 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenMask3D: Open-Vocabulary 3D Instance Segmentation
Jun 23, 2023We introduce the task of open-vocabulary 3D instance segmentation. Traditional approaches for 3D instance segmentation largely rely on existing 3D annotated datasets, which are restricted to a closed-set of object categories. This is an important limitation for real-life applications where one might need to perform tasks guided by novel, open-vocabulary queries related to objects from a wide variety. Recently, open-vocabulary 3D scene understanding methods have emerged to address this problem by learning queryable features per each point in the scene. While such a representation can be directly employed to perform semantic segmentation, existing methods have limitations in their ability to identify object instances. In this work, we address this limitation, and propose OpenMask3D, which is a zero-shot approach for open-vocabulary 3D instance segmentation. Guided by predicted class-agnostic 3D instance masks, our model aggregates per-mask features via multi-view fusion of CLIP-based image embeddings. We conduct experiments and ablation studies on the ScanNet200 dataset to evaluate the performance of OpenMask3D, and provide insights about the open-vocabulary 3D instance segmentation task. We show that our approach outperforms other open-vocabulary counterparts, particularly on the long-tail distribution. Furthermore, OpenMask3D goes beyond the limitations of close-vocabulary approaches, and enables the segmentation of object instances based on free-form queries describing object properties such as semantics, geometry, affordances, and material properties.
3D Segmentation of Humans in Point Clouds with Synthetic Data
Dec 09, 2022Segmenting humans in 3D indoor scenes has become increasingly important with the rise of human-centered robotics and AR/VR applications. In this direction, we explore the tasks of 3D human semantic-, instance- and multi-human body-part segmentation. Few works have attempted to directly segment humans in point clouds (or depth maps), which is largely due to the lack of training data on humans interacting with 3D scenes. We address this challenge and propose a framework for synthesizing virtual humans in realistic 3D scenes. Synthetic point cloud data is attractive since the domain gap between real and synthetic depth is small compared to images. Our analysis of different training schemes using a combination of synthetic and realistic data shows that synthetic data for pre-training improves performance in a wide variety of segmentation tasks and models. We further propose the first end-to-end model for 3D multi-human body-part segmentation, called Human3D, that performs all the above segmentation tasks in a unified manner. Remarkably, Human3D even outperforms previous task-specific state-of-the-art methods. Finally, we manually annotate humans in test scenes from EgoBody to compare the proposed training schemes and segmentation models.
Unsupervised Monocular Depth Reconstruction of Non-Rigid Scenes
Dec 31, 2020
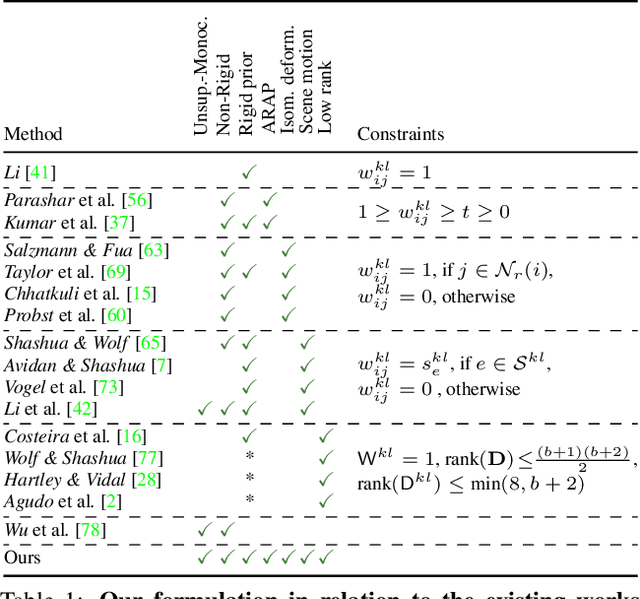
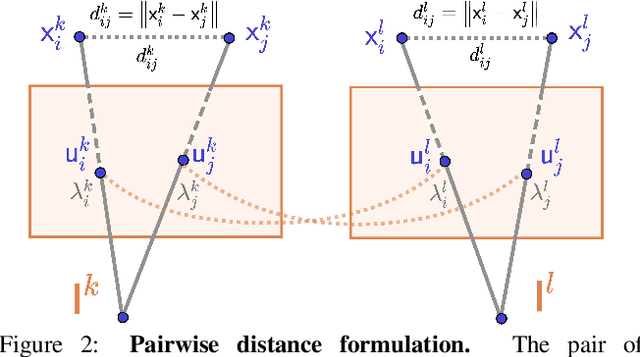
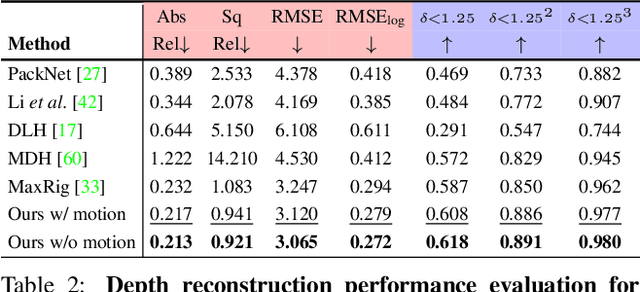
Monocular depth reconstruction of complex and dynamic scenes is a highly challenging problem. While for rigid scenes learning-based methods have been offering promising results even in unsupervised cases, there exists little to no literature addressing the same for dynamic and deformable scenes. In this work, we present an unsupervised monocular framework for dense depth estimation of dynamic scenes, which jointly reconstructs rigid and non-rigid parts without explicitly modelling the camera motion. Using dense correspondences, we derive a training objective that aims to opportunistically preserve pairwise distances between reconstructed 3D points. In this process, the dense depth map is learned implicitly using the as-rigid-as-possible hypothesis. Our method provides promising results, demonstrating its capability of reconstructing 3D from challenging videos of non-rigid scenes. Furthermore, the proposed method also provides unsupervised motion segmentation results as an auxiliary output.