 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFeasibility of Augmented Reality-Guided Robotic Ultrasound with Cone-Beam CT Integration for Spine Procedures
Mar 23, 2026Accurate needle placement in spine interventions is critical for effective pain management, yet it depends on reliable identification of anatomical landmarks and careful trajectory planning. Conventional imaging guidance often relies both on CT and X-ray fluoroscopy, exposing patients and staff to high dose of radiation while providing limited real-time 3D feedback. We present an optical see-through augmented reality (OST-AR)-guided robotic system for spine procedures that provides in situ visualization of spinal structures to support needle trajectory planning. We integrate a cone-beam CT (CBCT)-derived 3D spine model which is co-registered with live ultrasound, enabling users to combine global anatomical context with local, real-time imaging. We evaluated the system in a phantom user study involving two representative spine procedures: facet joint injection and lumbar puncture. Sixteen participants performed insertions under two visualization conditions: conventional screen vs. AR. Results show that AR significantly reduces execution time and across-task placement error, while also improving usability, trust, and spatial understanding and lowering cognitive workload. These findings demonstrate the feasibility of AR-guided robotic ultrasound for spine interventions, highlighting its potential to enhance accuracy, efficiency, and user experience in image-guided procedures.
Hybrid Foveated Path Tracing with Peripheral Gaussians for Immersive Anatomy
Jan 29, 2026Volumetric medical imaging offers great potential for understanding complex pathologies. Yet, traditional 2D slices provide little support for interpreting spatial relationships, forcing users to mentally reconstruct anatomy into three dimensions. Direct volumetric path tracing and VR rendering can improve perception but are computationally expensive, while precomputed representations, like Gaussian Splatting, require planning ahead. Both approaches limit interactive use. We propose a hybrid rendering approach for high-quality, interactive, and immersive anatomical visualization. Our method combines streamed foveated path tracing with a lightweight Gaussian Splatting approximation of the periphery. The peripheral model generation is optimized with volume data and continuously refined using foveal renderings, enabling interactive updates. Depth-guided reprojection further improves robustness to latency and allows users to balance fidelity with refresh rate. We compare our method against direct path tracing and Gaussian Splatting. Our results highlight how their combination can preserve strengths in visual quality while re-generating the peripheral model in under a second, eliminating extensive preprocessing and approximations. This opens new options for interactive medical visualization.
Intelligent Virtual Sonographer (IVS): Enhancing Physician-Robot-Patient Communication
Jul 17, 2025The advancement and maturity of large language models (LLMs) and robotics have unlocked vast potential for human-computer interaction, particularly in the field of robotic ultrasound. While existing research primarily focuses on either patient-robot or physician-robot interaction, the role of an intelligent virtual sonographer (IVS) bridging physician-robot-patient communication remains underexplored. This work introduces a conversational virtual agent in Extended Reality (XR) that facilitates real-time interaction between physicians, a robotic ultrasound system(RUS), and patients. The IVS agent communicates with physicians in a professional manner while offering empathetic explanations and reassurance to patients. Furthermore, it actively controls the RUS by executing physician commands and transparently relays these actions to the patient. By integrating LLM-powered dialogue with speech-to-text, text-to-speech, and robotic control, our system enhances the efficiency, clarity, and accessibility of robotic ultrasound acquisition. This work constitutes a first step toward understanding how IVS can bridge communication gaps in physician-robot-patient interaction, providing more control and therefore trust into physician-robot interaction while improving patient experience and acceptance of robotic ultrasound.
MM-OR: A Large Multimodal Operating Room Dataset for Semantic Understanding of High-Intensity Surgical Environments
Mar 04, 2025
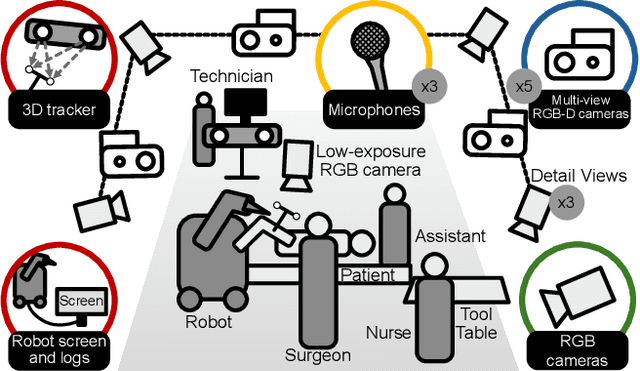
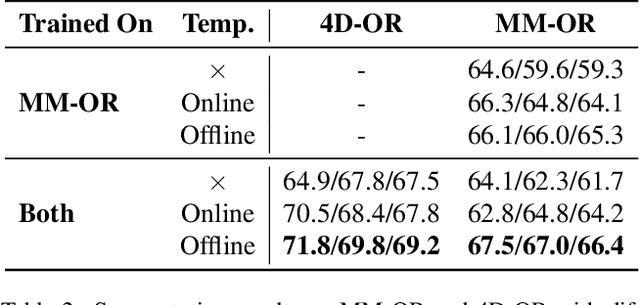
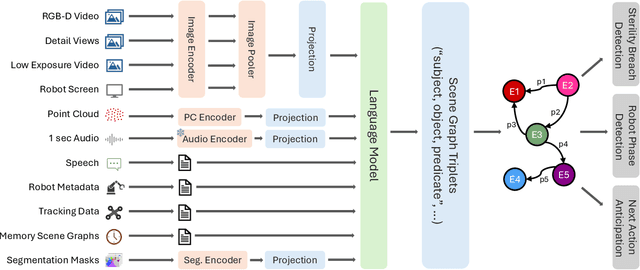
Operating rooms (ORs) are complex, high-stakes environments requiring precise understanding of interactions among medical staff, tools, and equipment for enhancing surgical assistance, situational awareness, and patient safety. Current datasets fall short in scale, realism and do not capture the multimodal nature of OR scenes, limiting progress in OR modeling. To this end, we introduce MM-OR, a realistic and large-scale multimodal spatiotemporal OR dataset, and the first dataset to enable multimodal scene graph generation. MM-OR captures comprehensive OR scenes containing RGB-D data, detail views, audio, speech transcripts, robotic logs, and tracking data and is annotated with panoptic segmentations, semantic scene graphs, and downstream task labels. Further, we propose MM2SG, the first multimodal large vision-language model for scene graph generation, and through extensive experiments, demonstrate its ability to effectively leverage multimodal inputs. Together, MM-OR and MM2SG establish a new benchmark for holistic OR understanding, and open the path towards multimodal scene analysis in complex, high-stakes environments. Our code, and data is available at https://github.com/egeozsoy/MM-OR.
A Framework for Multimodal Medical Image Interaction
Jul 09, 2024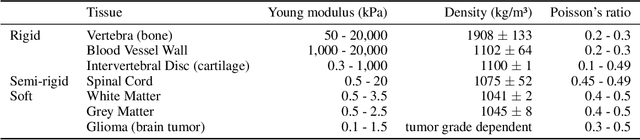
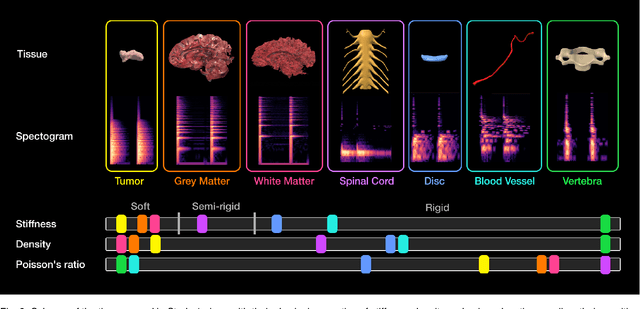
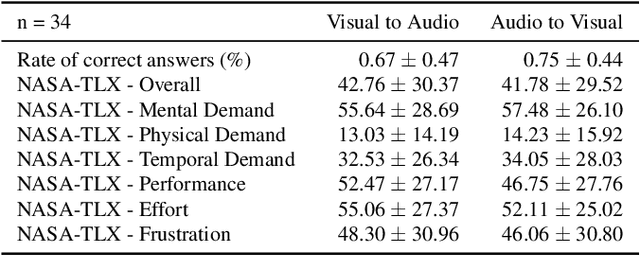
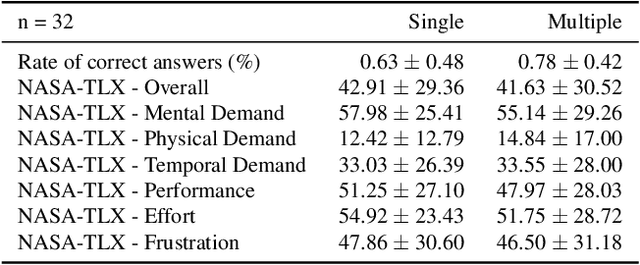
Medical doctors rely on images of the human anatomy, such as magnetic resonance imaging (MRI), to localize regions of interest in the patient during diagnosis and treatment. Despite advances in medical imaging technology, the information conveyance remains unimodal. This visual representation fails to capture the complexity of the real, multisensory interaction with human tissue. However, perceiving multimodal information about the patient's anatomy and disease in real-time is critical for the success of medical procedures and patient outcome. We introduce a Multimodal Medical Image Interaction (MMII) framework to allow medical experts a dynamic, audiovisual interaction with human tissue in three-dimensional space. In a virtual reality environment, the user receives physically informed audiovisual feedback to improve the spatial perception of anatomical structures. MMII uses a model-based sonification approach to generate sounds derived from the geometry and physical properties of tissue, thereby eliminating the need for hand-crafted sound design. Two user studies involving 34 general and nine clinical experts were conducted to evaluate the proposed interaction framework's learnability, usability, and accuracy. Our results showed excellent learnability of audiovisual correspondence as the rate of correct associations significantly improved (p < 0.001) over the course of the study. MMII resulted in superior brain tumor localization accuracy (p < 0.05) compared to conventional medical image interaction. Our findings substantiate the potential of this novel framework to enhance interaction with medical images, for example, during surgical procedures where immediate and precise feedback is needed.
4D-OR: Semantic Scene Graphs for OR Domain Modeling
Mar 22, 2022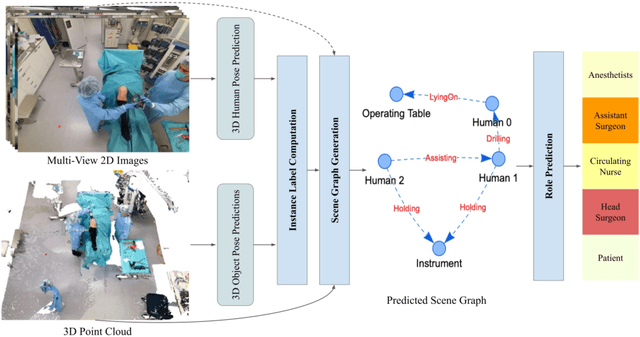


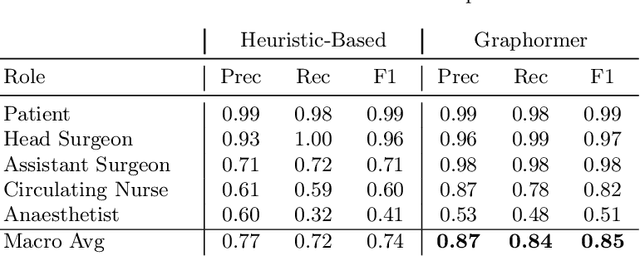
Surgical procedures are conducted in highly complex operating rooms (OR), comprising different actors, devices, and interactions. To date, only medically trained human experts are capable of understanding all the links and interactions in such a demanding environment. This paper aims to bring the community one step closer to automated, holistic and semantic understanding and modeling of OR domain. Towards this goal, for the first time, we propose using semantic scene graphs (SSG) to describe and summarize the surgical scene. The nodes of the scene graphs represent different actors and objects in the room, such as medical staff, patients, and medical equipment, whereas edges are the relationships between them. To validate the possibilities of the proposed representation, we create the first publicly available 4D surgical SSG dataset, 4D-OR, containing ten simulated total knee replacement surgeries recorded with six RGB-D sensors in a realistic OR simulation center. 4D-OR includes 6734 frames and is richly annotated with SSGs, human and object poses, and clinical roles. We propose an end-to-end neural network-based SSG generation pipeline, with a rate of success of 0.75 macro F1, indeed being able to infer semantic reasoning in the OR. We further demonstrate the representation power of our scene graphs by using it for the problem of clinical role prediction, where we achieve 0.85 macro F1. The code and dataset will be made available upon acceptance.
Know your sensORs -- A Modality Study For Surgical Action Classification
Mar 22, 2022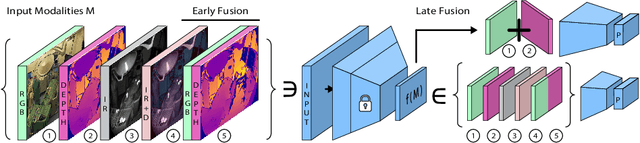
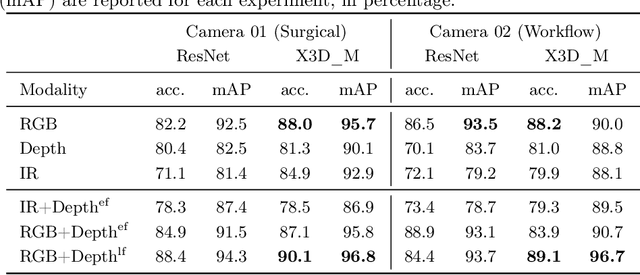
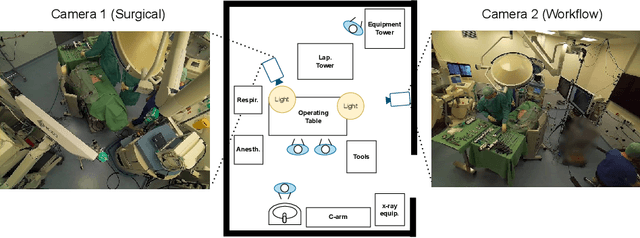
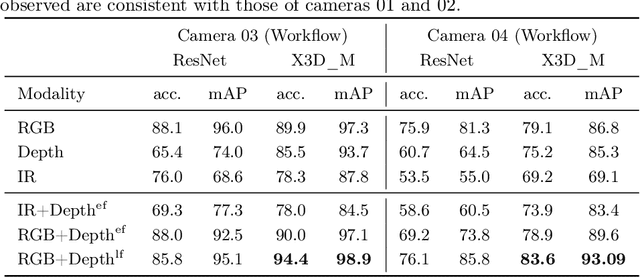
The surgical operating room (OR) presents many opportunities for automation and optimization. Videos from various sources in the OR are becoming increasingly available. The medical community seeks to leverage this wealth of data to develop automated methods to advance interventional care, lower costs, and improve overall patient outcomes. Existing datasets from OR room cameras are thus far limited in size or modalities acquired, leaving it unclear which sensor modalities are best suited for tasks such as recognizing surgical action from videos. This study demonstrates that surgical action recognition performance can vary depending on the image modalities used. We perform a methodical analysis on several commonly available sensor modalities, presenting two fusion approaches that improve classification performance. The analyses are carried out on a set of multi-view RGB-D video recordings of 18 laparoscopic procedures.
Motion-Aware Robotic 3D Ultrasound
Jul 13, 2021
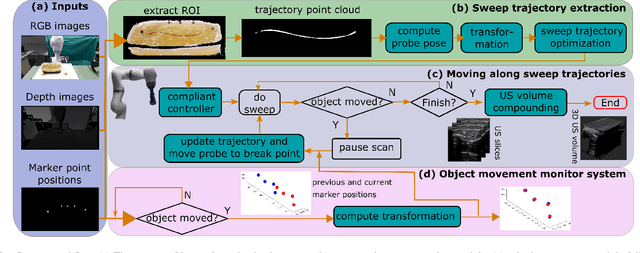
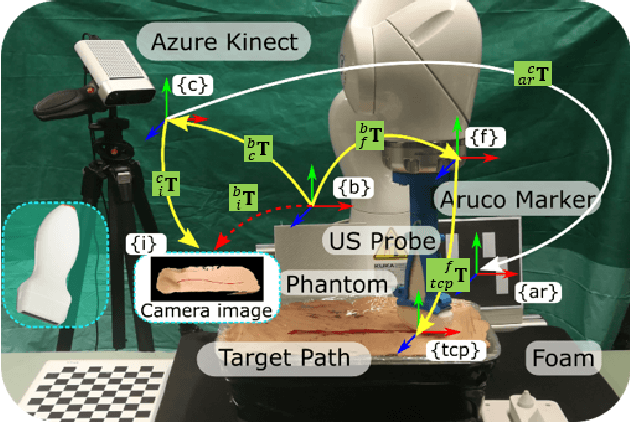
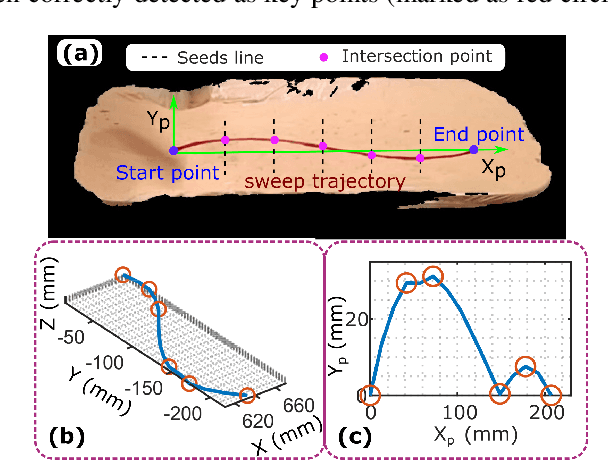
Robotic three-dimensional (3D) ultrasound (US) imaging has been employed to overcome the drawbacks of traditional US examinations, such as high inter-operator variability and lack of repeatability. However, object movement remains a challenge as unexpected motion decreases the quality of the 3D compounding. Furthermore, attempted adjustment of objects, e.g., adjusting limbs to display the entire limb artery tree, is not allowed for conventional robotic US systems. To address this challenge, we propose a vision-based robotic US system that can monitor the object's motion and automatically update the sweep trajectory to provide 3D compounded images of the target anatomy seamlessly. To achieve these functions, a depth camera is employed to extract the manually planned sweep trajectory after which the normal direction of the object is estimated using the extracted 3D trajectory. Subsequently, to monitor the movement and further compensate for this motion to accurately follow the trajectory, the position of firmly attached passive markers is tracked in real-time. Finally, a step-wise compounding was performed. The experiments on a gel phantom demonstrate that the system can resume a sweep when the object is not stationary during scanning.
Multimodal Semantic Scene Graphs for Holistic Modeling of Surgical Procedures
Jun 09, 2021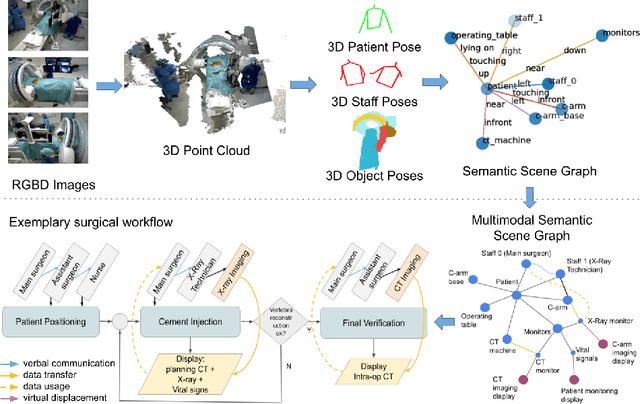
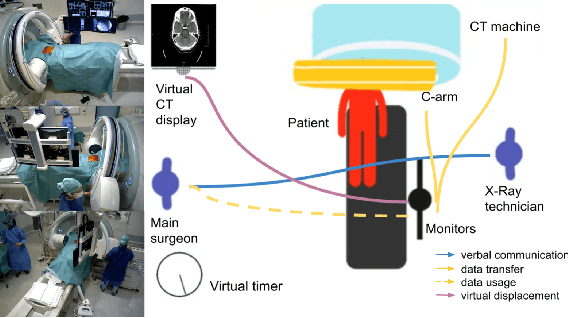
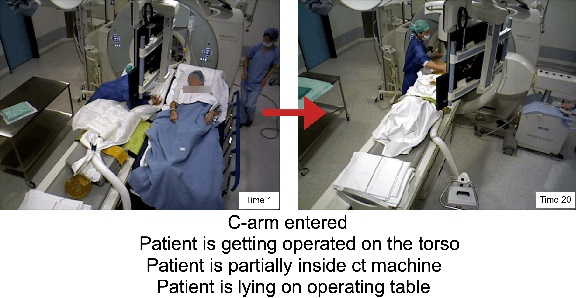
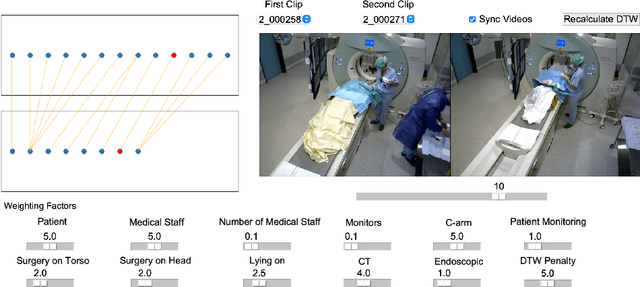
From a computer science viewpoint, a surgical domain model needs to be a conceptual one incorporating both behavior and data. It should therefore model actors, devices, tools, their complex interactions and data flow. To capture and model these, we take advantage of the latest computer vision methodologies for generating 3D scene graphs from camera views. We then introduce the Multimodal Semantic Scene Graph (MSSG) which aims at providing a unified symbolic, spatiotemporal and semantic representation of surgical procedures. This methodology aims at modeling the relationship between different components in surgical domain including medical staff, imaging systems, and surgical devices, opening the path towards holistic understanding and modeling of surgical procedures. We then use MSSG to introduce a dynamically generated graphical user interface tool for surgical procedure analysis which could be used for many applications including process optimization, OR design and automatic report generation. We finally demonstrate that the proposed MSSGs could also be used for synchronizing different complex surgical procedures. While the system still needs to be integrated into real operating rooms before getting validated, this conference paper aims mainly at providing the community with the basic principles of this novel concept through a first prototypal partial realization based on MVOR dataset.