 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEdit the Bits, Diff the Codes: Bitwise Residual Editing for Visual Autoregressive Models
Jun 11, 2026Text-guided image editing with visual autoregressive (VAR) generators requires controlling both what the model samples and where the sampled change is written back into the image code. Existing VAR editors mainly operate on token streams, features, or flat next-token logits, leaving two native structures of bitwise-residual VAR models underused: the per-bit Bernoulli prediction head and the additive multi-scale residual code field from which the image is assembled. We propose BitResEdit, a training-free editor for bitwise-residual VAR generators such as Infinity. BitEdit performs source-negative guidance by tilting the post-CFG per-bit log-odds along a source--target contrast computed on a shared edited prefix, then projects each update into a closed-form Bernoulli-KL trust region around the clean CFG sampler. ResEdit converts the sampled bits into per-scale continuous-code residuals, gates them with a localization mask, and re-injects them through the generator's native sum-of-scales. Together they couple decision-time bit guidance with combination-time code composition, so masked-out latent features are preserved exactly by code arithmetic while localized, scale-aware edits are applied inside the target region. On PIE-Bench with Infinity-2B, BitResEdit attains the strongest text alignment among same-backbone VAR editors, improving CLIP on the edited region by +1.07 over the strongest prior editor while keeping background preservation competitive with it. Ablations show BitEdit and ResEdit play complementary roles in target alignment and background preservation.
TunerDiT: Training-free Progressive Steering of Diffusion Transformer for Multi-Event Video Generation
May 29, 2026Text-to-video (T2V) generation faces challenging questions when generating videos with long horizons containing multiple events. Inspired by the intrinsics of the diffusion process, we probe video diffusion transformers (DiTs) and uncover intrinsic turning points in the DiT denoising trajectory where conditioning text affects generation from global layout to fine-grained details. Building on this finding, we present TunerDiT, a simple yet effective progressive steering method that requires no additional training for multi-event generation. TunerDiT comprises two steering handles: (1) Event-Partitioned Masking that enforces event boundaries while allowing cross-event transition bands; (2) Cross-Event Prompt Fusion that injects neighboring event semantics for late-stage refinement. We contribute a self-curated prompt suite for benchmarking multi-event generation, i.e., Meve. TunerDiT achieves state-of-the-art performance across 8 metrics and offers a tunable trade-off between video consistency and event separation, compared with other training-free methods. The improvement in text alignment increases with the event count, indicating a scaling possibility with increasing event count.
Tool Verification for Test-Time Reinforcement Learning
Mar 02, 2026Test-time reinforcement learning (TTRL) has emerged as a promising paradigm for self-evolving large reasoning models (LRMs), enabling online adaptation on unlabeled test inputs via self-induced rewards through majority voting. However, a spurious yet high-frequency unverified consensus can become a biased and reinforced reward signal, leading to incorrect mode collapse. We address this failure mode with T^3RL (Tool-Verification for Test-Time Reinforcement Learning), which introduces test-time tool verification into reward estimation. Concretely, a verifier uses an external tool as evidence (e.g., from code execution) to upweight verified rollouts in a verification-aware voting, producing more reliable pseudo-labels for training. Across various math difficulties (MATH-500, AMC, and AIME 2024) and diverse backbone types, T^3RL significantly improves over TTRL, with larger gains on harder problems. More broadly, T^3RL can be viewed as verified online data synthesis, highlighting test-time tool verification as a key mechanism for stabilizing self-evolution.
VideoINSTA: Zero-shot Long Video Understanding via Informative Spatial-Temporal Reasoning with LLMs
Sep 30, 2024



In the video-language domain, recent works in leveraging zero-shot Large Language Model-based reasoning for video understanding have become competitive challengers to previous end-to-end models. However, long video understanding presents unique challenges due to the complexity of reasoning over extended timespans, even for zero-shot LLM-based approaches. The challenge of information redundancy in long videos prompts the question of what specific information is essential for large language models (LLMs) and how to leverage them for complex spatial-temporal reasoning in long-form video analysis. We propose a framework VideoINSTA, i.e. INformative Spatial-TemporAl Reasoning for zero-shot long-form video understanding. VideoINSTA contributes (1) a zero-shot framework for long video understanding using LLMs; (2) an event-based temporal reasoning and content-based spatial reasoning approach for LLMs to reason over spatial-temporal information in videos; (3) a self-reflective information reasoning scheme balancing temporal factors based on information sufficiency and prediction confidence. Our model significantly improves the state-of-the-art on three long video question-answering benchmarks: EgoSchema, NextQA, and IntentQA, and the open question answering dataset ActivityNetQA. The code is released here: https://github.com/mayhugotong/VideoINSTA.
EchoScene: Indoor Scene Generation via Information Echo over Scene Graph Diffusion
May 02, 2024We present EchoScene, an interactive and controllable generative model that generates 3D indoor scenes on scene graphs. EchoScene leverages a dual-branch diffusion model that dynamically adapts to scene graphs. Existing methods struggle to handle scene graphs due to varying numbers of nodes, multiple edge combinations, and manipulator-induced node-edge operations. EchoScene overcomes this by associating each node with a denoising process and enables collaborative information exchange, enhancing controllable and consistent generation aware of global constraints. This is achieved through an information echo scheme in both shape and layout branches. At every denoising step, all processes share their denoising data with an information exchange unit that combines these updates using graph convolution. The scheme ensures that the denoising processes are influenced by a holistic understanding of the scene graph, facilitating the generation of globally coherent scenes. The resulting scenes can be manipulated during inference by editing the input scene graph and sampling the noise in the diffusion model. Extensive experiments validate our approach, which maintains scene controllability and surpasses previous methods in generation fidelity. Moreover, the generated scenes are of high quality and thus directly compatible with off-the-shelf texture generation. Code and trained models are open-sourced.
Zero-Shot Relational Learning on Temporal Knowledge Graphs with Large Language Models
Nov 15, 2023
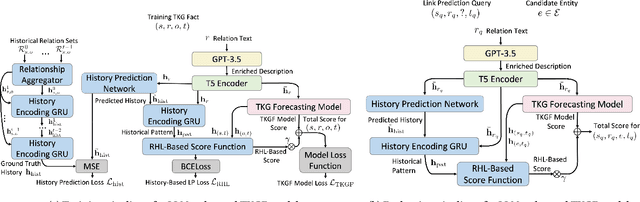

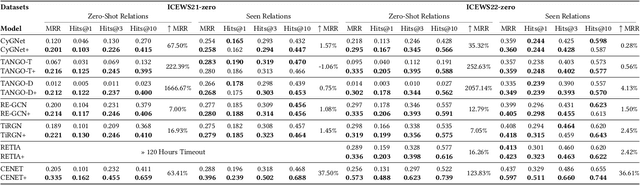
In recent years, modeling evolving knowledge over temporal knowledge graphs (TKGs) has become a heated topic. Various methods have been proposed to forecast links on TKGs. Most of them are embedding-based, where hidden representations are learned to represent knowledge graph (KG) entities and relations based on the observed graph contexts. Although these methods show strong performance on traditional TKG forecasting (TKGF) benchmarks, they naturally face a strong challenge when they are asked to model the unseen zero-shot relations that has no prior graph context. In this paper, we try to mitigate this problem as follows. We first input the text descriptions of KG relations into large language models (LLMs) for generating relation representations, and then introduce them into embedding-based TKGF methods. LLM-empowered representations can capture the semantic information in the relation descriptions. This makes the relations, whether seen or unseen, with similar semantic meanings stay close in the embedding space, enabling TKGF models to recognize zero-shot relations even without any observed graph context. Experimental results show that our approach helps TKGF models to achieve much better performance in forecasting the facts with previously unseen relations, while still maintaining their ability in link forecasting regarding seen relations.
GraphextQA: A Benchmark for Evaluating Graph-Enhanced Large Language Models
Oct 12, 2023
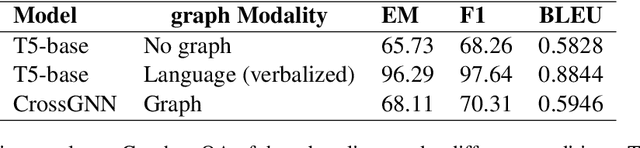
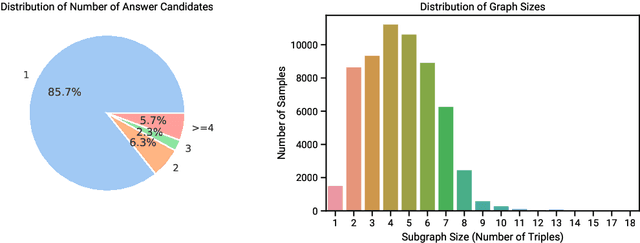
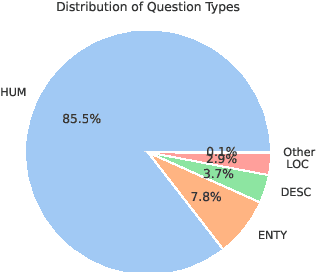
While multi-modal models have successfully integrated information from image, video, and audio modalities, integrating graph modality into large language models (LLMs) remains unexplored. This discrepancy largely stems from the inherent divergence between structured graph data and unstructured text data. Incorporating graph knowledge provides a reliable source of information, enabling potential solutions to address issues in text generation, e.g., hallucination, and lack of domain knowledge. To evaluate the integration of graph knowledge into language models, a dedicated dataset is needed. However, there is currently no benchmark dataset specifically designed for multimodal graph-language models. To address this gap, we propose GraphextQA, a question answering dataset with paired subgraphs, retrieved from Wikidata, to facilitate the evaluation and future development of graph-language models. Additionally, we introduce a baseline model called CrossGNN, which conditions answer generation on the paired graphs by cross-attending question-aware graph features at decoding. The proposed dataset is designed to evaluate graph-language models' ability to understand graphs and make use of it for answer generation. We perform experiments with language-only models and the proposed graph-language model to validate the usefulness of the paired graphs and to demonstrate the difficulty of the task.
GenTKG: Generative Forecasting on Temporal Knowledge Graph
Oct 11, 2023

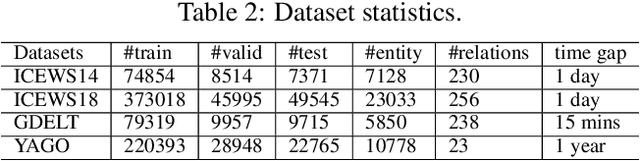

The rapid advancements in large language models (LLMs) have ignited interest in the temporal knowledge graph (tKG) domain, where conventional carefully designed embedding-based and rule-based models dominate. The question remains open of whether pre-trained LLMs can understand structured temporal relational data and replace them as the foundation model for temporal relational forecasting. Therefore, we bring temporal knowledge forecasting into the generative setting. However, challenges occur in the huge chasms between complex temporal graph data structure and sequential natural expressions LLMs can handle, and between the enormous data sizes of tKGs and heavy computation costs of finetuning LLMs. To address these challenges, we propose a novel retrieval augmented generation framework that performs generative forecasting on tKGs named GenTKG, which combines a temporal logical rule-based retrieval strategy and lightweight parameter-efficient instruction tuning. Extensive experiments have shown that GenTKG outperforms conventional methods of temporal relational forecasting under low computation resources. GenTKG also highlights remarkable transferability with exceeding performance on unseen datasets without re-training. Our work reveals the huge potential of LLMs in the tKG domain and opens a new frontier for generative forecasting on tKGs.
A Systematic Survey of Prompt Engineering on Vision-Language Foundation Models
Jul 24, 2023Prompt engineering is a technique that involves augmenting a large pre-trained model with task-specific hints, known as prompts, to adapt the model to new tasks. Prompts can be created manually as natural language instructions or generated automatically as either natural language instructions or vector representations. Prompt engineering enables the ability to perform predictions based solely on prompts without updating model parameters, and the easier application of large pre-trained models in real-world tasks. In past years, Prompt engineering has been well-studied in natural language processing. Recently, it has also been intensively studied in vision-language modeling. However, there is currently a lack of a systematic overview of prompt engineering on pre-trained vision-language models. This paper aims to provide a comprehensive survey of cutting-edge research in prompt engineering on three types of vision-language models: multimodal-to-text generation models (e.g. Flamingo), image-text matching models (e.g. CLIP), and text-to-image generation models (e.g. Stable Diffusion). For each type of model, a brief model summary, prompting methods, prompting-based applications, and the corresponding responsibility and integrity issues are summarized and discussed. Furthermore, the commonalities and differences between prompting on vision-language models, language models, and vision models are also discussed. The challenges, future directions, and research opportunities are summarized to foster future research on this topic.
Enhanced Temporal Knowledge Embeddings with Contextualized Language Representations
Mar 21, 2022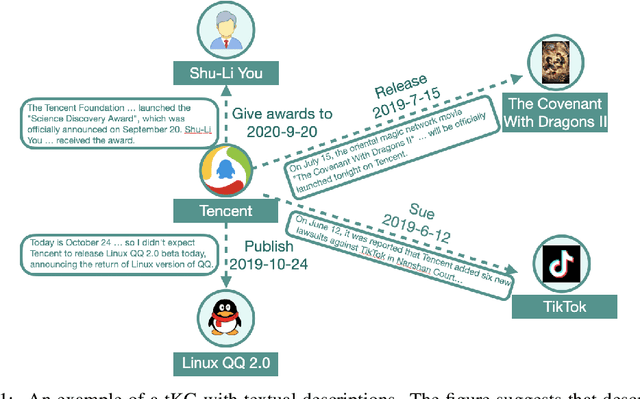

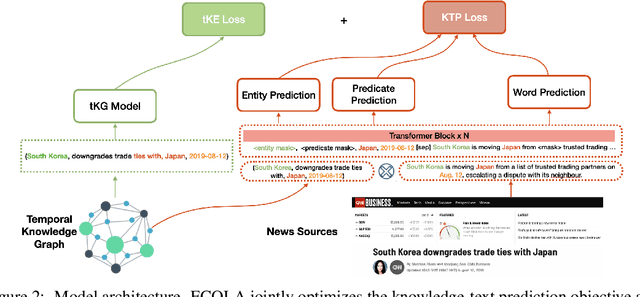
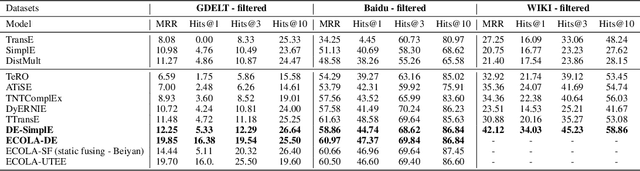
With the emerging research effort to integrate structured and unstructured knowledge, many approaches incorporate factual knowledge into pre-trained language models (PLMs) and apply the knowledge-enhanced PLMs on downstream NLP tasks. However, (1) they only consider static factual knowledge, but knowledge graphs (KGs) also contain temporal facts or events indicating evolutionary relationships among entities at different timestamps. (2) PLMs cannot be directly applied to many KG tasks, such as temporal KG completion. In this paper, we focus on \textbf{e}nhancing temporal knowledge embeddings with \textbf{co}ntextualized \textbf{la}nguage representations (ECOLA). We align structured knowledge contained in temporal knowledge graphs with their textual descriptions extracted from news articles and propose a novel knowledge-text prediction task to inject the abundant information from descriptions into temporal knowledge embeddings. ECOLA jointly optimizes the knowledge-text prediction objective and the temporal knowledge embeddings, which can simultaneously take full advantage of textual and knowledge information. For training ECOLA, we introduce three temporal KG datasets with aligned textual descriptions. Experimental results on the temporal knowledge graph completion task show that ECOLA outperforms state-of-the-art temporal KG models by a large margin. The proposed datasets can serve as new temporal KG benchmarks and facilitate future research on structured and unstructured knowledge integration.