 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraphextQA: A Benchmark for Evaluating Graph-Enhanced Large Language Models
Oct 12, 2023
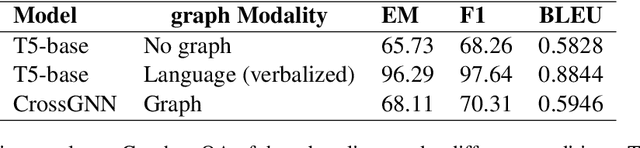
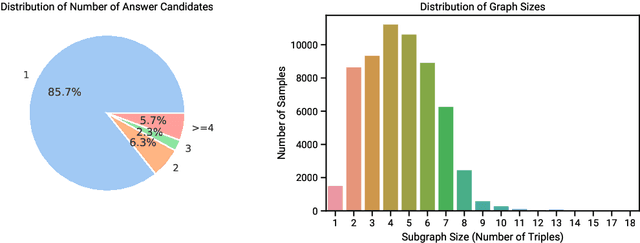
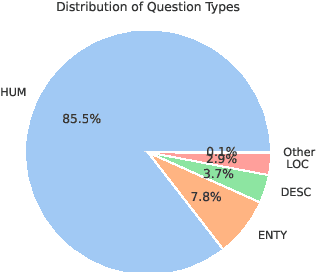
While multi-modal models have successfully integrated information from image, video, and audio modalities, integrating graph modality into large language models (LLMs) remains unexplored. This discrepancy largely stems from the inherent divergence between structured graph data and unstructured text data. Incorporating graph knowledge provides a reliable source of information, enabling potential solutions to address issues in text generation, e.g., hallucination, and lack of domain knowledge. To evaluate the integration of graph knowledge into language models, a dedicated dataset is needed. However, there is currently no benchmark dataset specifically designed for multimodal graph-language models. To address this gap, we propose GraphextQA, a question answering dataset with paired subgraphs, retrieved from Wikidata, to facilitate the evaluation and future development of graph-language models. Additionally, we introduce a baseline model called CrossGNN, which conditions answer generation on the paired graphs by cross-attending question-aware graph features at decoding. The proposed dataset is designed to evaluate graph-language models' ability to understand graphs and make use of it for answer generation. We perform experiments with language-only models and the proposed graph-language model to validate the usefulness of the paired graphs and to demonstrate the difficulty of the task.
SRTK: A Toolkit for Semantic-relevant Subgraph Retrieval
May 11, 2023Semantic analysis based on knowledge graphs requires a relevant subgraph of a reasonable size. Existing approaches have three issues that impede the integration of such subgraphs. First, there is no off-the-shelf framework for semantic-relevant subgraph retrieval. Second, existing approaches are knowledge-graph-dependent, resulting in outdated knowledge graphs even in recent studies. Third, existing approaches are flawed either in entity linking or path expansion, which often results in huge subgraphs. In this paper, we present SRTK, a user-friendly toolkit for semantic-relevant subgraph retrieval from large-scale knowledge graphs. SRTK is the first toolkit that streamlines the entire lifecycle of subgraph retrieval, from development (preprocessing, training, and evaluation) to applications (entity linking, retrieving and visualizing). Moreover, It supports Wikidata, Freebase and DBpedia by defining unified access interfaces across different knowledge graphs. Additionally, it ships with a state-of-the-art subgraph retrieval algorithm out of the box. We evaluate the toolkit on Wikidata and Freebase and demonstrate its ability to retrieve semantically relevant subgraphs for a given natural query.