 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge6D Object Pose Tracking in Internet Videos for Robotic Manipulation
Mar 13, 2025



We seek to extract a temporally consistent 6D pose trajectory of a manipulated object from an Internet instructional video. This is a challenging set-up for current 6D pose estimation methods due to uncontrolled capturing conditions, subtle but dynamic object motions, and the fact that the exact mesh of the manipulated object is not known. To address these challenges, we present the following contributions. First, we develop a new method that estimates the 6D pose of any object in the input image without prior knowledge of the object itself. The method proceeds by (i) retrieving a CAD model similar to the depicted object from a large-scale model database, (ii) 6D aligning the retrieved CAD model with the input image, and (iii) grounding the absolute scale of the object with respect to the scene. Second, we extract smooth 6D object trajectories from Internet videos by carefully tracking the detected objects across video frames. The extracted object trajectories are then retargeted via trajectory optimization into the configuration space of a robotic manipulator. Third, we thoroughly evaluate and ablate our 6D pose estimation method on YCB-V and HOPE-Video datasets as well as a new dataset of instructional videos manually annotated with approximate 6D object trajectories. We demonstrate significant improvements over existing state-of-the-art RGB 6D pose estimation methods. Finally, we show that the 6D object motion estimated from Internet videos can be transferred to a 7-axis robotic manipulator both in a virtual simulator as well as in a real world set-up. We also successfully apply our method to egocentric videos taken from the EPIC-KITCHENS dataset, demonstrating potential for Embodied AI applications.
FoundPose: Unseen Object Pose Estimation with Foundation Features
Nov 30, 2023



We propose FoundPose, a method for 6D pose estimation of unseen rigid objects from a single RGB image. The method assumes that 3D models of the objects are available but does not require any object-specific training. This is achieved by building upon DINOv2, a recent vision foundation model with impressive generalization capabilities. An online pose estimation stage is supported by a minimal object representation that is built during a short onboarding stage from DINOv2 patch features extracted from rendered object templates. Given a query image with an object segmentation mask, FoundPose first rapidly retrieves a handful of similarly looking templates by a DINOv2-based bag-of-words approach. Pose hypotheses are then generated from 2D-3D correspondences established by matching DINOv2 patch features between the query image and a retrieved template, and finally optimized by featuremetric refinement. The method can handle diverse objects, including challenging ones with symmetries and without any texture, and noticeably outperforms existing RGB methods for coarse pose estimation in both accuracy and speed on the standard BOP benchmark. With the featuremetric and additional MegaPose refinement, which are demonstrated complementary, the method outperforms all RGB competitors. Source code is at: evinpinar.github.io/foundpose.
MegaPose: 6D Pose Estimation of Novel Objects via Render & Compare
Dec 13, 2022



We introduce MegaPose, a method to estimate the 6D pose of novel objects, that is, objects unseen during training. At inference time, the method only assumes knowledge of (i) a region of interest displaying the object in the image and (ii) a CAD model of the observed object. The contributions of this work are threefold. First, we present a 6D pose refiner based on a render&compare strategy which can be applied to novel objects. The shape and coordinate system of the novel object are provided as inputs to the network by rendering multiple synthetic views of the object's CAD model. Second, we introduce a novel approach for coarse pose estimation which leverages a network trained to classify whether the pose error between a synthetic rendering and an observed image of the same object can be corrected by the refiner. Third, we introduce a large-scale synthetic dataset of photorealistic images of thousands of objects with diverse visual and shape properties and show that this diversity is crucial to obtain good generalization performance on novel objects. We train our approach on this large synthetic dataset and apply it without retraining to hundreds of novel objects in real images from several pose estimation benchmarks. Our approach achieves state-of-the-art performance on the ModelNet and YCB-Video datasets. An extensive evaluation on the 7 core datasets of the BOP challenge demonstrates that our approach achieves performance competitive with existing approaches that require access to the target objects during training. Code, dataset and trained models are available on the project page: https://megapose6d.github.io/.
Focal Length and Object Pose Estimation via Render and Compare
Apr 11, 2022

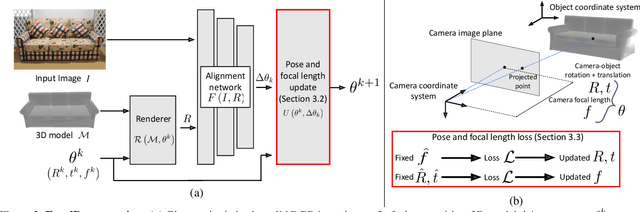

We introduce FocalPose, a neural render-and-compare method for jointly estimating the camera-object 6D pose and camera focal length given a single RGB input image depicting a known object. The contributions of this work are twofold. First, we derive a focal length update rule that extends an existing state-of-the-art render-and-compare 6D pose estimator to address the joint estimation task. Second, we investigate several different loss functions for jointly estimating the object pose and focal length. We find that a combination of direct focal length regression with a reprojection loss disentangling the contribution of translation, rotation, and focal length leads to improved results. We show results on three challenging benchmark datasets that depict known 3D models in uncontrolled settings. We demonstrate that our focal length and 6D pose estimates have lower error than the existing state-of-the-art methods.
Single-view robot pose and joint angle estimation via render & compare
Apr 19, 2021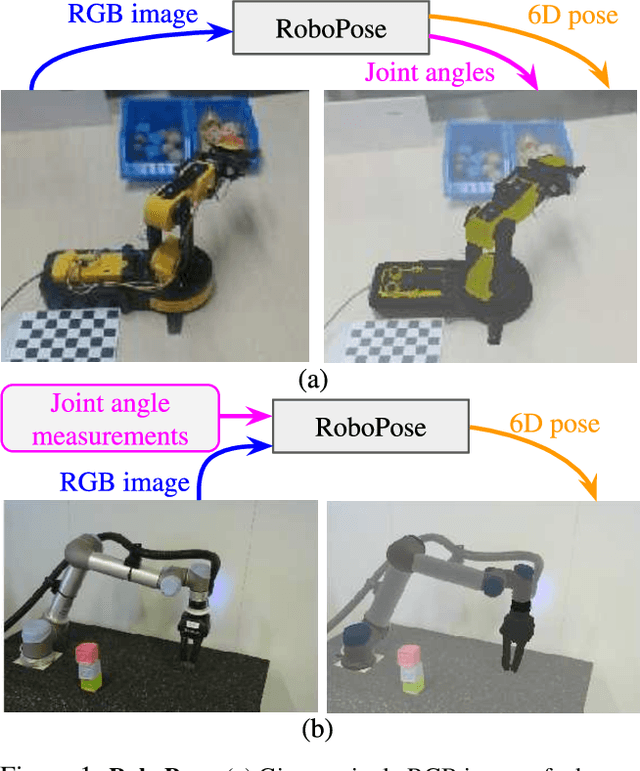


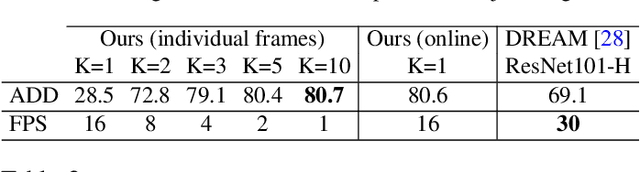
We introduce RoboPose, a method to estimate the joint angles and the 6D camera-to-robot pose of a known articulated robot from a single RGB image. This is an important problem to grant mobile and itinerant autonomous systems the ability to interact with other robots using only visual information in non-instrumented environments, especially in the context of collaborative robotics. It is also challenging because robots have many degrees of freedom and an infinite space of possible configurations that often result in self-occlusions and depth ambiguities when imaged by a single camera. The contributions of this work are three-fold. First, we introduce a new render & compare approach for estimating the 6D pose and joint angles of an articulated robot that can be trained from synthetic data, generalizes to new unseen robot configurations at test time, and can be applied to a variety of robots. Second, we experimentally demonstrate the importance of the robot parametrization for the iterative pose updates and design a parametrization strategy that is independent of the robot structure. Finally, we show experimental results on existing benchmark datasets for four different robots and demonstrate that our method significantly outperforms the state of the art. Code and pre-trained models are available on the project webpage https://www.di.ens.fr/willow/research/robopose/.
CosyPose: Consistent multi-view multi-object 6D pose estimation
Aug 19, 2020

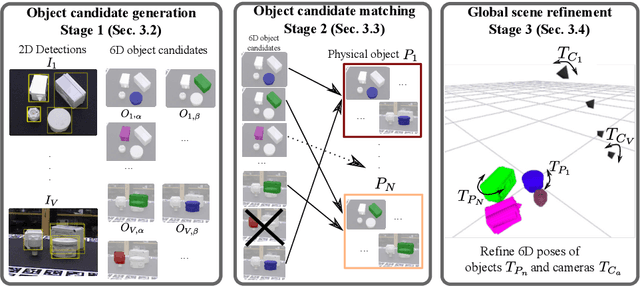

We introduce an approach for recovering the 6D pose of multiple known objects in a scene captured by a set of input images with unknown camera viewpoints. First, we present a single-view single-object 6D pose estimation method, which we use to generate 6D object pose hypotheses. Second, we develop a robust method for matching individual 6D object pose hypotheses across different input images in order to jointly estimate camera viewpoints and 6D poses of all objects in a single consistent scene. Our approach explicitly handles object symmetries, does not require depth measurements, is robust to missing or incorrect object hypotheses, and automatically recovers the number of objects in the scene. Third, we develop a method for global scene refinement given multiple object hypotheses and their correspondences across views. This is achieved by solving an object-level bundle adjustment problem that refines the poses of cameras and objects to minimize the reprojection error in all views. We demonstrate that the proposed method, dubbed CosyPose, outperforms current state-of-the-art results for single-view and multi-view 6D object pose estimation by a large margin on two challenging benchmarks: the YCB-Video and T-LESS datasets. Code and pre-trained models are available on the project webpage https://www.di.ens.fr/willow/research/cosypose/.
Monte-Carlo Tree Search for Efficient Visually Guided Rearrangement Planning
Apr 23, 2019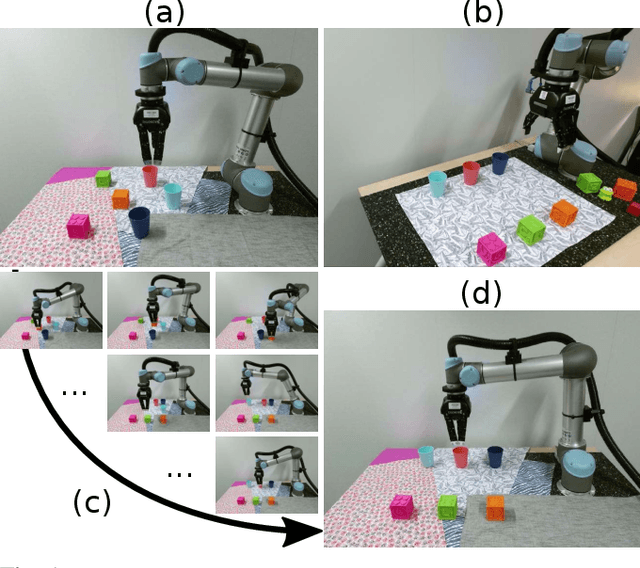
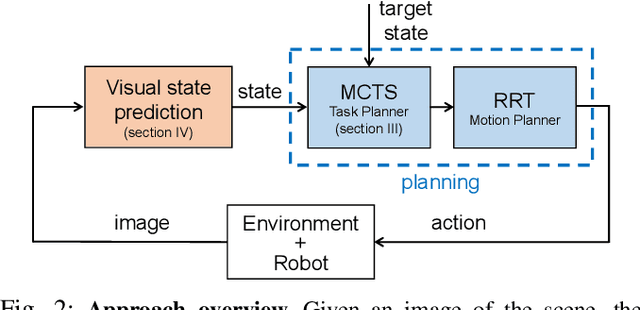
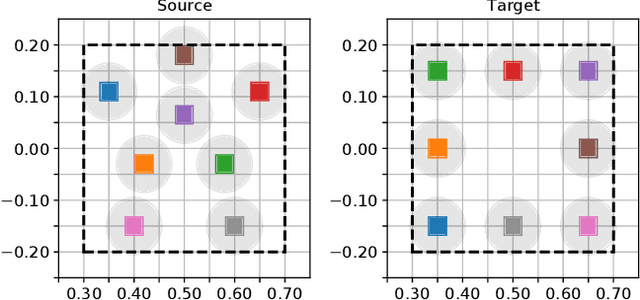
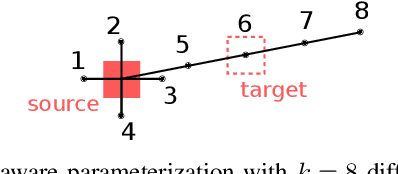
In this paper, we address the problem of visually guided rearrangement planning with many movable objects, i.e., finding a sequence of actions to move a set of objects from an initial arrangement to a desired one, while relying directly on visual inputs coming from a camera. We introduce an efficient and scalable rearrangement planning method, addressing a fundamental limitation of most existing approaches that do not scale well with the number of objects. This increased efficiency allows us to use planning in a closed loop with visual workspace analysis to build a robust rearrangement framework that can recover from errors and external perturbations. The contributions of this work are threefold. First, we develop an AlphaGo-like strategy for rearrangement planning, improving the efficiency of Monte-Carlo Tree Search (MCTS) using a policy trained from rearrangement planning examples. We show empirically that the proposed approach scales well with the number of objects. Second, in order to demonstrate the efficiency of the planner on a real robot, we adopt a state-of-the-art calibration-free visual recognition system that outputs position of a single object and extend it to estimate the state of a workspace containing multiple objects. Third, we validate the complete pipeline with several experiments on a real UR-5 robotic arm solving rearrangement planning problems with multiple movable objects and only requiring few seconds of computation to compute the plan. We also show empirically that the robot can successfully recover from errors and perturbations in the workspace. Source code and pretrained models for our work are available at https://github.com/ylabbe/rearrangement-planning