 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEchoScene: Indoor Scene Generation via Information Echo over Scene Graph Diffusion
May 02, 2024We present EchoScene, an interactive and controllable generative model that generates 3D indoor scenes on scene graphs. EchoScene leverages a dual-branch diffusion model that dynamically adapts to scene graphs. Existing methods struggle to handle scene graphs due to varying numbers of nodes, multiple edge combinations, and manipulator-induced node-edge operations. EchoScene overcomes this by associating each node with a denoising process and enables collaborative information exchange, enhancing controllable and consistent generation aware of global constraints. This is achieved through an information echo scheme in both shape and layout branches. At every denoising step, all processes share their denoising data with an information exchange unit that combines these updates using graph convolution. The scheme ensures that the denoising processes are influenced by a holistic understanding of the scene graph, facilitating the generation of globally coherent scenes. The resulting scenes can be manipulated during inference by editing the input scene graph and sampling the noise in the diffusion model. Extensive experiments validate our approach, which maintains scene controllability and surpasses previous methods in generation fidelity. Moreover, the generated scenes are of high quality and thus directly compatible with off-the-shelf texture generation. Code and trained models are open-sourced.
FoundPose: Unseen Object Pose Estimation with Foundation Features
Nov 30, 2023



We propose FoundPose, a method for 6D pose estimation of unseen rigid objects from a single RGB image. The method assumes that 3D models of the objects are available but does not require any object-specific training. This is achieved by building upon DINOv2, a recent vision foundation model with impressive generalization capabilities. An online pose estimation stage is supported by a minimal object representation that is built during a short onboarding stage from DINOv2 patch features extracted from rendered object templates. Given a query image with an object segmentation mask, FoundPose first rapidly retrieves a handful of similarly looking templates by a DINOv2-based bag-of-words approach. Pose hypotheses are then generated from 2D-3D correspondences established by matching DINOv2 patch features between the query image and a retrieved template, and finally optimized by featuremetric refinement. The method can handle diverse objects, including challenging ones with symmetries and without any texture, and noticeably outperforms existing RGB methods for coarse pose estimation in both accuracy and speed on the standard BOP benchmark. With the featuremetric and additional MegaPose refinement, which are demonstrated complementary, the method outperforms all RGB competitors. Source code is at: evinpinar.github.io/foundpose.
SupeRGB-D: Zero-shot Instance Segmentation in Cluttered Indoor Environments
Dec 22, 2022



Object instance segmentation is a key challenge for indoor robots navigating cluttered environments with many small objects. Limitations in 3D sensing capabilities often make it difficult to detect every possible object. While deep learning approaches may be effective for this problem, manually annotating 3D data for supervised learning is time-consuming. In this work, we explore zero-shot instance segmentation (ZSIS) from RGB-D data to identify unseen objects in a semantic category-agnostic manner. We introduce a zero-shot split for Tabletop Objects Dataset (TOD-Z) to enable this study and present a method that uses annotated objects to learn the ``objectness'' of pixels and generalize to unseen object categories in cluttered indoor environments. Our method, SupeRGB-D, groups pixels into small patches based on geometric cues and learns to merge the patches in a deep agglomerative clustering fashion. SupeRGB-D outperforms existing baselines on unseen objects while achieving similar performance on seen objects. Additionally, it is extremely lightweight (0.4 MB memory requirement) and suitable for mobile and robotic applications. The dataset split and code will be made publicly available upon acceptance.
LatentSwap3D: Semantic Edits on 3D Image GANs
Dec 02, 2022



Recent 3D-aware GANs rely on volumetric rendering techniques to disentangle the pose and appearance of objects, de facto generating entire 3D volumes rather than single-view 2D images from a latent code. Complex image editing tasks can be performed in standard 2D-based GANs (e.g., StyleGAN models) as manipulation of latent dimensions. However, to the best of our knowledge, similar properties have only been partially explored for 3D-aware GAN models. This work aims to fill this gap by showing the limitations of existing methods and proposing LatentSwap3D, a model-agnostic approach designed to enable attribute editing in the latent space of pre-trained 3D-aware GANs. We first identify the most relevant dimensions in the latent space of the model controlling the targeted attribute by relying on the feature importance ranking of a random forest classifier. Then, to apply the transformation, we swap the top-K most relevant latent dimensions of the image being edited with an image exhibiting the desired attribute. Despite its simplicity, LatentSwap3D provides remarkable semantic edits in a disentangled manner and outperforms alternative approaches both qualitatively and quantitatively. We demonstrate our semantic edit approach on various 3D-aware generative models such as pi-GAN, GIRAFFE, StyleSDF, MVCGAN, EG3D and VolumeGAN, and on diverse datasets, such as FFHQ, AFHQ, Cats, MetFaces, and CompCars. The project page can be found: \url{https://enisimsar.github.io/latentswap3d/}.
4D-OR: Semantic Scene Graphs for OR Domain Modeling
Mar 22, 2022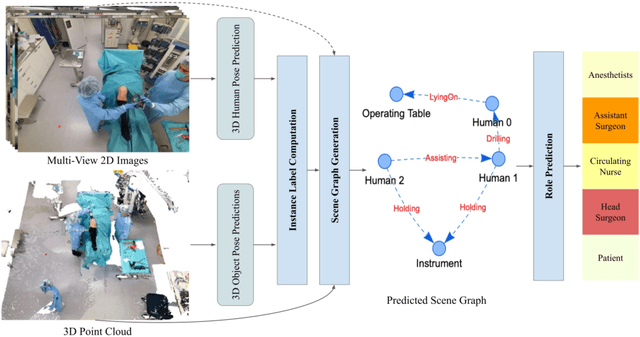


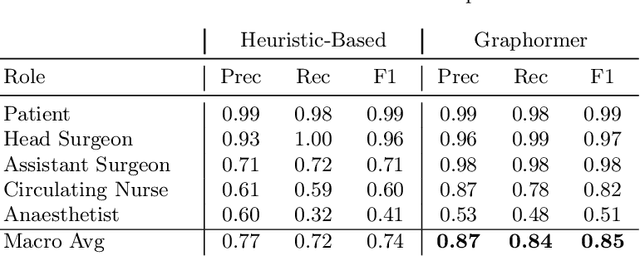
Surgical procedures are conducted in highly complex operating rooms (OR), comprising different actors, devices, and interactions. To date, only medically trained human experts are capable of understanding all the links and interactions in such a demanding environment. This paper aims to bring the community one step closer to automated, holistic and semantic understanding and modeling of OR domain. Towards this goal, for the first time, we propose using semantic scene graphs (SSG) to describe and summarize the surgical scene. The nodes of the scene graphs represent different actors and objects in the room, such as medical staff, patients, and medical equipment, whereas edges are the relationships between them. To validate the possibilities of the proposed representation, we create the first publicly available 4D surgical SSG dataset, 4D-OR, containing ten simulated total knee replacement surgeries recorded with six RGB-D sensors in a realistic OR simulation center. 4D-OR includes 6734 frames and is richly annotated with SSGs, human and object poses, and clinical roles. We propose an end-to-end neural network-based SSG generation pipeline, with a rate of success of 0.75 macro F1, indeed being able to infer semantic reasoning in the OR. We further demonstrate the representation power of our scene graphs by using it for the problem of clinical role prediction, where we achieve 0.85 macro F1. The code and dataset will be made available upon acceptance.
From 2D to 3D: Re-thinking Benchmarking of Monocular Depth Prediction
Mar 15, 2022
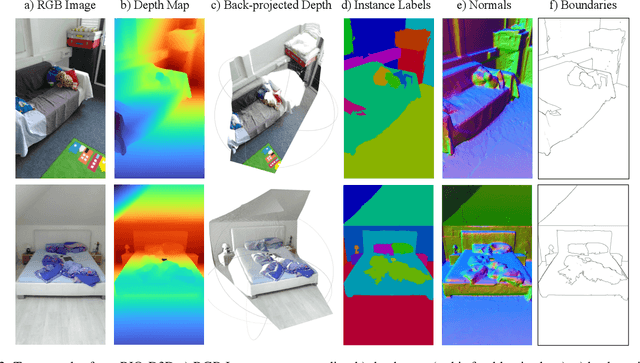
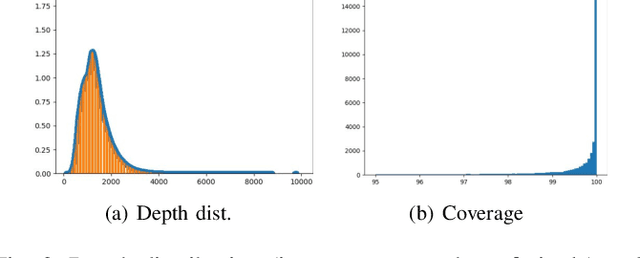

There have been numerous recently proposed methods for monocular depth prediction (MDP) coupled with the equally rapid evolution of benchmarking tools. However, we argue that MDP is currently witnessing benchmark over-fitting and relying on metrics that are only partially helpful to gauge the usefulness of the predictions for 3D applications. This limits the design and development of novel methods that are truly aware of - and improving towards estimating - the 3D structure of the scene rather than optimizing 2D-based distances. In this work, we aim to bring structural awareness to MDP, an inherently 3D task, by exhibiting the limits of evaluation metrics towards assessing the quality of the 3D geometry. We propose a set of metrics well suited to evaluate the 3D geometry of MDP approaches and a novel indoor benchmark, RIO-D3D, crucial for the proposed evaluation methodology. Our benchmark is based on a real-world dataset featuring high-quality rendered depth maps obtained from RGB-D reconstructions. We further demonstrate this to help benchmark the closely-tied task of 3D scene completion.
Object-aware Monocular Depth Prediction with Instance Convolutions
Dec 02, 2021



With the advent of deep learning, estimating depth from a single RGB image has recently received a lot of attention, being capable of empowering many different applications ranging from path planning for robotics to computational cinematography. Nevertheless, while the depth maps are in their entirety fairly reliable, the estimates around object discontinuities are still far from satisfactory. This can be contributed to the fact that the convolutional operator naturally aggregates features across object discontinuities, resulting in smooth transitions rather than clear boundaries. Therefore, in order to circumvent this issue, we propose a novel convolutional operator which is explicitly tailored to avoid feature aggregation of different object parts. In particular, our method is based on estimating per-part depth values by means of superpixels. The proposed convolutional operator, which we dub "Instance Convolution", then only considers each object part individually on the basis of the estimated superpixels. Our evaluation with respect to the NYUv2 as well as the iBims dataset clearly demonstrates the superiority of Instance Convolutions over the classical convolution at estimating depth around occlusion boundaries, while producing comparable results elsewhere. Code will be made publicly available upon acceptance.
3D Compositional Zero-shot Learning with DeCompositional Consensus
Nov 29, 2021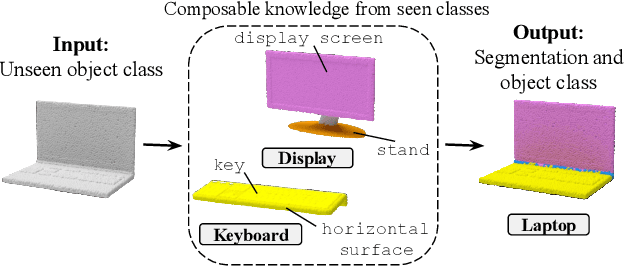
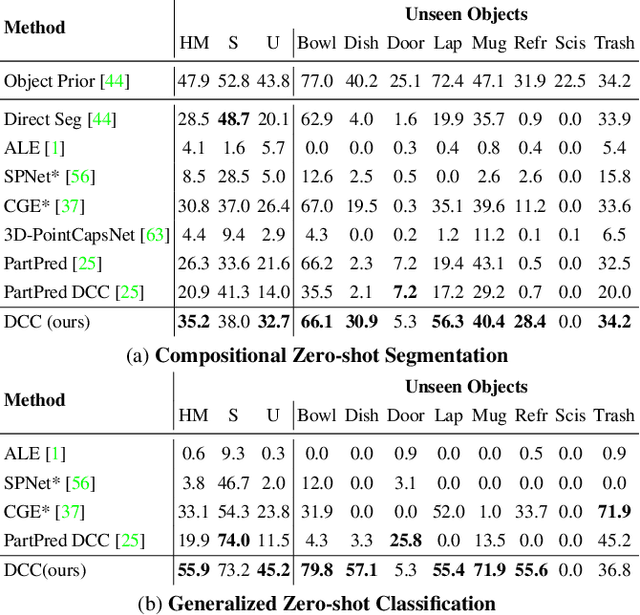
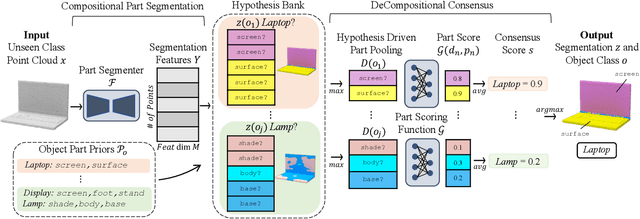
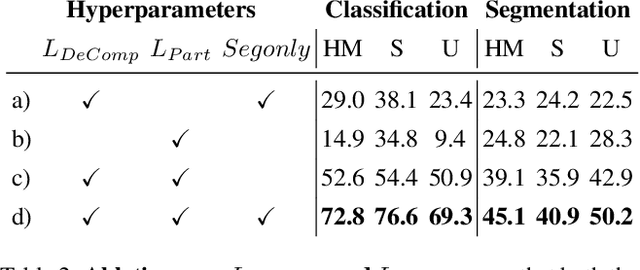
Parts represent a basic unit of geometric and semantic similarity across different objects. We argue that part knowledge should be composable beyond the observed object classes. Towards this, we present 3D Compositional Zero-shot Learning as a problem of part generalization from seen to unseen object classes for semantic segmentation. We provide a structured study through benchmarking the task with the proposed Compositional-PartNet dataset. This dataset is created by processing the original PartNet to maximize part overlap across different objects. The existing point cloud part segmentation methods fail to generalize to unseen object classes in this setting. As a solution, we propose DeCompositional Consensus, which combines a part segmentation network with a part scoring network. The key intuition to our approach is that a segmentation mask over some parts should have a consensus with its part scores when each part is taken apart. The two networks reason over different part combinations defined in a per-object part prior to generate the most suitable segmentation mask. We demonstrate that our method allows compositional zero-shot segmentation and generalized zero-shot classification, and establishes the state of the art on both tasks.
Multimodal Semantic Scene Graphs for Holistic Modeling of Surgical Procedures
Jun 09, 2021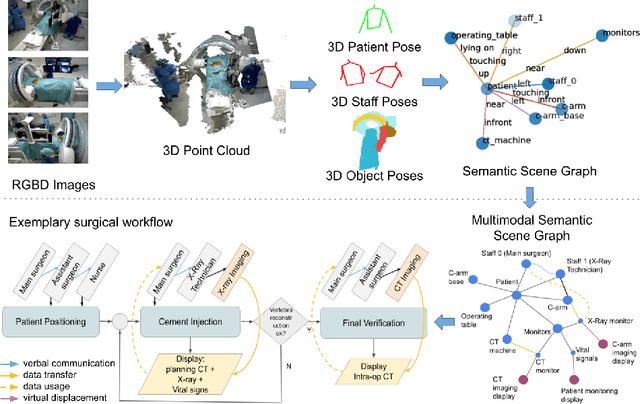
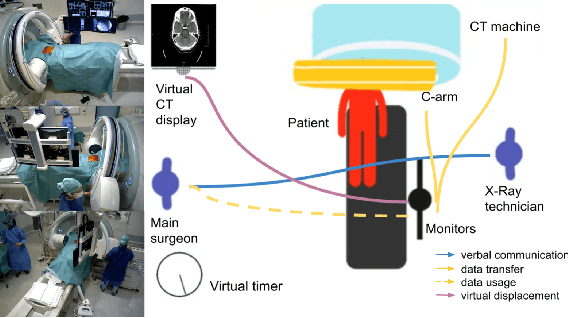
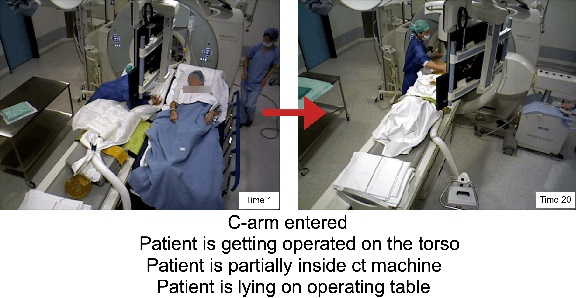
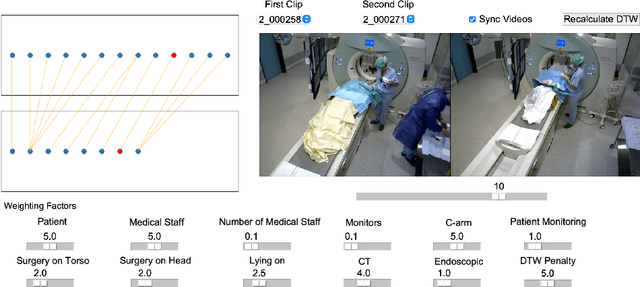
From a computer science viewpoint, a surgical domain model needs to be a conceptual one incorporating both behavior and data. It should therefore model actors, devices, tools, their complex interactions and data flow. To capture and model these, we take advantage of the latest computer vision methodologies for generating 3D scene graphs from camera views. We then introduce the Multimodal Semantic Scene Graph (MSSG) which aims at providing a unified symbolic, spatiotemporal and semantic representation of surgical procedures. This methodology aims at modeling the relationship between different components in surgical domain including medical staff, imaging systems, and surgical devices, opening the path towards holistic understanding and modeling of surgical procedures. We then use MSSG to introduce a dynamically generated graphical user interface tool for surgical procedure analysis which could be used for many applications including process optimization, OR design and automatic report generation. We finally demonstrate that the proposed MSSGs could also be used for synchronizing different complex surgical procedures. While the system still needs to be integrated into real operating rooms before getting validated, this conference paper aims mainly at providing the community with the basic principles of this novel concept through a first prototypal partial realization based on MVOR dataset.
Co-Planar Parametrization for Stereo-SLAM and Visual-Inertial Odometry
Sep 26, 2020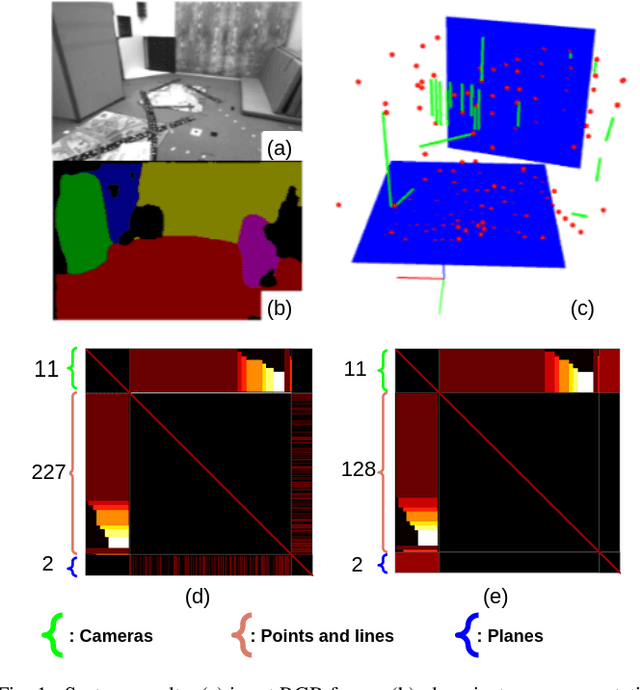
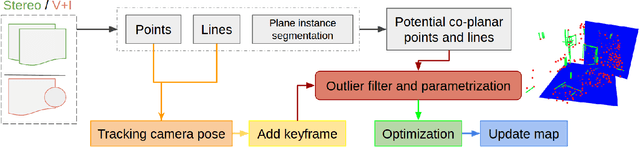
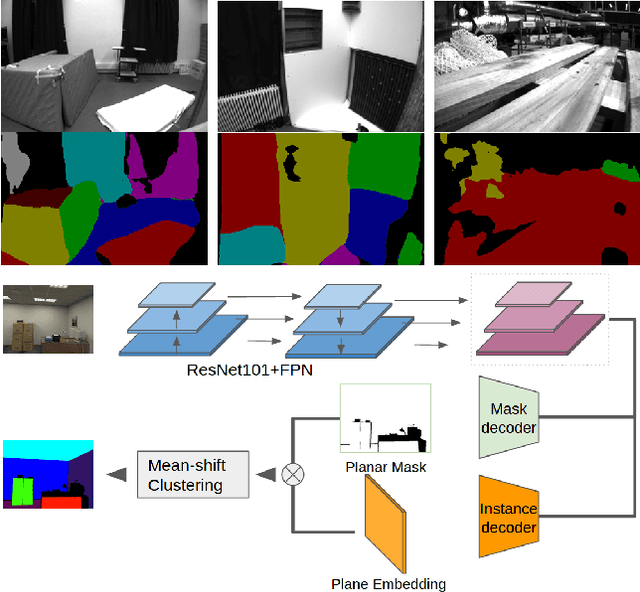
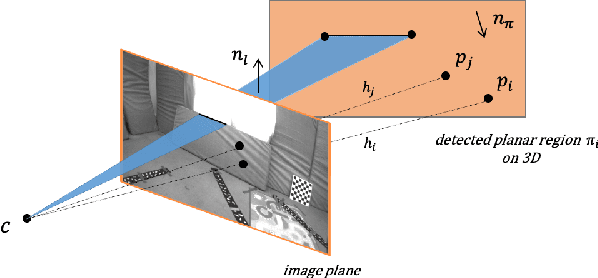
This work proposes a novel SLAM framework for stereo and visual inertial odometry estimation. It builds an efficient and robust parametrization of co-planar points and lines which leverages specific geometric constraints to improve camera pose optimization in terms of both efficiency and accuracy. %reduce the size of the Hessian matrix in the optimization. The pipeline consists of extracting 2D points and lines, predicting planar regions and filtering the outliers via RANSAC. Our parametrization scheme then represents co-planar points and lines as their 2D image coordinates and parameters of planes. We demonstrate the effectiveness of the proposed method by comparing it to traditional parametrizations in a novel Monte-Carlo simulation set. Further, the whole stereo SLAM and VIO system is compared with state-of-the-art methods on the public real-world dataset EuRoC. Our method shows better results in terms of accuracy and efficiency than the state-of-the-art. The code is released at https://github.com/LiXin97/Co-Planar-Parametrization.