 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOR-Action: Multi-Role Video Understanding with Fine-Grained Actions
Jun 11, 2026Fine-grained understanding of operating room (OR) activity could enable workflow-aware assistance, yet remains difficult due to clutter, occlusions, and limited sensing. The prevailing approach to model this environment is scene graphs as an interpretable representation of OR interactions. Converting their frame-wise relational predictions into temporally extended, fine-grained actions however, is challenging without explicit temporal modeling. To enable a principled temporal evaluation of current OR understanding methods, we introduce the first action-centric benchmark built on a publicly available ego-exocentric OR dataset by defining a fine-grained, multi-role action taxonomy and generating dense action segments via distillation from ground-truth scene graph state changes. Experiments on this benchmark show that current scene graph prediction methods struggle to model temporal structure, even when adding explicit modeling through Graph Neural Networks. We therefore introduce a vision-only temporal model that outperforms graph-based methods significantly when using all available egocentric video as input. Building on this model we also introduce a novel multi- to single-view feature alignment strategy that improves single-view performance on multi-role action recognition, mitigating the need for extensive egocentric video capture. Benchmark and code will be released upon acceptance.
Towards Comprehensive Real-Time Scene Understanding in Ophthalmic Surgery through Multimodal Image Fusion
Mar 26, 2026Purpose: The integration of multimodal imaging into operating rooms paves the way for comprehensive surgical scene understanding. In ophthalmic surgery, by now, two complementary imaging modalities are available: operating microscope (OPMI) imaging and real-time intraoperative optical coherence tomography (iOCT). This first work toward temporal OPMI and iOCT feature fusion demonstrates the potential of multimodal image processing for multi-head prediction through the example of precise instrument tracking in vitreoretinal surgery. Methods: We propose a multimodal, temporal, real-time capable network architecture to perform joint instrument detection, keypoint localization, and tool-tissue distance estimation. Our network design integrates a cross-attention fusion module to merge OPMI and iOCT image features, which are efficiently extracted via a YoloNAS and a CNN encoder, respectively. Furthermore, a region-based recurrent module leverages temporal coherence. Results: Our experiments demonstrate reliable instrument localization and keypoint detection (95.79% mAP50) and show that the incorporation of iOCT significantly improves tool-tissue distance estimation, while achieving real-time processing rates of 22.5 ms per frame. Especially for close distances to the retina (below 1 mm), the distance estimation accuracy improved from 284 $μm$ (OPMI only) to 33 $μm$ (multimodal). Conclusion: Feature fusion of multimodal imaging can enhance multi-task prediction accuracy compared to single-modality processing and real-time processing performance can be achieved through tailored network design. While our results demonstrate the potential of multi-modal processing for image-guided vitreoretinal surgery, they also underline key challenges that motivate future research toward more reliable, consistent, and comprehensive surgical scene understanding.
ProtoFlow: Interpretable and Robust Surgical Workflow Modeling with Learned Dynamic Scene Graph Prototypes
Dec 16, 2025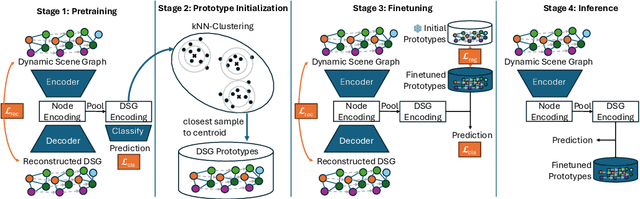
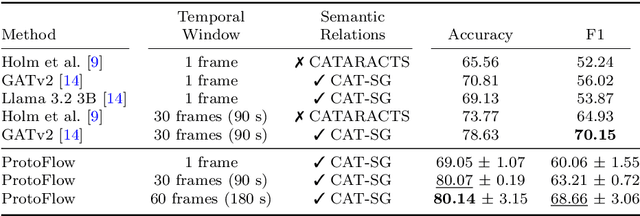
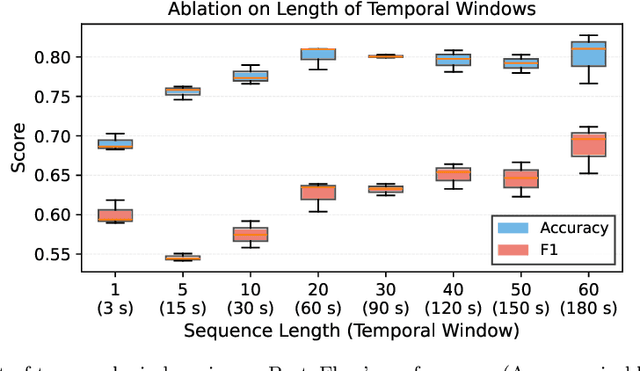
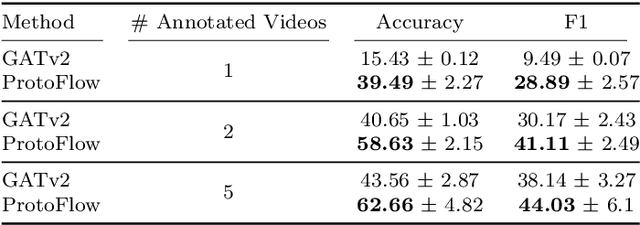
Purpose: Detailed surgical recognition is critical for advancing AI-assisted surgery, yet progress is hampered by high annotation costs, data scarcity, and a lack of interpretable models. While scene graphs offer a structured abstraction of surgical events, their full potential remains untapped. In this work, we introduce ProtoFlow, a novel framework that learns dynamic scene graph prototypes to model complex surgical workflows in an interpretable and robust manner. Methods: ProtoFlow leverages a graph neural network (GNN) encoder-decoder architecture that combines self-supervised pretraining for rich representation learning with a prototype-based fine-tuning stage. This process discovers and refines core prototypes that encapsulate recurring, clinically meaningful patterns of surgical interaction, forming an explainable foundation for workflow analysis. Results: We evaluate our approach on the fine-grained CAT-SG dataset. ProtoFlow not only outperforms standard GNN baselines in overall accuracy but also demonstrates exceptional robustness in limited-data, few-shot scenarios, maintaining strong performance when trained on as few as one surgical video. Our qualitative analyses further show that the learned prototypes successfully identify distinct surgical sub-techniques and provide clear, interpretable insights into workflow deviations and rare complications. Conclusion: By uniting robust representation learning with inherent explainability, ProtoFlow represents a significant step toward developing more transparent, reliable, and data-efficient AI systems, accelerating their potential for clinical adoption in surgical training, real-time decision support, and workflow optimization.
Watch and Learn: Leveraging Expert Knowledge and Language for Surgical Video Understanding
Mar 14, 2025Automated surgical workflow analysis is crucial for education, research, and clinical decision-making, but the lack of annotated datasets hinders the development of accurate and comprehensive workflow analysis solutions. We introduce a novel approach for addressing the sparsity and heterogeneity of annotated training data inspired by the human learning procedure of watching experts and understanding their explanations. Our method leverages a video-language model trained on alignment, denoising, and generative tasks to learn short-term spatio-temporal and multimodal representations. A task-specific temporal model is then used to capture relationships across entire videos. To achieve comprehensive video-language understanding in the surgical domain, we introduce a data collection and filtering strategy to construct a large-scale pretraining dataset from educational YouTube videos. We then utilize parameter-efficient fine-tuning by projecting downstream task annotations from publicly available surgical datasets into the language domain. Extensive experiments in two surgical domains demonstrate the effectiveness of our approach, with performance improvements of up to 7% in phase segmentation tasks, 8% in zero-shot phase segmentation, and comparable capabilities to fully-supervised models in few-shot settings. Harnessing our model's capabilities for long-range temporal localization and text generation, we present the first comprehensive solution for dense video captioning (DVC) of surgical videos, addressing this task despite the absence of existing DVC datasets in the surgical domain. We introduce a novel approach to surgical workflow understanding that leverages video-language pretraining, large-scale video pretraining, and optimized fine-tuning. Our method improves performance over state-of-the-art techniques and enables new downstream tasks for surgical video understanding.
SurGrID: Controllable Surgical Simulation via Scene Graph to Image Diffusion
Feb 11, 2025Surgical simulation offers a promising addition to conventional surgical training. However, available simulation tools lack photorealism and rely on hardcoded behaviour. Denoising Diffusion Models are a promising alternative for high-fidelity image synthesis, but existing state-of-the-art conditioning methods fall short in providing precise control or interactivity over the generated scenes. We introduce SurGrID, a Scene Graph to Image Diffusion Model, allowing for controllable surgical scene synthesis by leveraging Scene Graphs. These graphs encode a surgical scene's components' spatial and semantic information, which are then translated into an intermediate representation using our novel pre-training step that explicitly captures local and global information. Our proposed method improves the fidelity of generated images and their coherence with the graph input over the state-of-the-art. Further, we demonstrate the simulation's realism and controllability in a user assessment study involving clinical experts. Scene Graphs can be effectively used for precise and interactive conditioning of Denoising Diffusion Models for simulating surgical scenes, enabling high fidelity and interactive control over the generated content.
SURGIVID: Annotation-Efficient Surgical Video Object Discovery
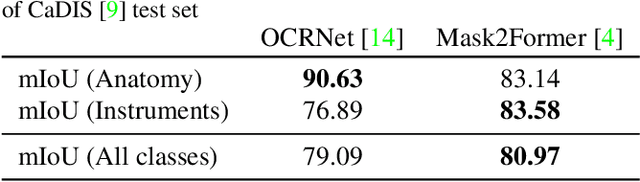
Sep 12, 2024Surgical scenes convey crucial information about the quality of surgery. Pixel-wise localization of tools and anatomical structures is the first task towards deeper surgical analysis for microscopic or endoscopic surgical views. This is typically done via fully-supervised methods which are annotation greedy and in several cases, demanding medical expertise. Considering the profusion of surgical videos obtained through standardized surgical workflows, we propose an annotation-efficient framework for the semantic segmentation of surgical scenes. We employ image-based self-supervised object discovery to identify the most salient tools and anatomical structures in surgical videos. These proposals are further refined within a minimally supervised fine-tuning step. Our unsupervised setup reinforced with only 36 annotation labels indicates comparable localization performance with fully-supervised segmentation models. Further, leveraging surgical phase labels as weak labels can better guide model attention towards surgical tools, leading to $\sim 2\%$ improvement in tool localization. Extensive ablation studies on the CaDIS dataset validate the effectiveness of our proposed solution in discovering relevant surgical objects with minimal or no supervision.
SANGRIA: Surgical Video Scene Graph Optimization for Surgical Workflow Prediction
Jul 29, 2024Graph-based holistic scene representations facilitate surgical workflow understanding and have recently demonstrated significant success. However, this task is often hindered by the limited availability of densely annotated surgical scene data. In this work, we introduce an end-to-end framework for the generation and optimization of surgical scene graphs on a downstream task. Our approach leverages the flexibility of graph-based spectral clustering and the generalization capability of foundation models to generate unsupervised scene graphs with learnable properties. We reinforce the initial spatial graph with sparse temporal connections using local matches between consecutive frames to predict temporally consistent clusters across a temporal neighborhood. By jointly optimizing the spatiotemporal relations and node features of the dynamic scene graph with the downstream task of phase segmentation, we address the costly and annotation-burdensome task of semantic scene comprehension and scene graph generation in surgical videos using only weak surgical phase labels. Further, by incorporating effective intermediate scene representation disentanglement steps within the pipeline, our solution outperforms the SOTA on the CATARACTS dataset by 8% accuracy and 10% F1 score in surgical workflow recognition
Dynamic Scene Graph Representation for Surgical Video
Sep 25, 2023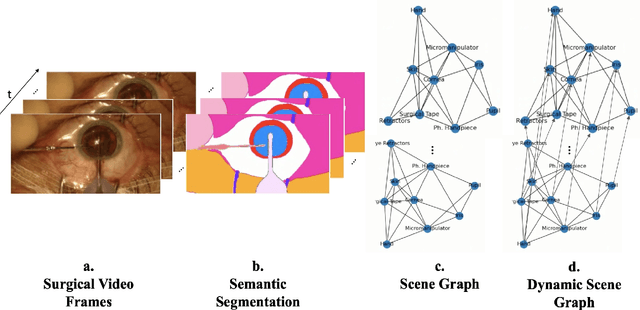
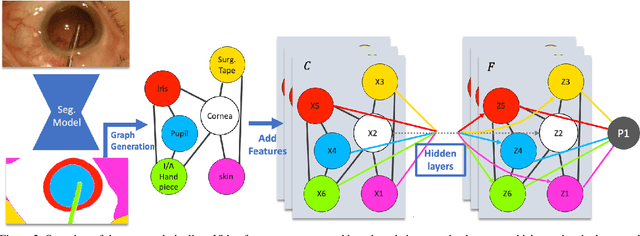
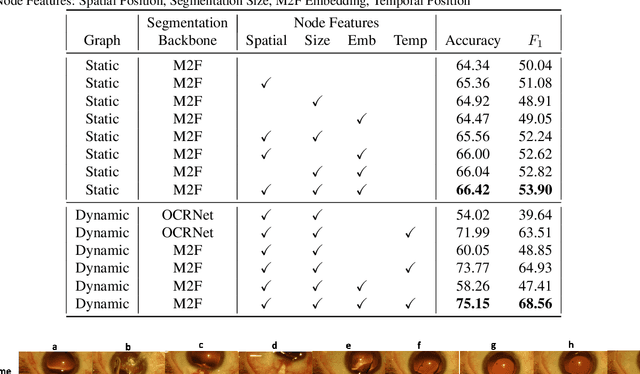
Surgical videos captured from microscopic or endoscopic imaging devices are rich but complex sources of information, depicting different tools and anatomical structures utilized during an extended amount of time. Despite containing crucial workflow information and being commonly recorded in many procedures, usage of surgical videos for automated surgical workflow understanding is still limited. In this work, we exploit scene graphs as a more holistic, semantically meaningful and human-readable way to represent surgical videos while encoding all anatomical structures, tools, and their interactions. To properly evaluate the impact of our solutions, we create a scene graph dataset from semantic segmentations from the CaDIS and CATARACTS datasets. We demonstrate that scene graphs can be leveraged through the use of graph convolutional networks (GCNs) to tackle surgical downstream tasks such as surgical workflow recognition with competitive performance. Moreover, we demonstrate the benefits of surgical scene graphs regarding the explainability and robustness of model decisions, which are crucial in the clinical setting.
Grasp Type Estimation for Myoelectric Prostheses using Point Cloud Feature Learning
Aug 07, 2019

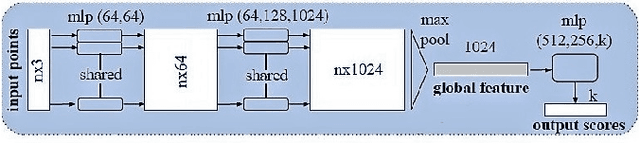
Prosthetic hands can help people with limb difference to return to their life routines. Commercial prostheses, however have several limitations in providing an acceptable dexterity. We approach these limitations by augmenting the prosthetic hands with an off-the-shelf depth sensor to enable the prosthesis to see the object's depth, record a single view (2.5-D) snapshot, and estimate an appropriate grasp type; using a deep network architecture based on 3D point clouds called PointNet. The human can act as the supervisor throughout the procedure by accepting or refusing the suggested grasp type. We achieved the grasp classification accuracy of up to 88%. Contrary to the case of the RGB data, the depth data provides all the necessary object shape information, which is required for grasp recognition. The PointNet not only enables using 3-D data in practice, but it also prevents excessive computations. Augmentation of the prosthetic hands with such a semi-autonomous system can lead to better differentiation of grasp types, less burden on user, and better performance.
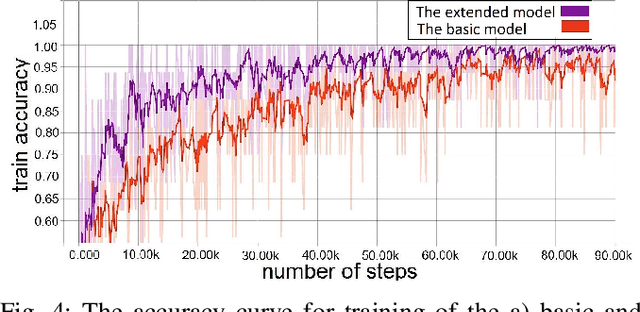
Dealing with Ambiguity in Robotic Grasping via Multiple Predictions
Nov 02, 2018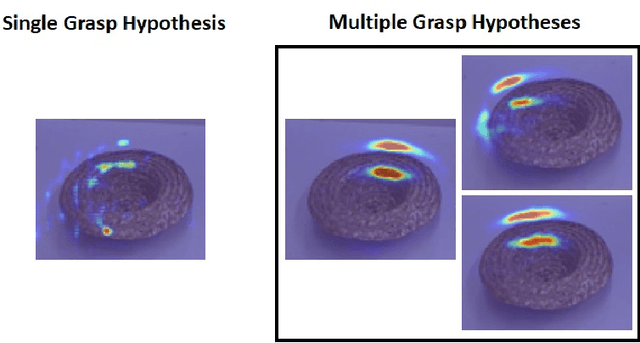
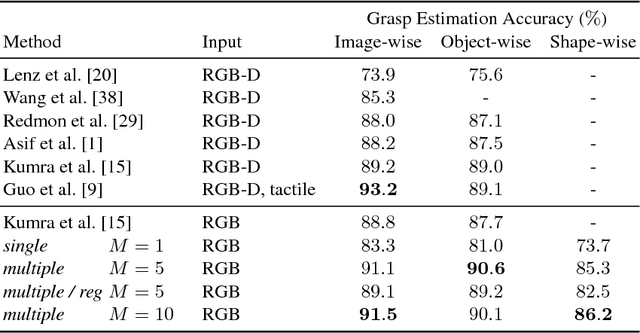
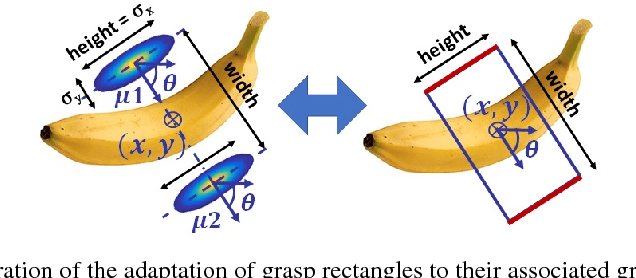
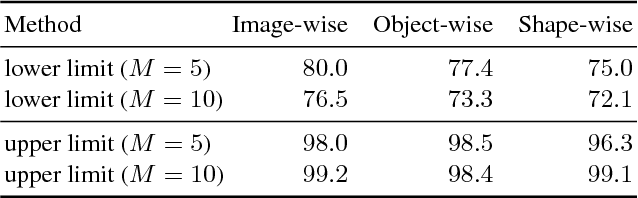
Humans excel in grasping and manipulating objects because of their life-long experience and knowledge about the 3D shape and weight distribution of objects. However, the lack of such intuition in robots makes robotic grasping an exceptionally challenging task. There are often several equally viable options of grasping an object. However, this ambiguity is not modeled in conventional systems that estimate a single, optimal grasp position. We propose to tackle this problem by simultaneously estimating multiple grasp poses from a single RGB image of the target object. Further, we reformulate the problem of robotic grasping by replacing conventional grasp rectangles with grasp belief maps, which hold more precise location information than a rectangle and account for the uncertainty inherent to the task. We augment a fully convolutional neural network with a multiple hypothesis prediction model that predicts a set of grasp hypotheses in under 60ms, which is critical for real-time robotic applications. The grasp detection accuracy reaches over 90% for unseen objects, outperforming the current state of the art on this task.