 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOVI-MAP:Open-Vocabulary Instance-Semantic Mapping
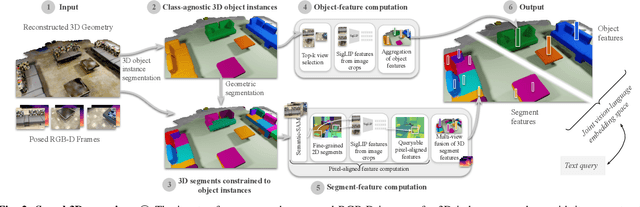
Mar 27, 2026Incremental open-vocabulary 3D instance-semantic mapping is essential for autonomous agents operating in complex everyday environments. However, it remains challenging due to the need for robust instance segmentation, real-time processing, and flexible open-set reasoning. Existing methods often rely on the closed-set assumption or dense per-pixel language fusion, which limits scalability and temporal consistency. We introduce OVI-MAP that decouples instance reconstruction from semantic inference. We propose to build a class-agnostic 3D instance map that is incrementally constructed from RGB-D input, while semantic features are extracted only from a small set of automatically selected views using vision-language models. This design enables stable instance tracking and zero-shot semantic labeling throughout online exploration. Our system operates in real time and outperforms state-of-the-art open-vocabulary mapping baselines on standard benchmarks.
Unified Semantic Transformer for 3D Scene Understanding
Dec 18, 2025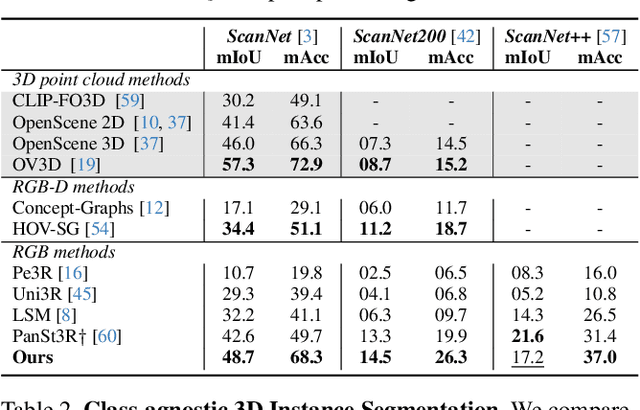
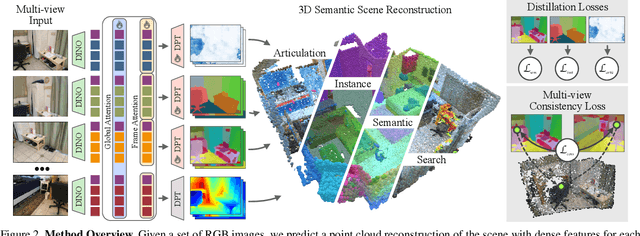
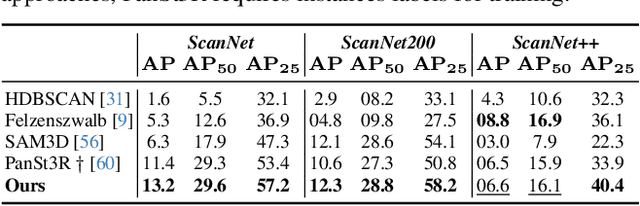
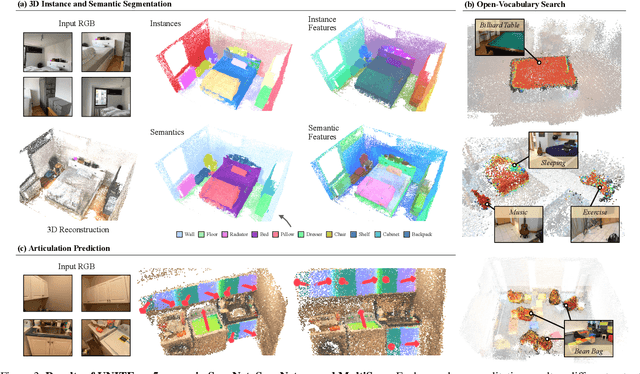
Holistic 3D scene understanding involves capturing and parsing unstructured 3D environments. Due to the inherent complexity of the real world, existing models have predominantly been developed and limited to be task-specific. We introduce UNITE, a Unified Semantic Transformer for 3D scene understanding, a novel feed-forward neural network that unifies a diverse set of 3D semantic tasks within a single model. Our model operates on unseen scenes in a fully end-to-end manner and only takes a few seconds to infer the full 3D semantic geometry. Our approach is capable of directly predicting multiple semantic attributes, including 3D scene segmentation, instance embeddings, open-vocabulary features, as well as affordance and articulations, solely from RGB images. The method is trained using a combination of 2D distillation, heavily relying on self-supervision and leverages novel multi-view losses designed to ensure 3D view consistency. We demonstrate that UNITE achieves state-of-the-art performance on several different semantic tasks and even outperforms task-specific models, in many cases, surpassing methods that operate on ground truth 3D geometry. See the project website at unite-page.github.io
RelationField: Relate Anything in Radiance Fields
Dec 18, 2024



Neural radiance fields are an emerging 3D scene representation and recently even been extended to learn features for scene understanding by distilling open-vocabulary features from vision-language models. However, current method primarily focus on object-centric representations, supporting object segmentation or detection, while understanding semantic relationships between objects remains largely unexplored. To address this gap, we propose RelationField, the first method to extract inter-object relationships directly from neural radiance fields. RelationField represents relationships between objects as pairs of rays within a neural radiance field, effectively extending its formulation to include implicit relationship queries. To teach RelationField complex, open-vocabulary relationships, relationship knowledge is distilled from multi-modal LLMs. To evaluate RelationField, we solve open-vocabulary 3D scene graph generation tasks and relationship-guided instance segmentation, achieving state-of-the-art performance in both tasks. See the project website at https://relationfield.github.io.
Search3D: Hierarchical Open-Vocabulary 3D Segmentation
Sep 27, 2024
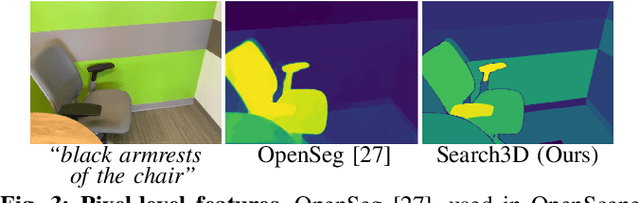

Open-vocabulary 3D segmentation enables the exploration of 3D spaces using free-form text descriptions. Existing methods for open-vocabulary 3D instance segmentation primarily focus on identifying object-level instances in a scene. However, they face challenges when it comes to understanding more fine-grained scene entities such as object parts, or regions described by generic attributes. In this work, we introduce Search3D, an approach that builds a hierarchical open-vocabulary 3D scene representation, enabling the search for entities at varying levels of granularity: fine-grained object parts, entire objects, or regions described by attributes like materials. Our method aims to expand the capabilities of open vocabulary instance-level 3D segmentation by shifting towards a more flexible open-vocabulary 3D search setting less anchored to explicit object-centric queries, compared to prior work. To ensure a systematic evaluation, we also contribute a scene-scale open-vocabulary 3D part segmentation benchmark based on MultiScan, along with a set of open-vocabulary fine-grained part annotations on ScanNet++. We verify the effectiveness of Search3D across several tasks, demonstrating that our approach outperforms baselines in scene-scale open-vocabulary 3D part segmentation, while maintaining strong performance in segmenting 3D objects and materials.
OpenSUN3D: 1st Workshop Challenge on Open-Vocabulary 3D Scene Understanding
Feb 23, 2024


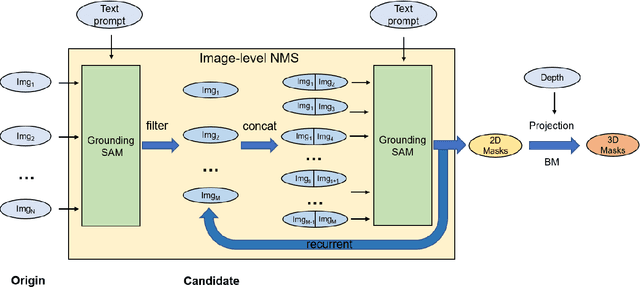
This report provides an overview of the challenge hosted at the OpenSUN3D Workshop on Open-Vocabulary 3D Scene Understanding held in conjunction with ICCV 2023. The goal of this workshop series is to provide a platform for exploration and discussion of open-vocabulary 3D scene understanding tasks, including but not limited to segmentation, detection and mapping. We provide an overview of the challenge hosted at the workshop, present the challenge dataset, the evaluation methodology, and brief descriptions of the winning methods. For additional details, please see https://opensun3d.github.io/index_iccv23.html.
From 2D to 3D: Re-thinking Benchmarking of Monocular Depth Prediction
Mar 15, 2022
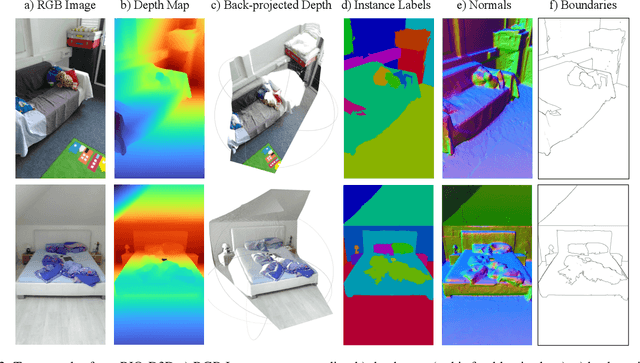
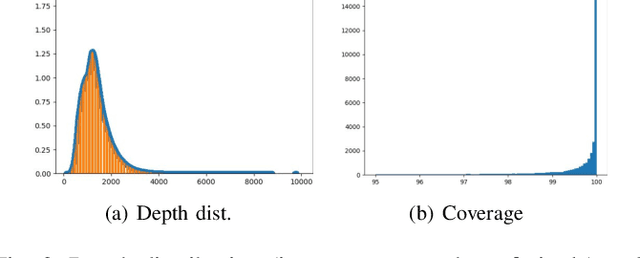

There have been numerous recently proposed methods for monocular depth prediction (MDP) coupled with the equally rapid evolution of benchmarking tools. However, we argue that MDP is currently witnessing benchmark over-fitting and relying on metrics that are only partially helpful to gauge the usefulness of the predictions for 3D applications. This limits the design and development of novel methods that are truly aware of - and improving towards estimating - the 3D structure of the scene rather than optimizing 2D-based distances. In this work, we aim to bring structural awareness to MDP, an inherently 3D task, by exhibiting the limits of evaluation metrics towards assessing the quality of the 3D geometry. We propose a set of metrics well suited to evaluate the 3D geometry of MDP approaches and a novel indoor benchmark, RIO-D3D, crucial for the proposed evaluation methodology. Our benchmark is based on a real-world dataset featuring high-quality rendered depth maps obtained from RGB-D reconstructions. We further demonstrate this to help benchmark the closely-tied task of 3D scene completion.
SceneGraphFusion: Incremental 3D Scene Graph Prediction from RGB-D Sequences
Mar 31, 2021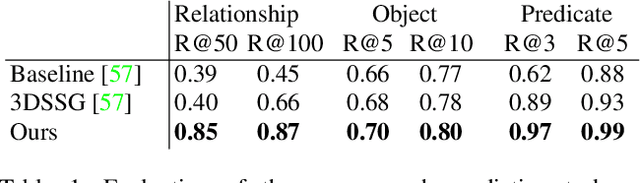
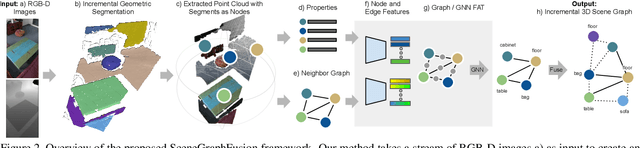
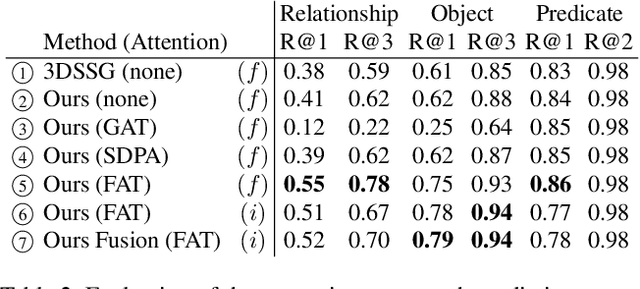
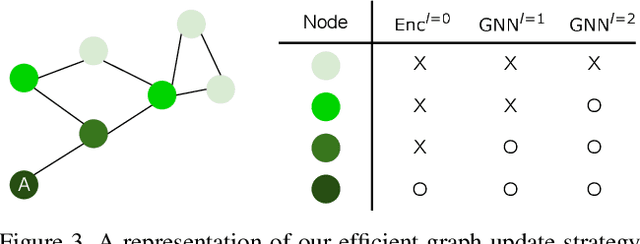
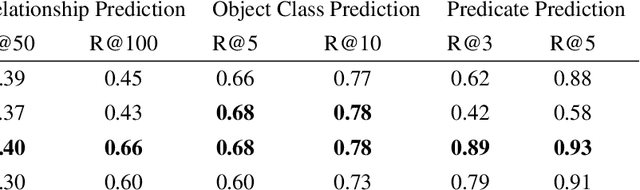
Scene graphs are a compact and explicit representation successfully used in a variety of 2D scene understanding tasks. This work proposes a method to incrementally build up semantic scene graphs from a 3D environment given a sequence of RGB-D frames. To this end, we aggregate PointNet features from primitive scene components by means of a graph neural network. We also propose a novel attention mechanism well suited for partial and missing graph data present in such an incremental reconstruction scenario. Although our proposed method is designed to run on submaps of the scene, we show it also transfers to entire 3D scenes. Experiments show that our approach outperforms 3D scene graph prediction methods by a large margin and its accuracy is on par with other 3D semantic and panoptic segmentation methods while running at 35 Hz.
Beyond Controlled Environments: 3D Camera Re-Localization in Changing Indoor Scenes
Aug 05, 2020
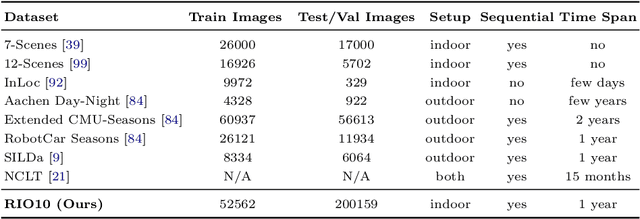
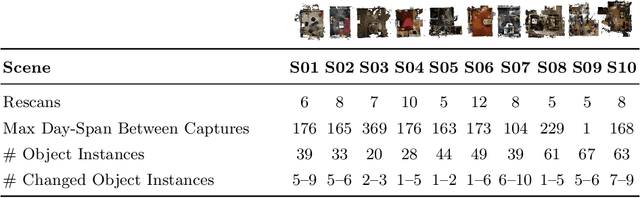

Long-term camera re-localization is an important task with numerous computer vision and robotics applications. Whilst various outdoor benchmarks exist that target lighting, weather and seasonal changes, far less attention has been paid to appearance changes that occur indoors. This has led to a mismatch between popular indoor benchmarks, which focus on static scenes, and indoor environments that are of interest for many real-world applications. In this paper, we adapt 3RScan - a recently introduced indoor RGB-D dataset designed for object instance re-localization - to create RIO10, a new long-term camera re-localization benchmark focused on indoor scenes. We propose new metrics for evaluating camera re-localization and explore how state-of-the-art camera re-localizers perform according to these metrics. We also examine in detail how different types of scene change affect the performance of different methods, based on novel ways of detecting such changes in a given RGB-D frame. Our results clearly show that long-term indoor re-localization is an unsolved problem. Our benchmark and tools are publicly available at waldjohannau.github.io/RIO10
Learning 3D Semantic Scene Graphs from 3D Indoor Reconstructions
Apr 08, 2020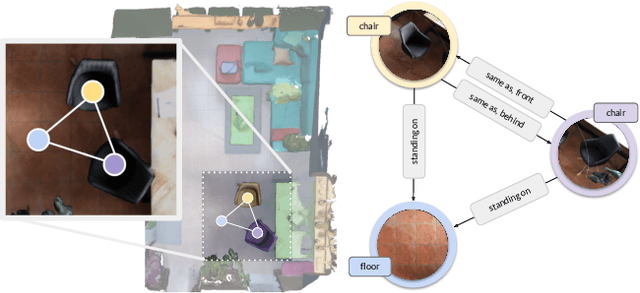

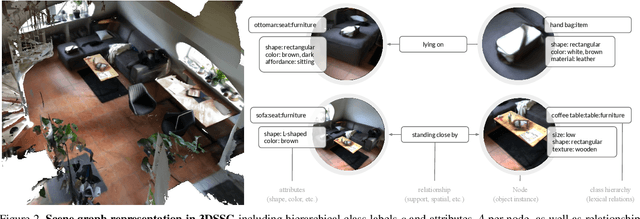
Scene understanding has been of high interest in computer vision. It encompasses not only identifying objects in a scene, but also their relationships within the given context. With this goal, a recent line of works tackles 3D semantic segmentation and scene layout prediction. In our work we focus on scene graphs, a data structure that organizes the entities of a scene in a graph, where objects are nodes and their relationships modeled as edges. We leverage inference on scene graphs as a way to carry out 3D scene understanding, mapping objects and their relationships. In particular, we propose a learned method that regresses a scene graph from the point cloud of a scene. Our novel architecture is based on PointNet and Graph Convolutional Networks (GCN). In addition, we introduce 3DSSG, a semi-automatically generated dataset, that contains semantically rich scene graphs of 3D scenes. We show the application of our method in a domain-agnostic retrieval task, where graphs serve as an intermediate representation for 3D-3D and 2D-3D matching.
RIO: 3D Object Instance Re-Localization in Changing Indoor Environments
Aug 16, 2019

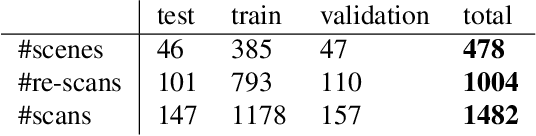
In this work, we introduce the task of 3D object instance re-localization (RIO): given one or multiple objects in an RGB-D scan, we want to estimate their corresponding 6DoF poses in another 3D scan of the same environment taken at a later point in time. We consider RIO a particularly important task in 3D vision since it enables a wide range of practical applications, including AI-assistants or robots that are asked to find a specific object in a 3D scene. To address this problem, we first introduce 3RScan, a novel dataset and benchmark, which features 1482 RGB-D scans of 478 environments across multiple time steps. Each scene includes several objects whose positions change over time, together with ground truth annotations of object instances and their respective 6DoF mappings among re-scans. Automatically finding 6DoF object poses leads to a particular challenging feature matching task due to varying partial observations and changes in the surrounding context. To this end, we introduce a new data-driven approach that efficiently finds matching features using a fully-convolutional 3D correspondence network operating on multiple spatial scales. Combined with a 6DoF pose optimization, our method outperforms state-of-the-art baselines on our newly-established benchmark, achieving an accuracy of 30.58%.