 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning visual policies for building 3D shape categories
Apr 15, 2020

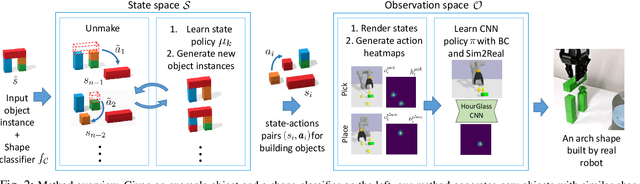
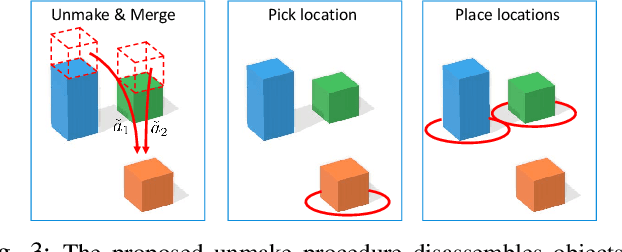
Manipulation and assembly tasks require non-trivial planning of actions depending on the environment and the final goal. Previous work in this domain often assembles particular instances of objects from known sets of primitives. In contrast, we here aim to handle varying sets of primitives and to construct different objects of the same shape category. Given a single object instance of a category, e.g. an arch, and a binary shape classifier, we learn a visual policy to assemble other instances of the same category. In particular, we propose a disassembly procedure and learn a state policy that discovers new object instances and their assembly plans in state space. We then render simulated states in the observation space and learn a heatmap representation to predict alternative actions from a given input image. To validate our approach, we first demonstrate its efficiency for building object categories in state space. We then show the success of our visual policies for building arches from different primitives. Moreover, we demonstrate (i) the reactive ability of our method to re-assemble objects using additional primitives and (ii) the robust performance of our policy for unseen primitives resembling building blocks used during training. Our visual assembly policies are trained with no real images and reach up to 95% success rate when evaluated on a real robot.
Combining learned skills and reinforcement learning for robotic manipulations
Aug 02, 2019

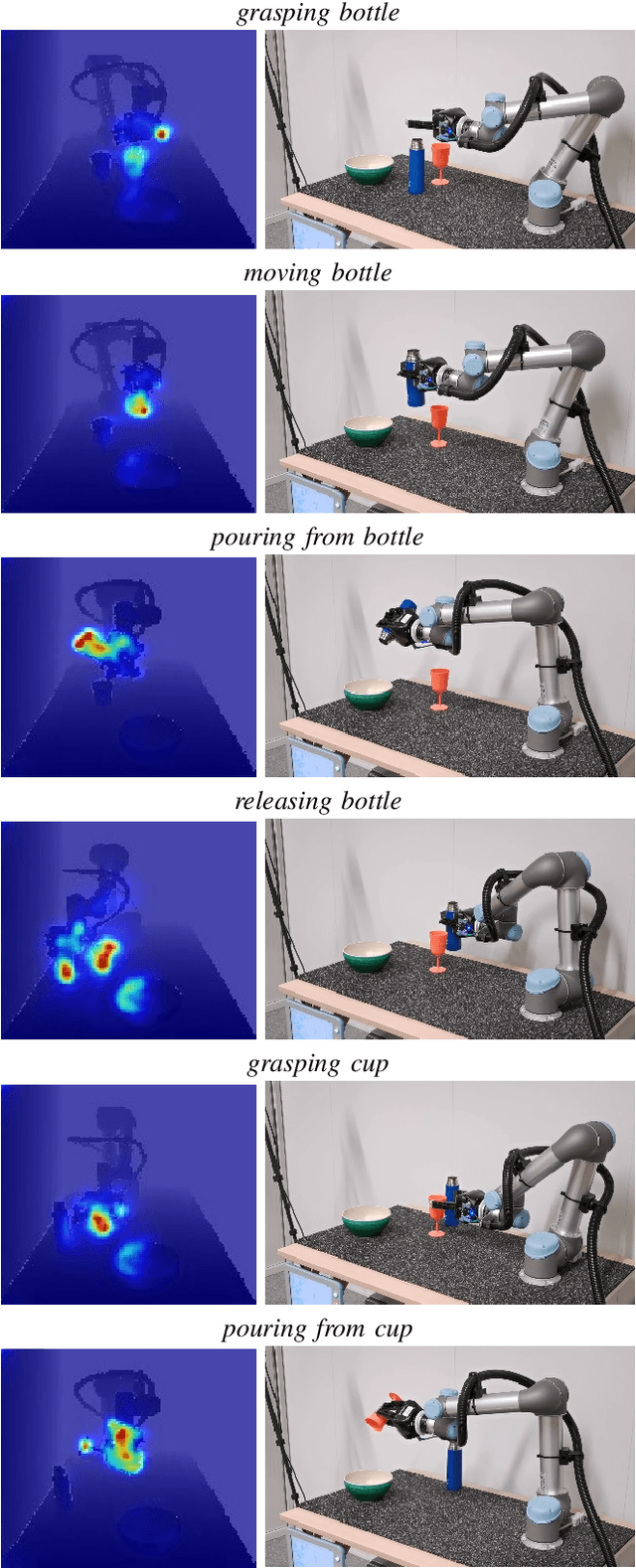

Manipulation tasks such as preparing a meal or assembling furniture remain highly challenging for robotics and vision. The supervised approach of imitation learning can handle short tasks but suffers from compounding errors and the need of many demonstrations for longer and more complex tasks. Reinforcement learning (RL) can find solutions beyond demonstrations but requires tedious and task-specific reward engineering for multi-step problems. In this work we address the difficulties of both methods and explore their combination. To this end, we propose a RL policies operating on pre-trained skills, that can learn composite manipulations using no intermediate rewards and no demonstrations of full tasks. We also propose an efficient training of basic skills from few synthetic demonstrated trajectories by exploring recent CNN architectures and data augmentation. We show successful learning of policies for composite manipulation tasks such as making a simple breakfast. Notably, our method achieves high success rates on a real robot, while using synthetic training data only.
Monte-Carlo Tree Search for Efficient Visually Guided Rearrangement Planning
Apr 23, 2019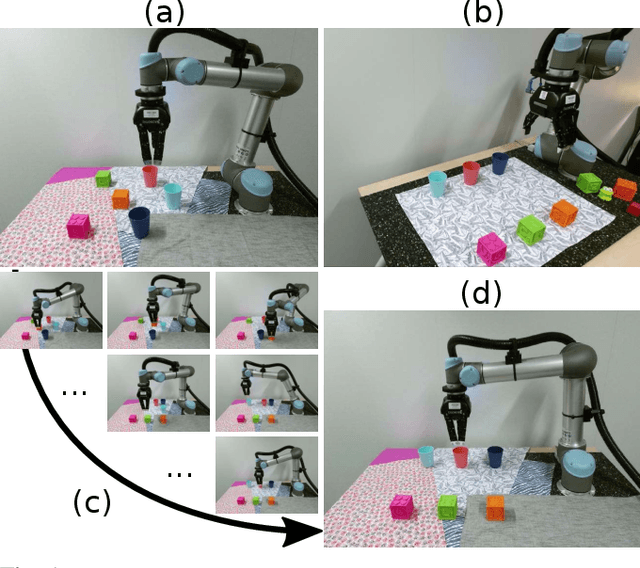
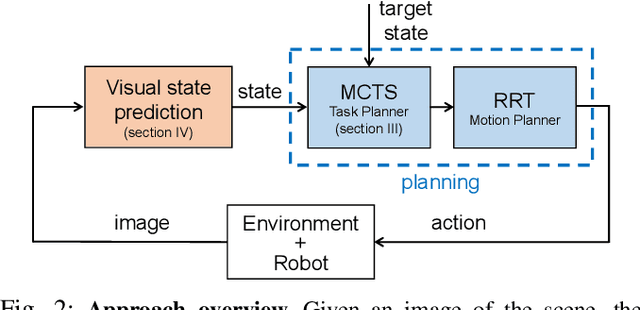
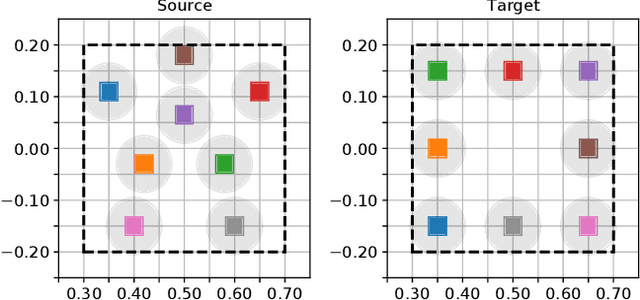
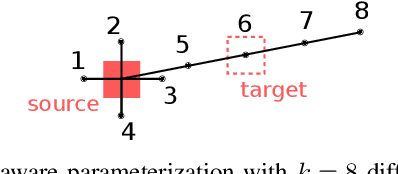
In this paper, we address the problem of visually guided rearrangement planning with many movable objects, i.e., finding a sequence of actions to move a set of objects from an initial arrangement to a desired one, while relying directly on visual inputs coming from a camera. We introduce an efficient and scalable rearrangement planning method, addressing a fundamental limitation of most existing approaches that do not scale well with the number of objects. This increased efficiency allows us to use planning in a closed loop with visual workspace analysis to build a robust rearrangement framework that can recover from errors and external perturbations. The contributions of this work are threefold. First, we develop an AlphaGo-like strategy for rearrangement planning, improving the efficiency of Monte-Carlo Tree Search (MCTS) using a policy trained from rearrangement planning examples. We show empirically that the proposed approach scales well with the number of objects. Second, in order to demonstrate the efficiency of the planner on a real robot, we adopt a state-of-the-art calibration-free visual recognition system that outputs position of a single object and extend it to estimate the state of a workspace containing multiple objects. Third, we validate the complete pipeline with several experiments on a real UR-5 robotic arm solving rearrangement planning problems with multiple movable objects and only requiring few seconds of computation to compute the plan. We also show empirically that the robot can successfully recover from errors and perturbations in the workspace. Source code and pretrained models for our work are available at https://github.com/ylabbe/rearrangement-planning
Learning joint reconstruction of hands and manipulated objects
Apr 11, 2019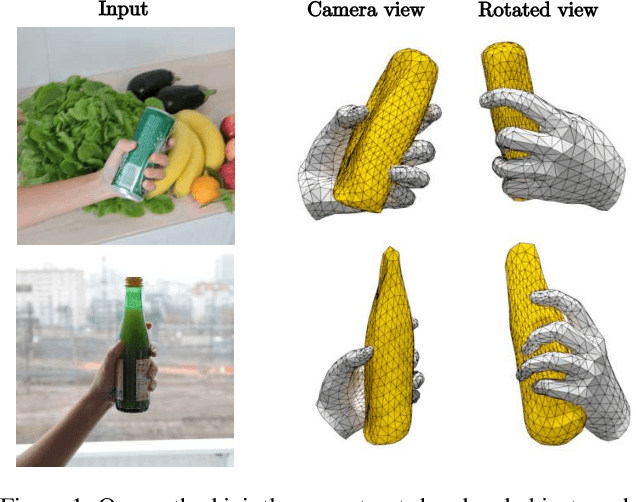
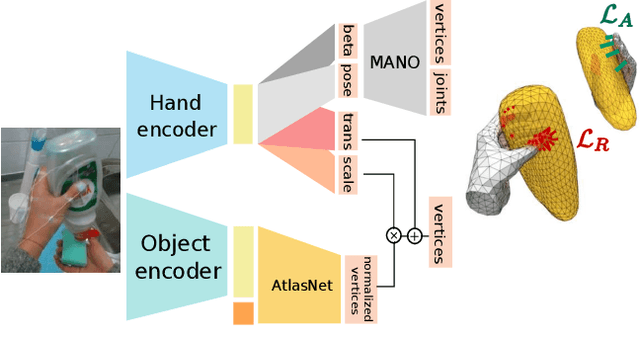

Estimating hand-object manipulations is essential for interpreting and imitating human actions. Previous work has made significant progress towards reconstruction of hand poses and object shapes in isolation. Yet, reconstructing hands and objects during manipulation is a more challenging task due to significant occlusions of both the hand and object. While presenting challenges, manipulations may also simplify the problem since the physics of contact restricts the space of valid hand-object configurations. For example, during manipulation, the hand and object should be in contact but not interpenetrate. In this work, we regularize the joint reconstruction of hands and objects with manipulation constraints. We present an end-to-end learnable model that exploits a novel contact loss that favors physically plausible hand-object constellations. Our approach improves grasp quality metrics over baselines, using RGB images as input. To train and evaluate the model, we also propose a new large-scale synthetic dataset, ObMan, with hand-object manipulations. We demonstrate the transferability of ObMan-trained models to real data.
Learning to Augment Synthetic Images for Sim2Real Policy Transfer
Mar 18, 2019
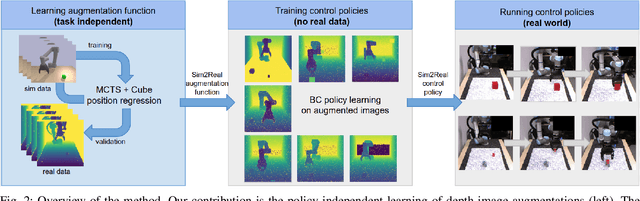
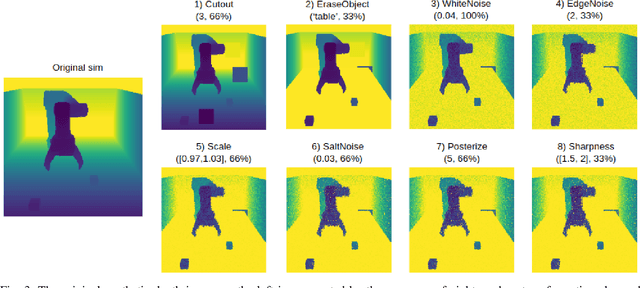

Vision and learning have made significant progress that could improve robotics policies for complex tasks and environments. Learning deep neural networks for image understanding, however, requires large amounts of domain-specific visual data. While collecting such data from real robots is possible, such an approach limits the scalability as learning policies typically requires thousands of trials. In this work we attempt to learn manipulation policies in simulated environments. Simulators enable scalability and provide access to the underlying world state during training. Policies learned in simulators, however, do not transfer well to real scenes given the domain gap between real and synthetic data. We follow recent work on domain randomization and augment synthetic images with sequences of random transformations. Our main contribution is to optimize the augmentation strategy for sim2real transfer and to enable domain-independent policy learning. We design an efficient search for depth image augmentations using object localization as a proxy task. Given the resulting sequence of random transformations, we use it to augment synthetic depth images during policy learning. Our augmentation strategy is policy-independent and enables policy learning with no real images. We demonstrate our approach to significantly improve accuracy on three manipulation tasks evaluated on a real robot.