workshop series is to provide a platform for exploration and discussion of open-vocabulary 3D scene understanding tasks, including but not limited to segmentation, detection and mapping. We provide an overview of the challenge hosted at the workshop, present the challenge dataset, the evaluation methodology, and brief descriptions of the winning methods. For additional details, please see https://opensun3d.github.io/index_iccv23.html.
Segment3D: Learning Fine-Grained Class-Agnostic 3D Segmentation without Manual Labels
Dec 28, 2023Current 3D scene segmentation methods are heavily dependent on manually annotated 3D training datasets. Such manual annotations are labor-intensive, and often lack fine-grained details. Importantly, models trained on this data typically struggle to recognize object classes beyond the annotated classes, i.e., they do not generalize well to unseen domains and require additional domain-specific annotations. In contrast, 2D foundation models demonstrate strong generalization and impressive zero-shot abilities, inspiring us to incorporate these characteristics from 2D models into 3D models. Therefore, we explore the use of image segmentation foundation models to automatically generate training labels for 3D segmentation. We propose Segment3D, a method for class-agnostic 3D scene segmentation that produces high-quality 3D segmentation masks. It improves over existing 3D segmentation models (especially on fine-grained masks), and enables easily adding new training data to further boost the segmentation performance -- all without the need for manual training labels.