 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClassification of the Chinese Handwritten Numbers with Supervised Projective Dictionary Pair Learning
Paper and Code
Mar 26, 2020


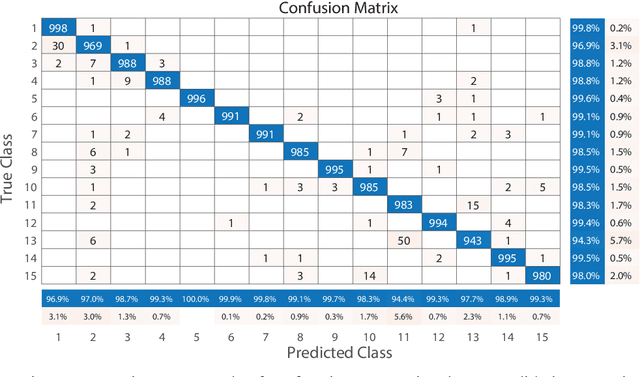
Image classification has become a key ingredient in the field of computer vision. To enhance classification accuracy, current approaches heavily focus on increasing network depth and width, e.g., inception modules, at the cost of computational requirements. To mitigate this problem, in this paper a novel dictionary learning method is proposed and tested with Chinese handwritten numbers. We have considered three important characteristics to design the dictionary: discriminability, sparsity, and classification error. We formulated these metrics into a unified cost function. The proposed architecture i) obtains an efficient sparse code in a novel feature space without relying on $\ell_0$ and $\ell_1$ norms minimisation; and ii) includes the classification error within the cost function as an extra constraint. Experimental results show that the proposed method provides superior classification performance compared to recent dictionary learning methods. With a classification accuracy of $\sim$98\%, the results suggest that our proposed sparse learning algorithm achieves comparable performance to existing well-known deep learning methods, e.g., SqueezeNet, GoogLeNet and MobileNetV2, but with a fraction of parameters.