 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSuperDec: 3D Scene Decomposition with Superquadric Primitives
Apr 01, 2025

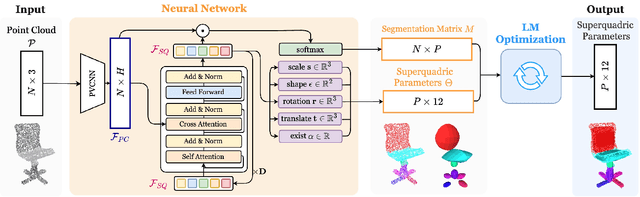

We present SuperDec, an approach for creating compact 3D scene representations via decomposition into superquadric primitives. While most recent works leverage geometric primitives to obtain photorealistic 3D scene representations, we propose to leverage them to obtain a compact yet expressive representation. We propose to solve the problem locally on individual objects and leverage the capabilities of instance segmentation methods to scale our solution to full 3D scenes. In doing that, we design a new architecture which efficiently decompose point clouds of arbitrary objects in a compact set of superquadrics. We train our architecture on ShapeNet and we prove its generalization capabilities on object instances extracted from the ScanNet++ dataset as well as on full Replica scenes. Finally, we show how a compact representation based on superquadrics can be useful for a diverse range of downstream applications, including robotic tasks and controllable visual content generation and editing.
OpenSUN3D: 1st Workshop Challenge on Open-Vocabulary 3D Scene Understanding
Feb 23, 2024


This report provides an overview of the challenge hosted at the OpenSUN3D Workshop on Open-Vocabulary 3D Scene Understanding held in conjunction with ICCV 2023. The goal of this workshop series is to provide a platform for exploration and discussion of open-vocabulary 3D scene understanding tasks, including but not limited to segmentation, detection and mapping. We provide an overview of the challenge hosted at the workshop, present the challenge dataset, the evaluation methodology, and brief descriptions of the winning methods. For additional details, please see https://opensun3d.github.io/index_iccv23.html.
FABRIC: Personalizing Diffusion Models with Iterative Feedback
Jul 19, 2023In an era where visual content generation is increasingly driven by machine learning, the integration of human feedback into generative models presents significant opportunities for enhancing user experience and output quality. This study explores strategies for incorporating iterative human feedback into the generative process of diffusion-based text-to-image models. We propose FABRIC, a training-free approach applicable to a wide range of popular diffusion models, which exploits the self-attention layer present in the most widely used architectures to condition the diffusion process on a set of feedback images. To ensure a rigorous assessment of our approach, we introduce a comprehensive evaluation methodology, offering a robust mechanism to quantify the performance of generative visual models that integrate human feedback. We show that generation results improve over multiple rounds of iterative feedback through exhaustive analysis, implicitly optimizing arbitrary user preferences. The potential applications of these findings extend to fields such as personalized content creation and customization.
OpenMask3D: Open-Vocabulary 3D Instance Segmentation
Jun 23, 2023We introduce the task of open-vocabulary 3D instance segmentation. Traditional approaches for 3D instance segmentation largely rely on existing 3D annotated datasets, which are restricted to a closed-set of object categories. This is an important limitation for real-life applications where one might need to perform tasks guided by novel, open-vocabulary queries related to objects from a wide variety. Recently, open-vocabulary 3D scene understanding methods have emerged to address this problem by learning queryable features per each point in the scene. While such a representation can be directly employed to perform semantic segmentation, existing methods have limitations in their ability to identify object instances. In this work, we address this limitation, and propose OpenMask3D, which is a zero-shot approach for open-vocabulary 3D instance segmentation. Guided by predicted class-agnostic 3D instance masks, our model aggregates per-mask features via multi-view fusion of CLIP-based image embeddings. We conduct experiments and ablation studies on the ScanNet200 dataset to evaluate the performance of OpenMask3D, and provide insights about the open-vocabulary 3D instance segmentation task. We show that our approach outperforms other open-vocabulary counterparts, particularly on the long-tail distribution. Furthermore, OpenMask3D goes beyond the limitations of close-vocabulary approaches, and enables the segmentation of object instances based on free-form queries describing object properties such as semantics, geometry, affordances, and material properties.