 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTreatment classification of posterior capsular opacification (PCO) using automated ground truths
Nov 11, 2022



Determination of treatment need of posterior capsular opacification (PCO)-- one of the most common complication of cataract surgery -- is a difficult process due to its local unavailability and the fact that treatment is provided only after PCO occurs in the central visual axis. In this paper we propose a deep learning (DL)-based method to first segment PCO images then classify the images into \textit{treatment required} and \textit{not yet required} cases in order to reduce frequent hospital visits. To train the model, we prepare a training image set with ground truths (GT) obtained from two strategies: (i) manual and (ii) automated. So, we have two models: (i) Model 1 (trained with image set containing manual GT) (ii) Model 2 (trained with image set containing automated GT). Both models when evaluated on validation image set gave Dice coefficient value greater than 0.8 and intersection-over-union (IoU) score greater than 0.67 in our experiments. Comparison between gold standard GT and segmented results from our models gave a Dice coefficient value greater than 0.7 and IoU score greater than 0.6 for both the models showing that automated ground truths can also result in generation of an efficient model. Comparison between our classification result and clinical classification shows 0.98 F2-score for outputs from both the models.
Domain-specific loss design for unsupervised physical training: A new approach to modeling medical ML solutions
May 09, 2020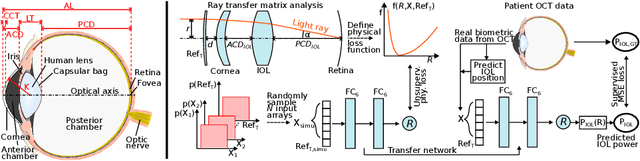
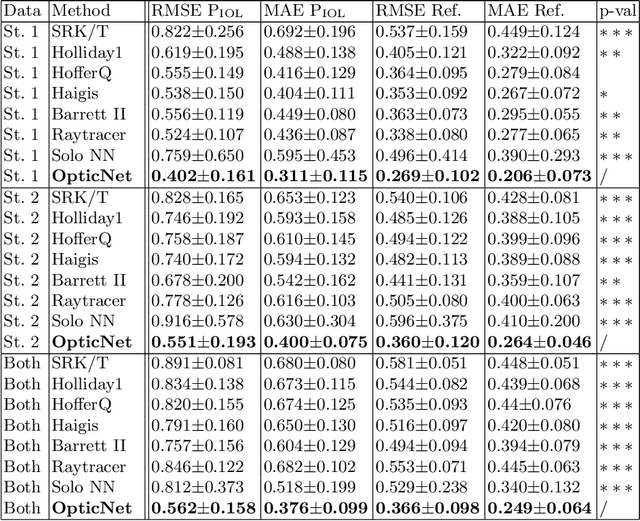
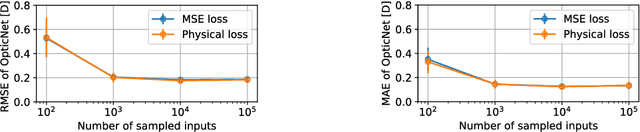
Today, cataract surgery is the most frequently performed ophthalmic surgery in the world. The cataract, a developing opacity of the human eye lens, constitutes the world's most frequent cause for blindness. During surgery, the lens is removed and replaced by an artificial intraocular lens (IOL). To prevent patients from needing strong visual aids after surgery, a precise prediction of the optical properties of the inserted IOL is crucial. There has been lots of activity towards developing methods to predict these properties from biometric eye data obtained by OCT devices, recently also by employing machine learning. They consider either only biometric data or physical models, but rarely both, and often neglect the IOL geometry. In this work, we propose OpticNet, a novel optical refraction network, loss function, and training scheme which is unsupervised, domain-specific, and physically motivated. We derive a precise light propagation eye model using single-ray raytracing and formulate a differentiable loss function that back-propagates physical gradients into the network. Further, we propose a new transfer learning procedure, which allows unsupervised training on the physical model and fine-tuning of the network on a cohort of real IOL patient cases. We show that our network is not only superior to systems trained with standard procedures but also that our method outperforms the current state of the art in IOL calculation when compared on two biometric data sets.