 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTreatment classification of posterior capsular opacification (PCO) using automated ground truths
Nov 11, 2022



Determination of treatment need of posterior capsular opacification (PCO)-- one of the most common complication of cataract surgery -- is a difficult process due to its local unavailability and the fact that treatment is provided only after PCO occurs in the central visual axis. In this paper we propose a deep learning (DL)-based method to first segment PCO images then classify the images into \textit{treatment required} and \textit{not yet required} cases in order to reduce frequent hospital visits. To train the model, we prepare a training image set with ground truths (GT) obtained from two strategies: (i) manual and (ii) automated. So, we have two models: (i) Model 1 (trained with image set containing manual GT) (ii) Model 2 (trained with image set containing automated GT). Both models when evaluated on validation image set gave Dice coefficient value greater than 0.8 and intersection-over-union (IoU) score greater than 0.67 in our experiments. Comparison between gold standard GT and segmented results from our models gave a Dice coefficient value greater than 0.7 and IoU score greater than 0.6 for both the models showing that automated ground truths can also result in generation of an efficient model. Comparison between our classification result and clinical classification shows 0.98 F2-score for outputs from both the models.
You-Do, I-Learn: Unsupervised Multi-User egocentric Approach Towards Video-Based Guidance
Mar 19, 2016
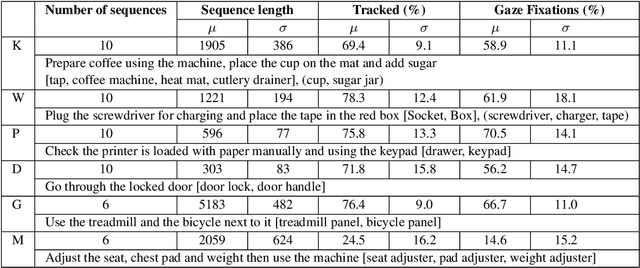
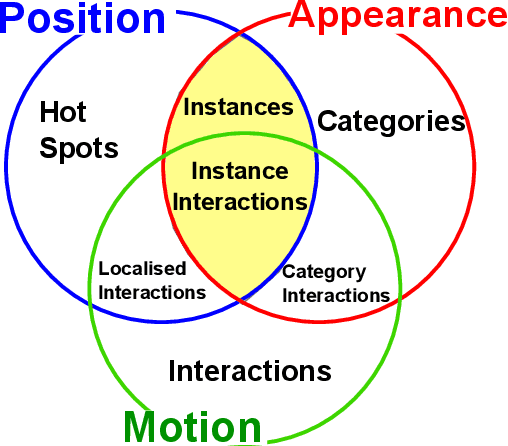

This paper presents an unsupervised approach towards automatically extracting video-based guidance on object usage, from egocentric video and wearable gaze tracking, collected from multiple users while performing tasks. The approach i) discovers task relevant objects, ii) builds a model for each, iii) distinguishes different ways in which each discovered object has been used and iv) discovers the dependencies between object interactions. The work investigates using appearance, position, motion and attention, and presents results using each and a combination of relevant features. Moreover, an online scalable approach is presented and is compared to offline results. The paper proposes a method for selecting a suitable video guide to be displayed to a novice user indicating how to use an object, purely triggered by the user's gaze. The potential assistive mode can also recommend an object to be used next based on the learnt sequence of object interactions. The approach was tested on a variety of daily tasks such as initialising a printer, preparing a coffee and setting up a gym machine.