 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePanORama: Multiview Consistent Panoptic Segmentation in Operating Rooms
Mar 20, 2026Operating rooms (ORs) are cluttered, dynamic, highly occluded environments, where reliable spatial understanding is essential for situational awareness during complex surgical workflows. Achieving spatial understanding for panoptic segmentation from sparse multiview images poses a fundamental challenge, as limited visibility in a subset of views often leads to mispredictions across cameras. To this end, we introduce PanORama, the first panoptic segmentation for the operating room that is multiview-consistent by design. By modeling cross-view interactions at the feature level inside the backbone in a single forward pass, view consistency emerges directly rather than through post-hoc refinement. We evaluate on the MM-OR and 4D-OR datasets, achieving >70% Panoptic Quality (PQ) performance, and outperforming the previous state of the art. Importantly, PanORama is calibration-free, requiring no camera parameters, and generalizes to unseen camera viewpoints within any multiview configuration at inference time. By substantially enhancing multiview segmentation and, consequently, spatial understanding in the OR, we believe our approach opens new opportunities for surgical perception and assistance. Code will be released upon acceptance.
Prototype-Based Knowledge Guidance for Fine-Grained Structured Radiology Reporting
Mar 12, 2026Structured radiology reporting promises faster, more consistent communication than free text, but automation remains difficult as models must make many fine-grained, discrete decisions about rare findings and attributes from limited structured supervision. In contrast, free-text reports are produced at scale in routine care and implicitly encode fine-grained, image-linked information through detailed descriptions. To leverage this unstructured knowledge, we propose ProtoSR, an approach for injecting free-text information into structured report population. First, we introduce an automatic extraction pipeline that uses an instruction-tuned LLM to mine 80k+ MIMIC-CXR studies and build a multimodal knowledge base aligned with a structured reporting template, representing each answer option with a visual prototype. Using this knowledge base, ProtoSR is trained to retrieve prototypes relevant for the current image-question pair and augment the model predictions through a prototype-conditioned residual, providing a data-driven second opinion that selectively corrects predictions. On the Rad-ReStruct benchmark, ProtoSR achieves state-of-the-art results, with the largest improvements on detailed attribute questions, demonstrating the value of integrating free-text derived signal for fine-grained image understanding.
PhenoKG: Knowledge Graph-Driven Gene Discovery and Patient Insights from Phenotypes Alone
Jun 16, 2025Identifying causative genes from patient phenotypes remains a significant challenge in precision medicine, with important implications for the diagnosis and treatment of genetic disorders. We propose a novel graph-based approach for predicting causative genes from patient phenotypes, with or without an available list of candidate genes, by integrating a rare disease knowledge graph (KG). Our model, combining graph neural networks and transformers, achieves substantial improvements over the current state-of-the-art. On the real-world MyGene2 dataset, it attains a mean reciprocal rank (MRR) of 24.64\% and nDCG@100 of 33.64\%, surpassing the best baseline (SHEPHERD) at 19.02\% MRR and 30.54\% nDCG@100. We perform extensive ablation studies to validate the contribution of each model component. Notably, the approach generalizes to cases where only phenotypic data are available, addressing key challenges in clinical decision support when genomic information is incomplete.
Language Agents for Hypothesis-driven Clinical Decision Making with Reinforcement Learning
Jun 16, 2025Clinical decision-making is a dynamic, interactive, and cyclic process where doctors have to repeatedly decide on which clinical action to perform and consider newly uncovered information for diagnosis and treatment. Large Language Models (LLMs) have the potential to support clinicians in this process, however, most applications of LLMs in clinical decision support suffer from one of two limitations: Either they assume the unrealistic scenario of immediate availability of all patient information and do not model the interactive and iterative investigation process, or they restrict themselves to the limited "out-of-the-box" capabilities of large pre-trained models without performing task-specific training. In contrast to this, we propose to model clinical decision-making for diagnosis with a hypothesis-driven uncertainty-aware language agent, LA-CDM, that converges towards a diagnosis via repeatedly requesting and interpreting relevant tests. Using a hybrid training paradigm combining supervised and reinforcement learning, we train LA-CDM with three objectives targeting critical aspects of clinical decision-making: accurate hypothesis generation, hypothesis uncertainty estimation, and efficient decision-making. We evaluate our methodology on MIMIC-CDM, a real-world dataset covering four abdominal diseases containing various clinical tests and show the benefit of explicitly training clinical decision-making for increasing diagnostic performance and efficiency.
From EHRs to Patient Pathways: Scalable Modeling of Longitudinal Health Trajectories with LLMs
Jun 05, 2025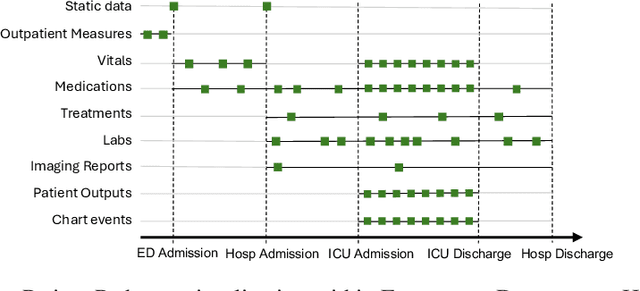
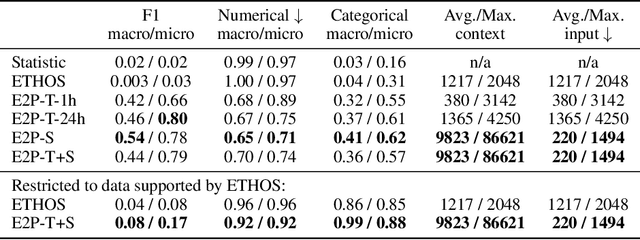
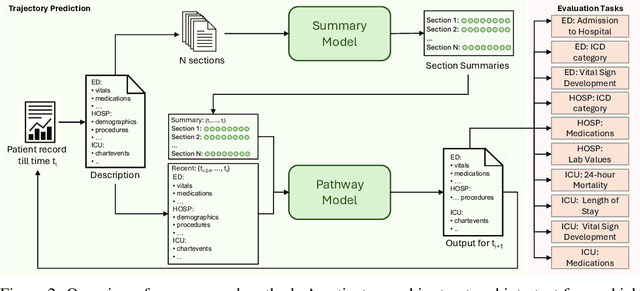
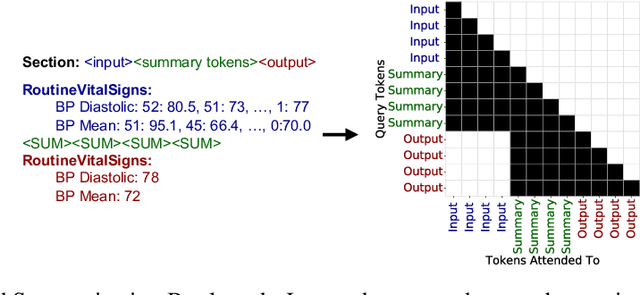
Healthcare systems face significant challenges in managing and interpreting vast, heterogeneous patient data for personalized care. Existing approaches often focus on narrow use cases with a limited feature space, overlooking the complex, longitudinal interactions needed for a holistic understanding of patient health. In this work, we propose a novel approach to patient pathway modeling by transforming diverse electronic health record (EHR) data into a structured representation and designing a holistic pathway prediction model, EHR2Path, optimized to predict future health trajectories. Further, we introduce a novel summary mechanism that embeds long-term temporal context into topic-specific summary tokens, improving performance over text-only models, while being much more token-efficient. EHR2Path demonstrates strong performance in both next time-step prediction and longitudinal simulation, outperforming competitive baselines. It enables detailed simulations of patient trajectories, inherently targeting diverse evaluation tasks, such as forecasting vital signs, lab test results, or length-of-stay, opening a path towards predictive and personalized healthcare.
EgoExOR: An Ego-Exo-Centric Operating Room Dataset for Surgical Activity Understanding
May 30, 2025Operating rooms (ORs) demand precise coordination among surgeons, nurses, and equipment in a fast-paced, occlusion-heavy environment, necessitating advanced perception models to enhance safety and efficiency. Existing datasets either provide partial egocentric views or sparse exocentric multi-view context, but do not explore the comprehensive combination of both. We introduce EgoExOR, the first OR dataset and accompanying benchmark to fuse first-person and third-person perspectives. Spanning 94 minutes (84,553 frames at 15 FPS) of two emulated spine procedures, Ultrasound-Guided Needle Insertion and Minimally Invasive Spine Surgery, EgoExOR integrates egocentric data (RGB, gaze, hand tracking, audio) from wearable glasses, exocentric RGB and depth from RGB-D cameras, and ultrasound imagery. Its detailed scene graph annotations, covering 36 entities and 22 relations (568,235 triplets), enable robust modeling of clinical interactions, supporting tasks like action recognition and human-centric perception. We evaluate the surgical scene graph generation performance of two adapted state-of-the-art models and offer a new baseline that explicitly leverages EgoExOR's multimodal and multi-perspective signals. This new dataset and benchmark set a new foundation for OR perception, offering a rich, multimodal resource for next-generation clinical perception.
ORQA: A Benchmark and Foundation Model for Holistic Operating Room Modeling
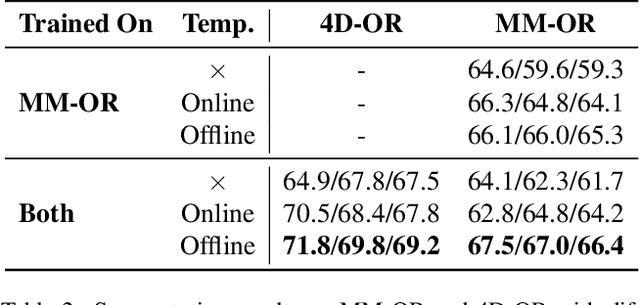
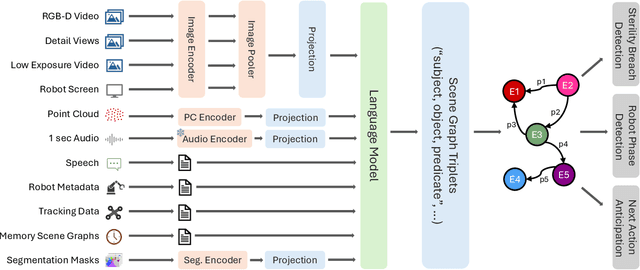
May 19, 2025The real-world complexity of surgeries necessitates surgeons to have deep and holistic comprehension to ensure precision, safety, and effective interventions. Computational systems are required to have a similar level of comprehension within the operating room. Prior works, limited to single-task efforts like phase recognition or scene graph generation, lack scope and generalizability. In this work, we introduce ORQA, a novel OR question answering benchmark and foundational multimodal model to advance OR intelligence. By unifying all four public OR datasets into a comprehensive benchmark, we enable our approach to concurrently address a diverse range of OR challenges. The proposed multimodal large language model fuses diverse OR signals such as visual, auditory, and structured data, for a holistic modeling of the OR. Finally, we propose a novel, progressive knowledge distillation paradigm, to generate a family of models optimized for different speed and memory requirements. We show the strong performance of ORQA on our proposed benchmark, and its zero-shot generalization, paving the way for scalable, unified OR modeling and significantly advancing multimodal surgical intelligence. We will release our code and data upon acceptance.
Rewarding Doubt: A Reinforcement Learning Approach to Confidence Calibration of Large Language Models
Mar 05, 2025



A safe and trustworthy use of Large Language Models (LLMs) requires an accurate expression of confidence in their answers. We introduce a novel Reinforcement Learning (RL) approach for LLM calibration that fine-tunes LLMs to elicit calibrated confidence estimations in their answers to factual questions. We model the problem as a betting game where the model predicts a confidence score together with every answer, and design a reward function that penalizes both over and under-confidence. We prove that under our reward design an optimal policy would result in a perfectly calibrated confidence estimation. Our experiments demonstrate significantly improved confidence calibration and generalization to new tasks without re-training, indicating that our approach teaches a general confidence awareness. This approach enables the training of inherently calibrated LLMs.
MM-OR: A Large Multimodal Operating Room Dataset for Semantic Understanding of High-Intensity Surgical Environments
Mar 04, 2025
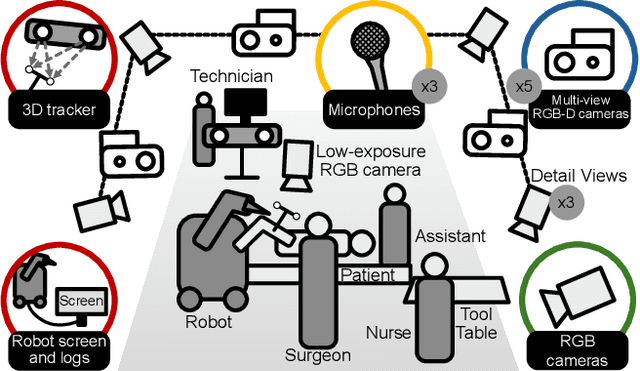
Operating rooms (ORs) are complex, high-stakes environments requiring precise understanding of interactions among medical staff, tools, and equipment for enhancing surgical assistance, situational awareness, and patient safety. Current datasets fall short in scale, realism and do not capture the multimodal nature of OR scenes, limiting progress in OR modeling. To this end, we introduce MM-OR, a realistic and large-scale multimodal spatiotemporal OR dataset, and the first dataset to enable multimodal scene graph generation. MM-OR captures comprehensive OR scenes containing RGB-D data, detail views, audio, speech transcripts, robotic logs, and tracking data and is annotated with panoptic segmentations, semantic scene graphs, and downstream task labels. Further, we propose MM2SG, the first multimodal large vision-language model for scene graph generation, and through extensive experiments, demonstrate its ability to effectively leverage multimodal inputs. Together, MM-OR and MM2SG establish a new benchmark for holistic OR understanding, and open the path towards multimodal scene analysis in complex, high-stakes environments. Our code, and data is available at https://github.com/egeozsoy/MM-OR.
ORacle: Large Vision-Language Models for Knowledge-Guided Holistic OR Domain Modeling
Apr 10, 2024



Every day, countless surgeries are performed worldwide, each within the distinct settings of operating rooms (ORs) that vary not only in their setups but also in the personnel, tools, and equipment used. This inherent diversity poses a substantial challenge for achieving a holistic understanding of the OR, as it requires models to generalize beyond their initial training datasets. To reduce this gap, we introduce ORacle, an advanced vision-language model designed for holistic OR domain modeling, which incorporates multi-view and temporal capabilities and can leverage external knowledge during inference, enabling it to adapt to previously unseen surgical scenarios. This capability is further enhanced by our novel data augmentation framework, which significantly diversifies the training dataset, ensuring ORacle's proficiency in applying the provided knowledge effectively. In rigorous testing, in scene graph generation, and downstream tasks on the 4D-OR dataset, ORacle not only demonstrates state-of-the-art performance but does so requiring less data than existing models. Furthermore, its adaptability is displayed through its ability to interpret unseen views, actions, and appearances of tools and equipment. This demonstrates ORacle's potential to significantly enhance the scalability and affordability of OR domain modeling and opens a pathway for future advancements in surgical data science. We will release our code and data upon acceptance.