 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCalibrated Confidence Expression for Radiology Report Generation
Mar 31, 2026Safe deployment of Large Vision-Language Models (LVLMs) in radiology report generation requires not only accurate predictions but also clinically interpretable indicators of when outputs should be thoroughly reviewed, enabling selective radiologist verification and reducing the risk of hallucinated findings influencing clinical decisions. One intuitive approach to this is verbalized confidence, where the model explicitly states its certainty. However, current state-of-the-art language models are often overconfident, and research on calibration in multimodal settings such as radiology report generation is limited. To address this gap, we introduce ConRad (Confidence Calibration for Radiology Reports), a reinforcement learning framework for fine-tuning medical LVLMs to produce calibrated verbalized confidence estimates alongside radiology reports. We study two settings: a single report-level confidence score and a sentence-level variant assigning a confidence to each claim. Both are trained using the GRPO algorithm with reward functions based on the logarithmic scoring rule, which incentivizes truthful self-assessment by penalizing miscalibration and guarantees optimal calibration under reward maximization. Experimentally, ConRad substantially improves calibration and outperforms competing methods. In a clinical evaluation we show that ConRad's report level scores are well aligned with clinicians' judgment. By highlighting full reports or low-confidence statements for targeted review, ConRad can support safer clinical integration of AI-assistance for report generation.
Learning Diagnostic Reasoning for Decision Support in Toxicology
Mar 31, 2026Acute poly-substance intoxication requires rapid, life-saving decisions under substantial uncertainty, as clinicians must rely on incomplete ingestion details and nonspecific symptoms. Effective diagnostic reasoning in this chaotic environment requires fusing unstructured, non-medical narratives (e.g. paramedic scene descriptions and unreliable patient self-reports or known histories), with structured medical data like vital signs. While Large Language Models (LLMs) show potential for processing such heterogeneous inputs, they struggle in this setting, often underperforming simple baselines that rely solely on patient histories. To address this, we present DeToxR (Decision-support for Toxicology with Reasoning), the first adaptation of Reinforcement Learning (RL) to emergency toxicology. We design a robust data-fusion engine for multi-label prediction across 14 substance classes based on an LLM finetuned with Group Relative Policy Optimization (GRPO). We optimize the model's reasoning directly using a clinical performance reward. By formulating a multi-label agreement metric as the reward signal, the model is explicitly penalized for missing co-ingested substances and hallucinating absent poisons. Our model significantly outperforms its unadapted base LLM counterpart and supervised baselines. Furthermore, in a clinical validation study, the model indicates a clinical advantage by outperforming an expert toxicologist in identifying the correct poisons (Micro-F1: 0.644 vs. 0.473). These results demonstrate the potential of RL-aligned LLMs to synthesize unstructured pre-clinical narratives and structured medical data for decision support in high-stakes environments.
Language Agents for Hypothesis-driven Clinical Decision Making with Reinforcement Learning
Jun 16, 2025Clinical decision-making is a dynamic, interactive, and cyclic process where doctors have to repeatedly decide on which clinical action to perform and consider newly uncovered information for diagnosis and treatment. Large Language Models (LLMs) have the potential to support clinicians in this process, however, most applications of LLMs in clinical decision support suffer from one of two limitations: Either they assume the unrealistic scenario of immediate availability of all patient information and do not model the interactive and iterative investigation process, or they restrict themselves to the limited "out-of-the-box" capabilities of large pre-trained models without performing task-specific training. In contrast to this, we propose to model clinical decision-making for diagnosis with a hypothesis-driven uncertainty-aware language agent, LA-CDM, that converges towards a diagnosis via repeatedly requesting and interpreting relevant tests. Using a hybrid training paradigm combining supervised and reinforcement learning, we train LA-CDM with three objectives targeting critical aspects of clinical decision-making: accurate hypothesis generation, hypothesis uncertainty estimation, and efficient decision-making. We evaluate our methodology on MIMIC-CDM, a real-world dataset covering four abdominal diseases containing various clinical tests and show the benefit of explicitly training clinical decision-making for increasing diagnostic performance and efficiency.
From EHRs to Patient Pathways: Scalable Modeling of Longitudinal Health Trajectories with LLMs
Jun 05, 2025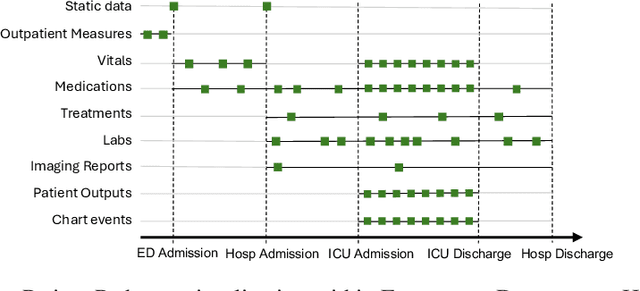
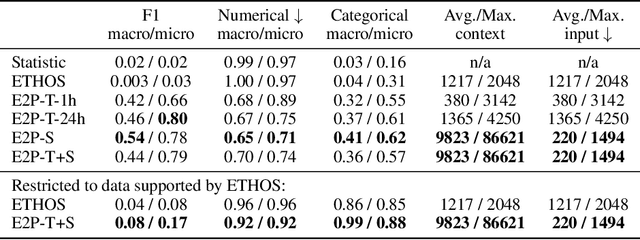
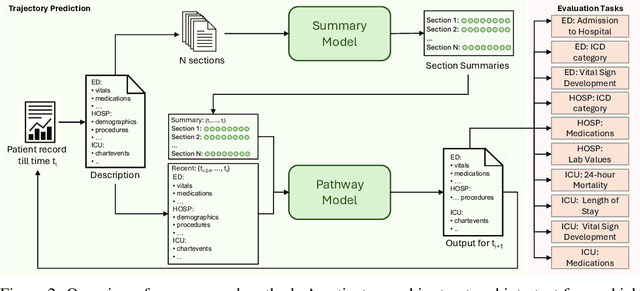
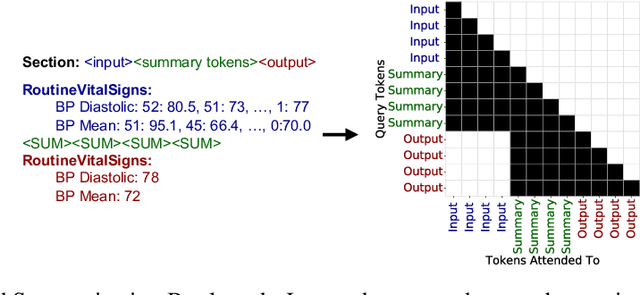
Healthcare systems face significant challenges in managing and interpreting vast, heterogeneous patient data for personalized care. Existing approaches often focus on narrow use cases with a limited feature space, overlooking the complex, longitudinal interactions needed for a holistic understanding of patient health. In this work, we propose a novel approach to patient pathway modeling by transforming diverse electronic health record (EHR) data into a structured representation and designing a holistic pathway prediction model, EHR2Path, optimized to predict future health trajectories. Further, we introduce a novel summary mechanism that embeds long-term temporal context into topic-specific summary tokens, improving performance over text-only models, while being much more token-efficient. EHR2Path demonstrates strong performance in both next time-step prediction and longitudinal simulation, outperforming competitive baselines. It enables detailed simulations of patient trajectories, inherently targeting diverse evaluation tasks, such as forecasting vital signs, lab test results, or length-of-stay, opening a path towards predictive and personalized healthcare.
ORQA: A Benchmark and Foundation Model for Holistic Operating Room Modeling
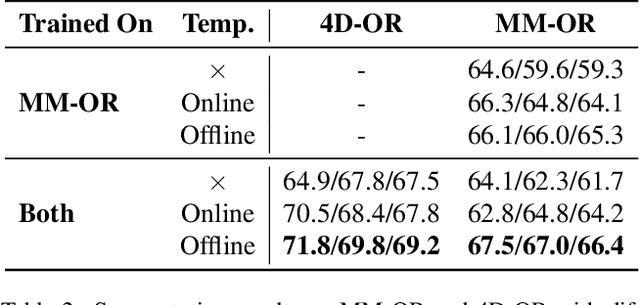
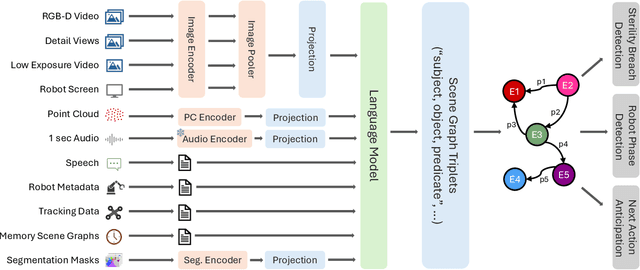
May 19, 2025The real-world complexity of surgeries necessitates surgeons to have deep and holistic comprehension to ensure precision, safety, and effective interventions. Computational systems are required to have a similar level of comprehension within the operating room. Prior works, limited to single-task efforts like phase recognition or scene graph generation, lack scope and generalizability. In this work, we introduce ORQA, a novel OR question answering benchmark and foundational multimodal model to advance OR intelligence. By unifying all four public OR datasets into a comprehensive benchmark, we enable our approach to concurrently address a diverse range of OR challenges. The proposed multimodal large language model fuses diverse OR signals such as visual, auditory, and structured data, for a holistic modeling of the OR. Finally, we propose a novel, progressive knowledge distillation paradigm, to generate a family of models optimized for different speed and memory requirements. We show the strong performance of ORQA on our proposed benchmark, and its zero-shot generalization, paving the way for scalable, unified OR modeling and significantly advancing multimodal surgical intelligence. We will release our code and data upon acceptance.
Rewarding Doubt: A Reinforcement Learning Approach to Confidence Calibration of Large Language Models
Mar 05, 2025



A safe and trustworthy use of Large Language Models (LLMs) requires an accurate expression of confidence in their answers. We introduce a novel Reinforcement Learning (RL) approach for LLM calibration that fine-tunes LLMs to elicit calibrated confidence estimations in their answers to factual questions. We model the problem as a betting game where the model predicts a confidence score together with every answer, and design a reward function that penalizes both over and under-confidence. We prove that under our reward design an optimal policy would result in a perfectly calibrated confidence estimation. Our experiments demonstrate significantly improved confidence calibration and generalization to new tasks without re-training, indicating that our approach teaches a general confidence awareness. This approach enables the training of inherently calibrated LLMs.
MM-OR: A Large Multimodal Operating Room Dataset for Semantic Understanding of High-Intensity Surgical Environments
Mar 04, 2025
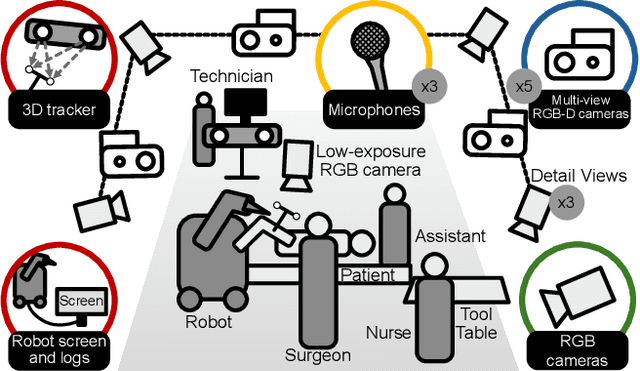
Operating rooms (ORs) are complex, high-stakes environments requiring precise understanding of interactions among medical staff, tools, and equipment for enhancing surgical assistance, situational awareness, and patient safety. Current datasets fall short in scale, realism and do not capture the multimodal nature of OR scenes, limiting progress in OR modeling. To this end, we introduce MM-OR, a realistic and large-scale multimodal spatiotemporal OR dataset, and the first dataset to enable multimodal scene graph generation. MM-OR captures comprehensive OR scenes containing RGB-D data, detail views, audio, speech transcripts, robotic logs, and tracking data and is annotated with panoptic segmentations, semantic scene graphs, and downstream task labels. Further, we propose MM2SG, the first multimodal large vision-language model for scene graph generation, and through extensive experiments, demonstrate its ability to effectively leverage multimodal inputs. Together, MM-OR and MM2SG establish a new benchmark for holistic OR understanding, and open the path towards multimodal scene analysis in complex, high-stakes environments. Our code, and data is available at https://github.com/egeozsoy/MM-OR.
MAGDA: Multi-agent guideline-driven diagnostic assistance
Sep 10, 2024In emergency departments, rural hospitals, or clinics in less developed regions, clinicians often lack fast image analysis by trained radiologists, which can have a detrimental effect on patients' healthcare. Large Language Models (LLMs) have the potential to alleviate some pressure from these clinicians by providing insights that can help them in their decision-making. While these LLMs achieve high test results on medical exams showcasing their great theoretical medical knowledge, they tend not to follow medical guidelines. In this work, we introduce a new approach for zero-shot guideline-driven decision support. We model a system of multiple LLM agents augmented with a contrastive vision-language model that collaborate to reach a patient diagnosis. After providing the agents with simple diagnostic guidelines, they will synthesize prompts and screen the image for findings following these guidelines. Finally, they provide understandable chain-of-thought reasoning for their diagnosis, which is then self-refined to consider inter-dependencies between diseases. As our method is zero-shot, it is adaptable to settings with rare diseases, where training data is limited, but expert-crafted disease descriptions are available. We evaluate our method on two chest X-ray datasets, CheXpert and ChestX-ray 14 Longtail, showcasing performance improvement over existing zero-shot methods and generalizability to rare diseases.
U-GAT: Multimodal Graph Attention Network for COVID-19 Outcome Prediction
Jul 29, 2021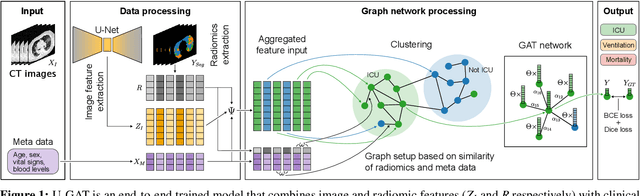
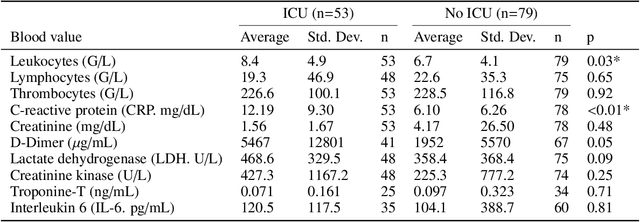
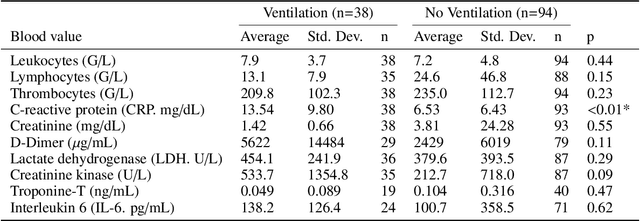
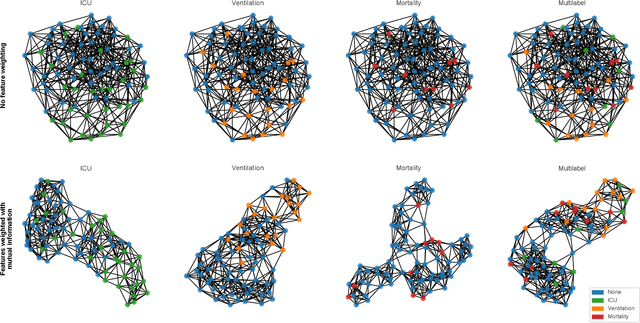
During the first wave of COVID-19, hospitals were overwhelmed with the high number of admitted patients. An accurate prediction of the most likely individual disease progression can improve the planning of limited resources and finding the optimal treatment for patients. However, when dealing with a newly emerging disease such as COVID-19, the impact of patient- and disease-specific factors (e.g. body weight or known co-morbidities) on the immediate course of disease is by and large unknown. In the case of COVID-19, the need for intensive care unit (ICU) admission of pneumonia patients is often determined only by acute indicators such as vital signs (e.g. breathing rate, blood oxygen levels), whereas statistical analysis and decision support systems that integrate all of the available data could enable an earlier prognosis. To this end, we propose a holistic graph-based approach combining both imaging and non-imaging information. Specifically, we introduce a multimodal similarity metric to build a population graph for clustering patients and an image-based end-to-end Graph Attention Network to process this graph and predict the COVID-19 patient outcomes: admission to ICU, need for ventilation and mortality. Additionally, the network segments chest CT images as an auxiliary task and extracts image features and radiomics for feature fusion with the available metadata. Results on a dataset collected in Klinikum rechts der Isar in Munich, Germany show that our approach outperforms single modality and non-graph baselines. Moreover, our clustering and graph attention allow for increased understanding of the patient relationships within the population graph and provide insight into the network's decision-making process.
Decision Support for Intoxication Prediction Using Graph Convolutional Networks
May 02, 2020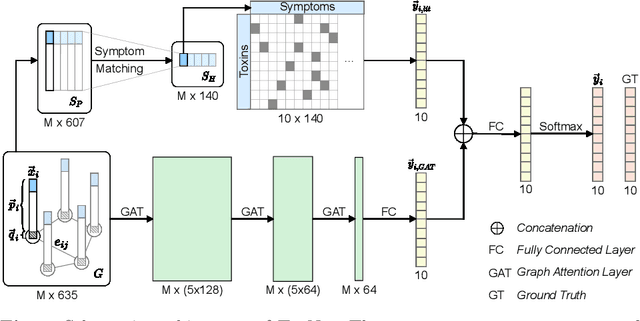
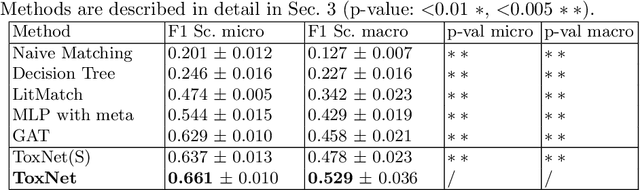
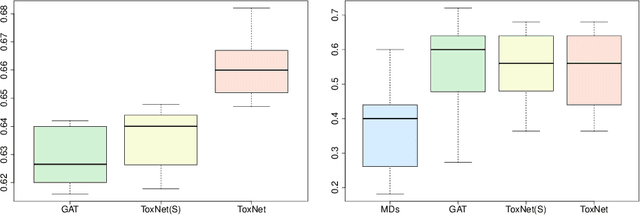
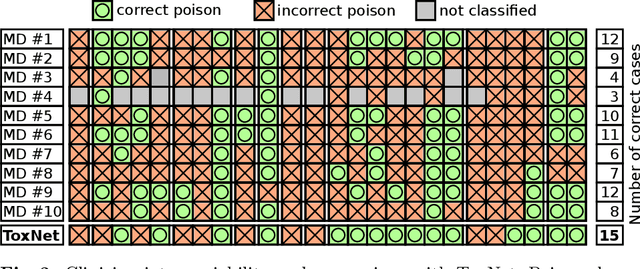
Every day, poison control centers (PCC) are called for immediate classification and treatment recommendations if an acute intoxication is suspected. Due to the time-sensitive nature of these cases, doctors are required to propose a correct diagnosis and intervention within a minimal time frame. Usually the toxin is known and recommendations can be made accordingly. However, in challenging cases only symptoms are mentioned and doctors have to rely on their clinical experience. Medical experts and our analyses of a regional dataset of intoxication records provide evidence that this is challenging, since occurring symptoms may not always match the textbook description due to regional distinctions, inter-rater variance, and institutional workflow. Computer-aided diagnosis (CADx) can provide decision support, but approaches so far do not consider additional information of the reported cases like age or gender, despite their potential value towards a correct diagnosis. In this work, we propose a new machine learning based CADx method which fuses symptoms and meta information of the patients using graph convolutional networks. We further propose a novel symptom matching method that allows the effective incorporation of prior knowledge into the learning process and evidently stabilizes the poison prediction. We validate our method against 10 medical doctors with different experience diagnosing intoxication cases for 10 different toxins from the PCC in Munich and show our method's superiority in performance for poison prediction.