 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Scene Graph Representation for Surgical Video
Sep 25, 2023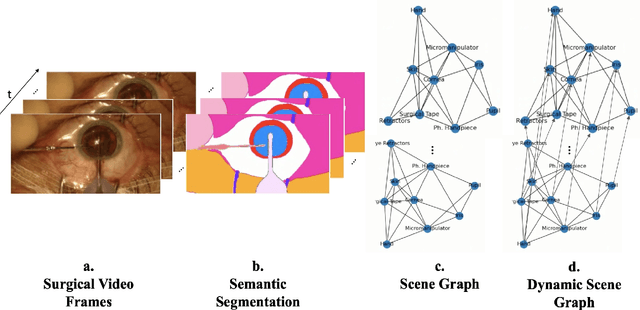
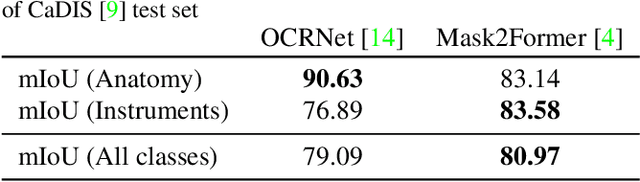
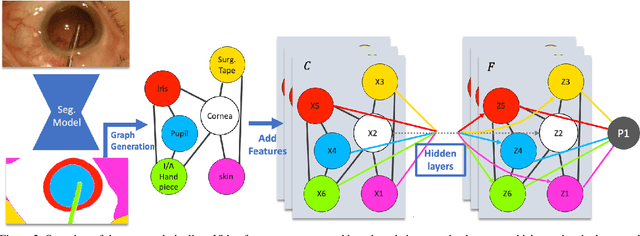
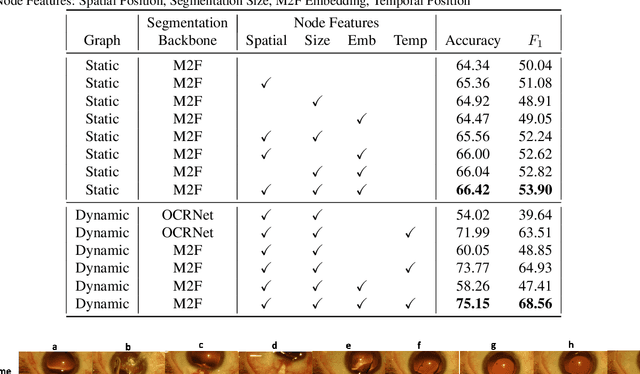
Surgical videos captured from microscopic or endoscopic imaging devices are rich but complex sources of information, depicting different tools and anatomical structures utilized during an extended amount of time. Despite containing crucial workflow information and being commonly recorded in many procedures, usage of surgical videos for automated surgical workflow understanding is still limited. In this work, we exploit scene graphs as a more holistic, semantically meaningful and human-readable way to represent surgical videos while encoding all anatomical structures, tools, and their interactions. To properly evaluate the impact of our solutions, we create a scene graph dataset from semantic segmentations from the CaDIS and CATARACTS datasets. We demonstrate that scene graphs can be leveraged through the use of graph convolutional networks (GCNs) to tackle surgical downstream tasks such as surgical workflow recognition with competitive performance. Moreover, we demonstrate the benefits of surgical scene graphs regarding the explainability and robustness of model decisions, which are crucial in the clinical setting.
Domain-specific loss design for unsupervised physical training: A new approach to modeling medical ML solutions
May 09, 2020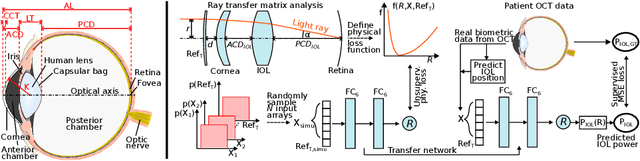
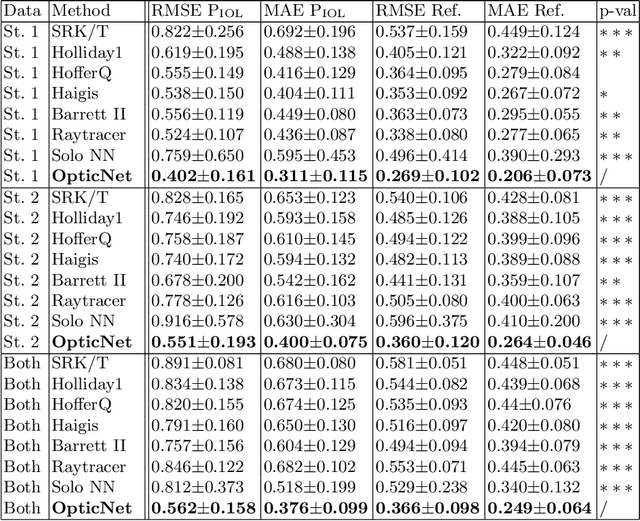
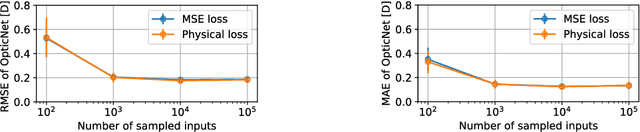
Today, cataract surgery is the most frequently performed ophthalmic surgery in the world. The cataract, a developing opacity of the human eye lens, constitutes the world's most frequent cause for blindness. During surgery, the lens is removed and replaced by an artificial intraocular lens (IOL). To prevent patients from needing strong visual aids after surgery, a precise prediction of the optical properties of the inserted IOL is crucial. There has been lots of activity towards developing methods to predict these properties from biometric eye data obtained by OCT devices, recently also by employing machine learning. They consider either only biometric data or physical models, but rarely both, and often neglect the IOL geometry. In this work, we propose OpticNet, a novel optical refraction network, loss function, and training scheme which is unsupervised, domain-specific, and physically motivated. We derive a precise light propagation eye model using single-ray raytracing and formulate a differentiable loss function that back-propagates physical gradients into the network. Further, we propose a new transfer learning procedure, which allows unsupervised training on the physical model and fine-tuning of the network on a cohort of real IOL patient cases. We show that our network is not only superior to systems trained with standard procedures but also that our method outperforms the current state of the art in IOL calculation when compared on two biometric data sets.