 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConfigurable Embodied Data Generation for Class-Agnostic RGB-D Video Segmentation
Oct 16, 2024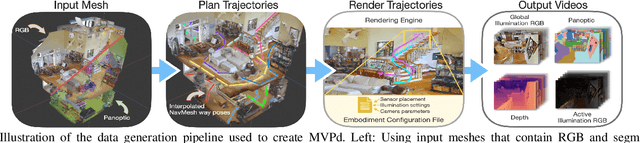

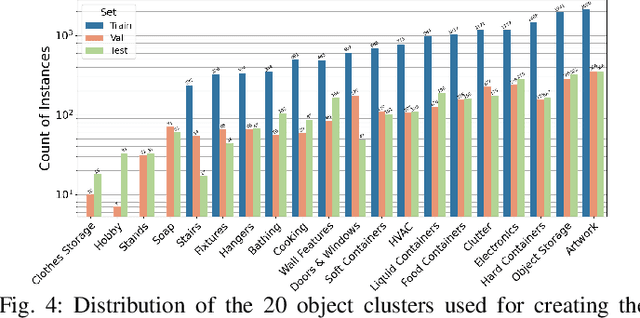
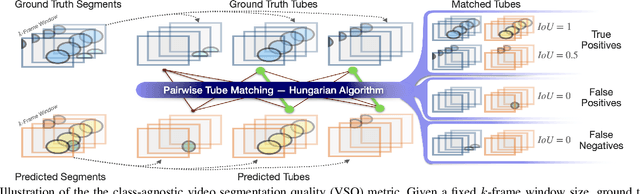
This paper presents a method for generating large-scale datasets to improve class-agnostic video segmentation across robots with different form factors. Specifically, we consider the question of whether video segmentation models trained on generic segmentation data could be more effective for particular robot platforms if robot embodiment is factored into the data generation process. To answer this question, a pipeline is formulated for using 3D reconstructions (e.g. from HM3DSem) to generate segmented videos that are configurable based on a robot's embodiment (e.g. sensor type, sensor placement, and illumination source). A resulting massive RGB-D video panoptic segmentation dataset (MVPd) is introduced for extensive benchmarking with foundation and video segmentation models, as well as to support embodiment-focused research in video segmentation. Our experimental findings demonstrate that using MVPd for finetuning can lead to performance improvements when transferring foundation models to certain robot embodiments, such as specific camera placements. These experiments also show that using 3D modalities (depth images and camera pose) can lead to improvements in video segmentation accuracy and consistency. The project webpage is available at https://topipari.com/projects/MVPd
SupeRGB-D: Zero-shot Instance Segmentation in Cluttered Indoor Environments
Dec 22, 2022



Object instance segmentation is a key challenge for indoor robots navigating cluttered environments with many small objects. Limitations in 3D sensing capabilities often make it difficult to detect every possible object. While deep learning approaches may be effective for this problem, manually annotating 3D data for supervised learning is time-consuming. In this work, we explore zero-shot instance segmentation (ZSIS) from RGB-D data to identify unseen objects in a semantic category-agnostic manner. We introduce a zero-shot split for Tabletop Objects Dataset (TOD-Z) to enable this study and present a method that uses annotated objects to learn the ``objectness'' of pixels and generalize to unseen object categories in cluttered indoor environments. Our method, SupeRGB-D, groups pixels into small patches based on geometric cues and learns to merge the patches in a deep agglomerative clustering fashion. SupeRGB-D outperforms existing baselines on unseen objects while achieving similar performance on seen objects. Additionally, it is extremely lightweight (0.4 MB memory requirement) and suitable for mobile and robotic applications. The dataset split and code will be made publicly available upon acceptance.