 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCOMPOSE: Hypergraph Cover Optimization for Multi-view 3D Human Pose Estimation
Jan 14, 20263D pose estimation from sparse multi-views is a critical task for numerous applications, including action recognition, sports analysis, and human-robot interaction. Optimization-based methods typically follow a two-stage pipeline, first detecting 2D keypoints in each view and then associating these detections across views to triangulate the 3D pose. Existing methods rely on mere pairwise associations to model this correspondence problem, treating global consistency between views (i.e., cycle consistency) as a soft constraint. Yet, reconciling these constraints for multiple views becomes brittle when spurious associations propagate errors. We thus propose COMPOSE, a novel framework that formulates multi-view pose correspondence matching as a hypergraph partitioning problem rather than through pairwise association. While the complexity of the resulting integer linear program grows exponentially in theory, we introduce an efficient geometric pruning strategy to substantially reduce the search space. COMPOSE achieves improvements of up to 23% in average precision over previous optimization-based methods and up to 11% over self-supervised end-to-end learned methods, offering a promising solution to a widely studied problem.
TrackOR: Towards Personalized Intelligent Operating Rooms Through Robust Tracking
Aug 11, 2025Providing intelligent support to surgical teams is a key frontier in automated surgical scene understanding, with the long-term goal of improving patient outcomes. Developing personalized intelligence for all staff members requires maintaining a consistent state of who is located where for long surgical procedures, which still poses numerous computational challenges. We propose TrackOR, a framework for tackling long-term multi-person tracking and re-identification in the operating room. TrackOR uses 3D geometric signatures to achieve state-of-the-art online tracking performance (+11% Association Accuracy over the strongest baseline), while also enabling an effective offline recovery process to create analysis-ready trajectories. Our work shows that by leveraging 3D geometric information, persistent identity tracking becomes attainable, enabling a critical shift towards the more granular, staff-centric analyses required for personalized intelligent systems in the operating room. This new capability opens up various applications, including our proposed temporal pathway imprints that translate raw tracking data into actionable insights for improving team efficiency and safety and ultimately providing personalized support.
Mitigating Biases in Surgical Operating Rooms with Geometry
Aug 11, 2025Deep neural networks are prone to learning spurious correlations, exploiting dataset-specific artifacts rather than meaningful features for prediction. In surgical operating rooms (OR), these manifest through the standardization of smocks and gowns that obscure robust identifying landmarks, introducing model bias for tasks related to modeling OR personnel. Through gradient-based saliency analysis on two public OR datasets, we reveal that CNN models succumb to such shortcuts, fixating on incidental visual cues such as footwear beneath surgical gowns, distinctive eyewear, or other role-specific identifiers. Avoiding such biases is essential for the next generation of intelligent assistance systems in the OR, which should accurately recognize personalized workflow traits, such as surgical skill level or coordination with other staff members. We address this problem by encoding personnel as 3D point cloud sequences, disentangling identity-relevant shape and motion patterns from appearance-based confounders. Our experiments demonstrate that while RGB and geometric methods achieve comparable performance on datasets with apparent simulation artifacts, RGB models suffer a 12% accuracy drop in realistic clinical settings with decreased visual diversity due to standardizations. This performance gap confirms that geometric representations capture more meaningful biometric features, providing an avenue to developing robust methods of modeling humans in the OR.
Beyond Role-Based Surgical Domain Modeling: Generalizable Re-Identification in the Operating Room
Mar 17, 2025


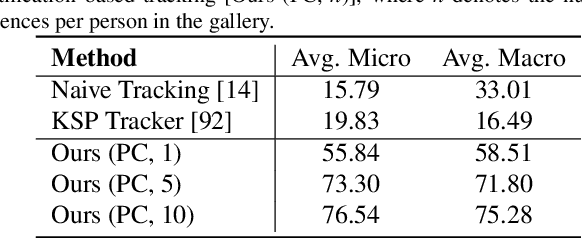
Surgical domain models improve workflow optimization through automated predictions of each staff member's surgical role. However, mounting evidence indicates that team familiarity and individuality impact surgical outcomes. We present a novel staff-centric modeling approach that characterizes individual team members through their distinctive movement patterns and physical characteristics, enabling long-term tracking and analysis of surgical personnel across multiple procedures. To address the challenge of inter-clinic variability, we develop a generalizable re-identification framework that encodes sequences of 3D point clouds to capture shape and articulated motion patterns unique to each individual. Our method achieves 86.19% accuracy on realistic clinical data while maintaining 75.27% accuracy when transferring between different environments - a 12% improvement over existing methods. When used to augment markerless personnel tracking, our approach improves accuracy by over 50%. Through extensive validation across three datasets and the introduction of a novel workflow visualization technique, we demonstrate how our framework can reveal novel insights into surgical team dynamics and space utilization patterns, advancing methods to analyze surgical workflows and team coordination.
DisguisOR: Holistic Face Anonymization for the Operating Room
Jul 26, 2023Purpose: Recent advances in Surgical Data Science (SDS) have contributed to an increase in video recordings from hospital environments. While methods such as surgical workflow recognition show potential in increasing the quality of patient care, the quantity of video data has surpassed the scale at which images can be manually anonymized. Existing automated 2D anonymization methods under-perform in Operating Rooms (OR), due to occlusions and obstructions. We propose to anonymize multi-view OR recordings using 3D data from multiple camera streams. Methods: RGB and depth images from multiple cameras are fused into a 3D point cloud representation of the scene. We then detect each individual's face in 3D by regressing a parametric human mesh model onto detected 3D human keypoints and aligning the face mesh with the fused 3D point cloud. The mesh model is rendered into every acquired camera view, replacing each individual's face. Results: Our method shows promise in locating faces at a higher rate than existing approaches. DisguisOR produces geometrically consistent anonymizations for each camera view, enabling more realistic anonymization that is less detrimental to downstream tasks. Conclusion: Frequent obstructions and crowding in operating rooms leaves significant room for improvement for off-the-shelf anonymization methods. DisguisOR addresses privacy on a scene level and has the potential to facilitate further research in SDS.