 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModelling and Analysis of Magnetic Fields from Skeletal Muscle for Valuable Physiological Measurements
Apr 05, 2021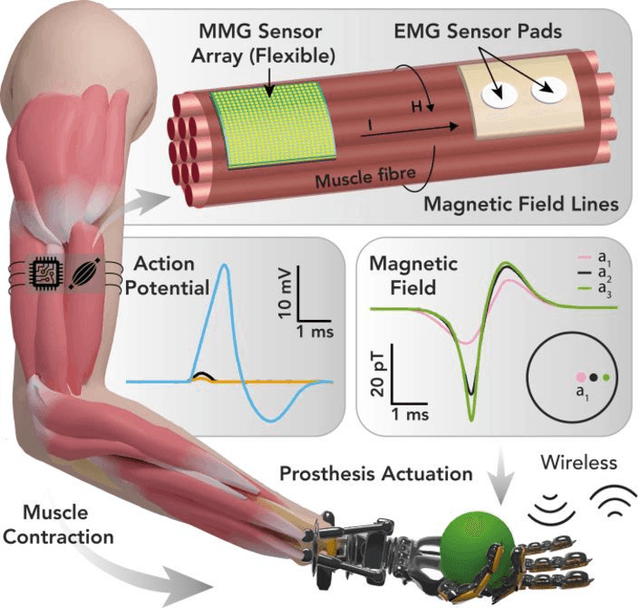

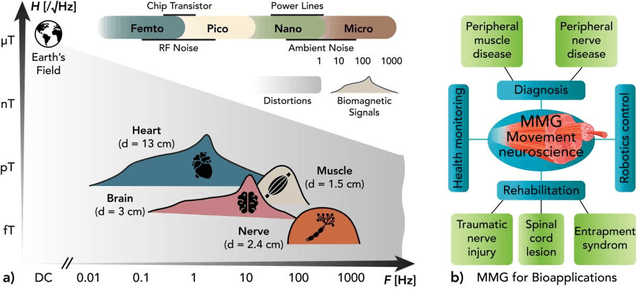

MagnetoMyoGraphy (MMG) is a method of studying muscle function via weak magnetic fields generated from human active organs and tissues. The correspondence between MMG and electromyography means directly derived from the Maxwell-Amp\`ere law. Here, upon briefly describing the principles of voltage distribution inside skeletal muscles due to the electrical stimulation, we provide a protocol to determine the effects of the magnetic field generated from a time-changing action potential propagating in a group of skeletal muscle cells. The position-dependent and the magnetic field behaviour on account of the different currents in muscle fibres are performed in temporal, spectral and spatial domains. The procedure covers identification of the fibre subpopulations inside the fascicles of a given nerve section, characterization of soleus skeletal muscle currents, check of axial intracellular currents, calculation of the generated magnetic field ultimately. We expect this protocol to take approximately 2-3 hours to complete for the whole finite-element analysis.
Classification of the Chinese Handwritten Numbers with Supervised Projective Dictionary Pair Learning
Mar 26, 2020


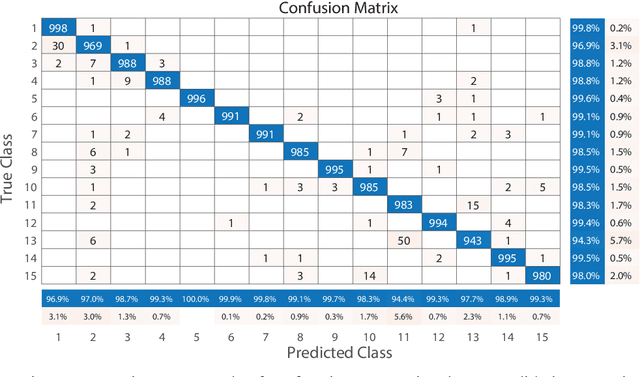
Image classification has become a key ingredient in the field of computer vision. To enhance classification accuracy, current approaches heavily focus on increasing network depth and width, e.g., inception modules, at the cost of computational requirements. To mitigate this problem, in this paper a novel dictionary learning method is proposed and tested with Chinese handwritten numbers. We have considered three important characteristics to design the dictionary: discriminability, sparsity, and classification error. We formulated these metrics into a unified cost function. The proposed architecture i) obtains an efficient sparse code in a novel feature space without relying on $\ell_0$ and $\ell_1$ norms minimisation; and ii) includes the classification error within the cost function as an extra constraint. Experimental results show that the proposed method provides superior classification performance compared to recent dictionary learning methods. With a classification accuracy of $\sim$98\%, the results suggest that our proposed sparse learning algorithm achieves comparable performance to existing well-known deep learning methods, e.g., SqueezeNet, GoogLeNet and MobileNetV2, but with a fraction of parameters.
Grasp Type Estimation for Myoelectric Prostheses using Point Cloud Feature Learning
Aug 07, 2019

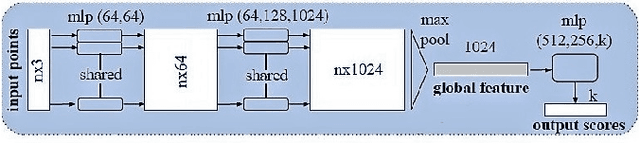
Prosthetic hands can help people with limb difference to return to their life routines. Commercial prostheses, however have several limitations in providing an acceptable dexterity. We approach these limitations by augmenting the prosthetic hands with an off-the-shelf depth sensor to enable the prosthesis to see the object's depth, record a single view (2.5-D) snapshot, and estimate an appropriate grasp type; using a deep network architecture based on 3D point clouds called PointNet. The human can act as the supervisor throughout the procedure by accepting or refusing the suggested grasp type. We achieved the grasp classification accuracy of up to 88%. Contrary to the case of the RGB data, the depth data provides all the necessary object shape information, which is required for grasp recognition. The PointNet not only enables using 3-D data in practice, but it also prevents excessive computations. Augmentation of the prosthetic hands with such a semi-autonomous system can lead to better differentiation of grasp types, less burden on user, and better performance.
Dealing with Ambiguity in Robotic Grasping via Multiple Predictions
Nov 02, 2018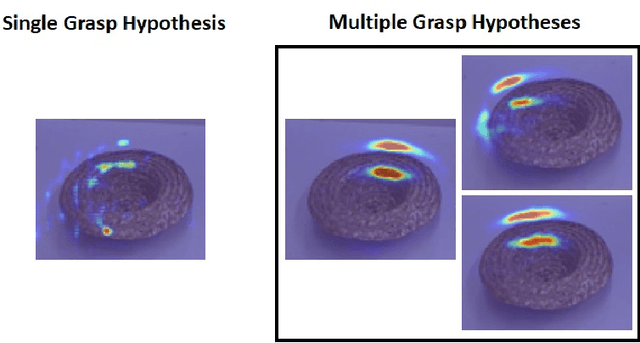
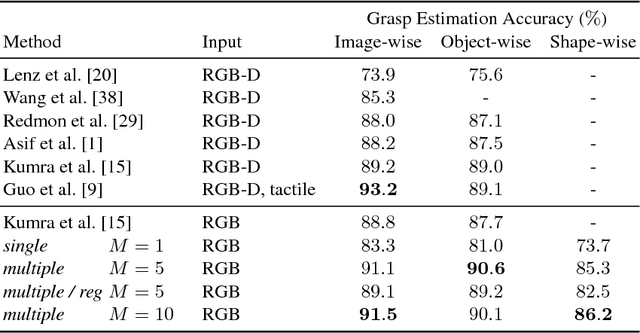
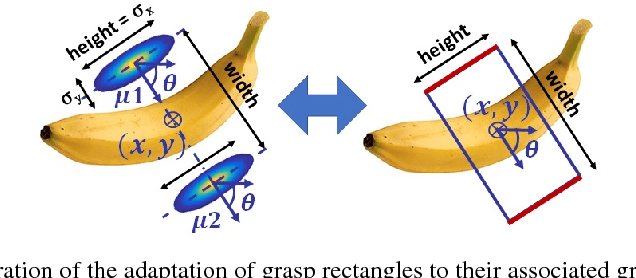
Humans excel in grasping and manipulating objects because of their life-long experience and knowledge about the 3D shape and weight distribution of objects. However, the lack of such intuition in robots makes robotic grasping an exceptionally challenging task. There are often several equally viable options of grasping an object. However, this ambiguity is not modeled in conventional systems that estimate a single, optimal grasp position. We propose to tackle this problem by simultaneously estimating multiple grasp poses from a single RGB image of the target object. Further, we reformulate the problem of robotic grasping by replacing conventional grasp rectangles with grasp belief maps, which hold more precise location information than a rectangle and account for the uncertainty inherent to the task. We augment a fully convolutional neural network with a multiple hypothesis prediction model that predicts a set of grasp hypotheses in under 60ms, which is critical for real-time robotic applications. The grasp detection accuracy reaches over 90% for unseen objects, outperforming the current state of the art on this task.