 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCOMPOSE: Hypergraph Cover Optimization for Multi-view 3D Human Pose Estimation
Jan 14, 20263D pose estimation from sparse multi-views is a critical task for numerous applications, including action recognition, sports analysis, and human-robot interaction. Optimization-based methods typically follow a two-stage pipeline, first detecting 2D keypoints in each view and then associating these detections across views to triangulate the 3D pose. Existing methods rely on mere pairwise associations to model this correspondence problem, treating global consistency between views (i.e., cycle consistency) as a soft constraint. Yet, reconciling these constraints for multiple views becomes brittle when spurious associations propagate errors. We thus propose COMPOSE, a novel framework that formulates multi-view pose correspondence matching as a hypergraph partitioning problem rather than through pairwise association. While the complexity of the resulting integer linear program grows exponentially in theory, we introduce an efficient geometric pruning strategy to substantially reduce the search space. COMPOSE achieves improvements of up to 23% in average precision over previous optimization-based methods and up to 11% over self-supervised end-to-end learned methods, offering a promising solution to a widely studied problem.
Mitigating Biases in Surgical Operating Rooms with Geometry
Aug 11, 2025Deep neural networks are prone to learning spurious correlations, exploiting dataset-specific artifacts rather than meaningful features for prediction. In surgical operating rooms (OR), these manifest through the standardization of smocks and gowns that obscure robust identifying landmarks, introducing model bias for tasks related to modeling OR personnel. Through gradient-based saliency analysis on two public OR datasets, we reveal that CNN models succumb to such shortcuts, fixating on incidental visual cues such as footwear beneath surgical gowns, distinctive eyewear, or other role-specific identifiers. Avoiding such biases is essential for the next generation of intelligent assistance systems in the OR, which should accurately recognize personalized workflow traits, such as surgical skill level or coordination with other staff members. We address this problem by encoding personnel as 3D point cloud sequences, disentangling identity-relevant shape and motion patterns from appearance-based confounders. Our experiments demonstrate that while RGB and geometric methods achieve comparable performance on datasets with apparent simulation artifacts, RGB models suffer a 12% accuracy drop in realistic clinical settings with decreased visual diversity due to standardizations. This performance gap confirms that geometric representations capture more meaningful biometric features, providing an avenue to developing robust methods of modeling humans in the OR.
Forecasting Continuous Non-Conservative Dynamical Systems in SO(3)
Aug 11, 2025Modeling the rotation of moving objects is a fundamental task in computer vision, yet $SO(3)$ extrapolation still presents numerous challenges: (1) unknown quantities such as the moment of inertia complicate dynamics, (2) the presence of external forces and torques can lead to non-conservative kinematics, and (3) estimating evolving state trajectories under sparse, noisy observations requires robustness. We propose modeling trajectories of noisy pose estimates on the manifold of 3D rotations in a physically and geometrically meaningful way by leveraging Neural Controlled Differential Equations guided with $SO(3)$ Savitzky-Golay paths. Existing extrapolation methods often rely on energy conservation or constant velocity assumptions, limiting their applicability in real-world scenarios involving non-conservative forces. In contrast, our approach is agnostic to energy and momentum conservation while being robust to input noise, making it applicable to complex, non-inertial systems. Our approach is easily integrated as a module in existing pipelines and generalizes well to trajectories with unknown physical parameters. By learning to approximate object dynamics from noisy states during training, our model attains robust extrapolation capabilities in simulation and various real-world settings. Code is available at https://github.com/bastianlb/forecasting-rotational-dynamics
TrackOR: Towards Personalized Intelligent Operating Rooms Through Robust Tracking
Aug 11, 2025Providing intelligent support to surgical teams is a key frontier in automated surgical scene understanding, with the long-term goal of improving patient outcomes. Developing personalized intelligence for all staff members requires maintaining a consistent state of who is located where for long surgical procedures, which still poses numerous computational challenges. We propose TrackOR, a framework for tackling long-term multi-person tracking and re-identification in the operating room. TrackOR uses 3D geometric signatures to achieve state-of-the-art online tracking performance (+11% Association Accuracy over the strongest baseline), while also enabling an effective offline recovery process to create analysis-ready trajectories. Our work shows that by leveraging 3D geometric information, persistent identity tracking becomes attainable, enabling a critical shift towards the more granular, staff-centric analyses required for personalized intelligent systems in the operating room. This new capability opens up various applications, including our proposed temporal pathway imprints that translate raw tracking data into actionable insights for improving team efficiency and safety and ultimately providing personalized support.
Mutual Information Free Topological Generalization Bounds via Stability
Jul 09, 2025Providing generalization guarantees for stochastic optimization algorithms is a major challenge in modern learning theory. Recently, several studies highlighted the impact of the geometry of training trajectories on the generalization error, both theoretically and empirically. Among these works, a series of topological generalization bounds have been proposed, relating the generalization error to notions of topological complexity that stem from topological data analysis (TDA). Despite their empirical success, these bounds rely on intricate information-theoretic (IT) terms that can be bounded in specific cases but remain intractable for practical algorithms (such as ADAM), potentially reducing the relevance of the derived bounds. In this paper, we seek to formulate comprehensive and interpretable topological generalization bounds free of intractable mutual information terms. To this end, we introduce a novel learning theoretic framework that departs from the existing strategies via proof techniques rooted in algorithmic stability. By extending an existing notion of \textit{hypothesis set stability}, to \textit{trajectory stability}, we prove that the generalization error of trajectory-stable algorithms can be upper bounded in terms of (i) TDA quantities describing the complexity of the trajectory of the optimizer in the parameter space, and (ii) the trajectory stability parameter of the algorithm. Through a series of experimental evaluations, we demonstrate that the TDA terms in the bound are of great importance, especially as the number of training samples grows. This ultimately forms an explanation of the empirical success of the topological generalization bounds.
Continuous-Time SO(3) Forecasting with Savitzky--Golay Neural Controlled Differential Equations
Jun 07, 2025Tracking and forecasting the rotation of objects is fundamental in computer vision and robotics, yet SO(3) extrapolation remains challenging as (1) sensor observations can be noisy and sparse, (2) motion patterns can be governed by complex dynamics, and (3) application settings can demand long-term forecasting. This work proposes modeling continuous-time rotational object dynamics on $SO(3)$ using Neural Controlled Differential Equations guided by Savitzky-Golay paths. Unlike existing methods that rely on simplified motion assumptions, our method learns a general latent dynamical system of the underlying object trajectory while respecting the geometric structure of rotations. Experimental results on real-world data demonstrate compelling forecasting capabilities compared to existing approaches.
Copresheaf Topological Neural Networks: A Generalized Deep Learning Framework
May 28, 2025We introduce copresheaf topological neural networks (CTNNs), a powerful and unifying framework that encapsulates a wide spectrum of deep learning architectures, designed to operate on structured data: including images, point clouds, graphs, meshes, and topological manifolds. While deep learning has profoundly impacted domains ranging from digital assistants to autonomous systems, the principled design of neural architectures tailored to specific tasks and data types remains one of the field's most persistent open challenges. CTNNs address this gap by grounding model design in the language of copresheaves, a concept from algebraic topology that generalizes and subsumes most practical deep learning models in use today. This abstract yet constructive formulation yields a rich design space from which theoretically sound and practically effective solutions can be derived to tackle core challenges in representation learning: long-range dependencies, oversmoothing, heterophily, and non-Euclidean domains. Our empirical results on structured data benchmarks demonstrate that CTNNs consistently outperform conventional baselines, particularly in tasks requiring hierarchical or localized sensitivity. These results underscore CTNNs as a principled, multi-scale foundation for the next generation of deep learning architectures.
Beyond Role-Based Surgical Domain Modeling: Generalizable Re-Identification in the Operating Room
Mar 17, 2025


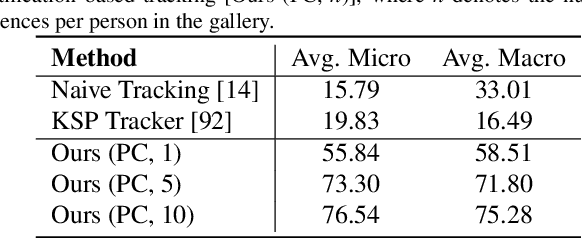
Surgical domain models improve workflow optimization through automated predictions of each staff member's surgical role. However, mounting evidence indicates that team familiarity and individuality impact surgical outcomes. We present a novel staff-centric modeling approach that characterizes individual team members through their distinctive movement patterns and physical characteristics, enabling long-term tracking and analysis of surgical personnel across multiple procedures. To address the challenge of inter-clinic variability, we develop a generalizable re-identification framework that encodes sequences of 3D point clouds to capture shape and articulated motion patterns unique to each individual. Our method achieves 86.19% accuracy on realistic clinical data while maintaining 75.27% accuracy when transferring between different environments - a 12% improvement over existing methods. When used to augment markerless personnel tracking, our approach improves accuracy by over 50%. Through extensive validation across three datasets and the introduction of a novel workflow visualization technique, we demonstrate how our framework can reveal novel insights into surgical team dynamics and space utilization patterns, advancing methods to analyze surgical workflows and team coordination.
Beyond Complete Shapes: A quantitative Evaluation of 3D Shape Matching Algorithms
Nov 05, 2024

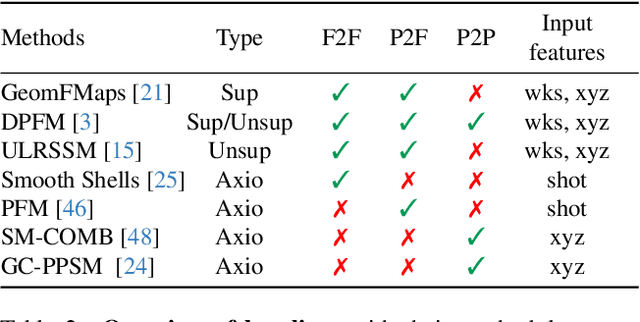
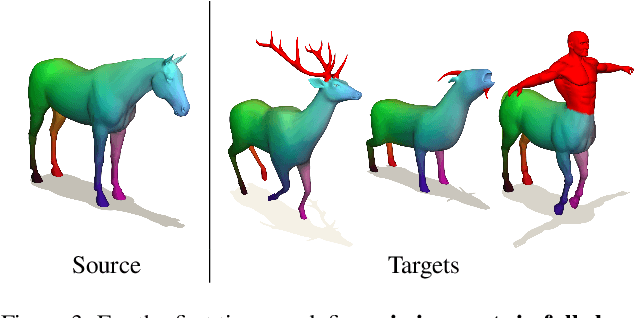
Finding correspondences between 3D shapes is an important and long-standing problem in computer vision, graphics and beyond. While approaches based on machine learning dominate modern 3D shape matching, almost all existing (learning-based) methods require that at least one of the involved shapes is complete. In contrast, the most challenging and arguably most practically relevant setting of matching partially observed shapes, is currently underexplored. One important factor is that existing datasets contain only a small number of shapes (typically below 100), which are unable to serve data-hungry machine learning approaches, particularly in the unsupervised regime. In addition, the type of partiality present in existing datasets is often artificial and far from realistic. To address these limitations and to encourage research on these relevant settings, we provide a generic and flexible framework for the procedural generation of challenging partial shape matching scenarios. Our framework allows for a virtually infinite generation of partial shape matching instances from a finite set of shapes with complete geometry. Further, we manually create cross-dataset correspondences between seven existing (complete geometry) shape matching datasets, leading to a total of 2543 shapes. Based on this, we propose several challenging partial benchmark settings, for which we evaluate respective state-of-the-art methods as baselines.
Hybrid Functional Maps for Crease-Aware Non-Isometric Shape Matching
Dec 06, 2023
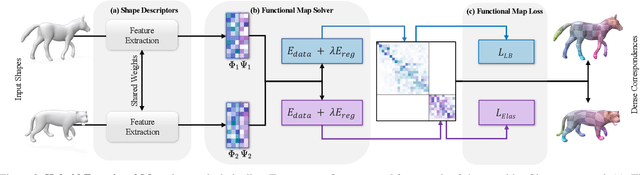
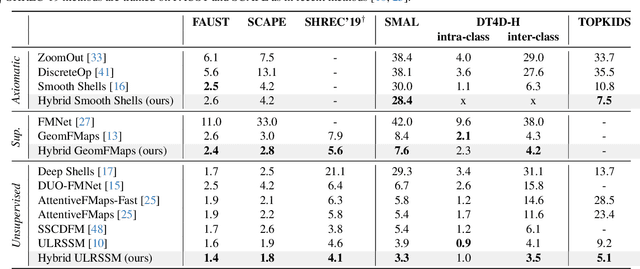
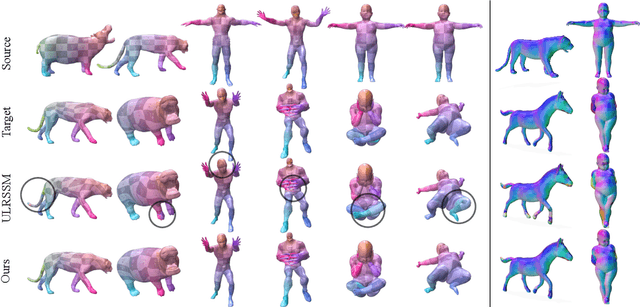
Non-isometric shape correspondence remains a fundamental challenge in computer vision. Traditional methods using Laplace-Beltrami operator (LBO) eigenmodes face limitations in characterizing high-frequency extrinsic shape changes like bending and creases. We propose a novel approach of combining the non-orthogonal extrinsic basis of eigenfunctions of the elastic thin-shell hessian with the intrinsic ones of the LBO, creating a hybrid spectral space in which we construct functional maps. To this end, we present a theoretical framework to effectively integrate non-orthogonal basis functions into descriptor- and learning-based functional map methods. Our approach can be incorporated easily into existing functional map pipelines across varying applications and is able to handle complex deformations beyond isometries. We show extensive evaluations across various supervised and unsupervised settings and demonstrate significant improvements. Notably, our approach achieves up to 15% better mean geodesic error for non-isometric correspondence settings and up to 45% improvement in scenarios with topological noise.