 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEpisodic Transformer for Vision-and-Language Navigation
May 13, 2021
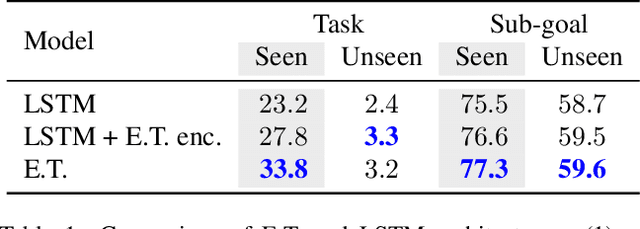
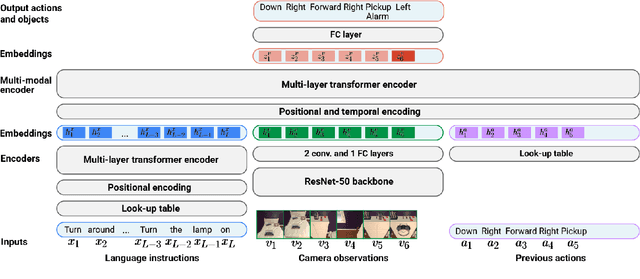
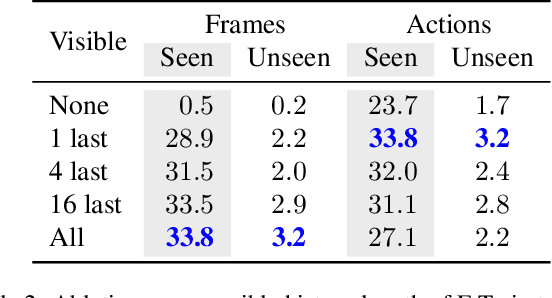
Interaction and navigation defined by natural language instructions in dynamic environments pose significant challenges for neural agents. This paper focuses on addressing two challenges: handling long sequence of subtasks, and understanding complex human instructions. We propose Episodic Transformer (E.T.), a multimodal transformer that encodes language inputs and the full episode history of visual observations and actions. To improve training, we leverage synthetic instructions as an intermediate representation that decouples understanding the visual appearance of an environment from the variations of natural language instructions. We demonstrate that encoding the history with a transformer is critical to solve compositional tasks, and that pretraining and joint training with synthetic instructions further improve the performance. Our approach sets a new state of the art on the challenging ALFRED benchmark, achieving 38.4% and 8.5% task success rates on seen and unseen test splits.
Learning visual policies for building 3D shape categories
Apr 15, 2020

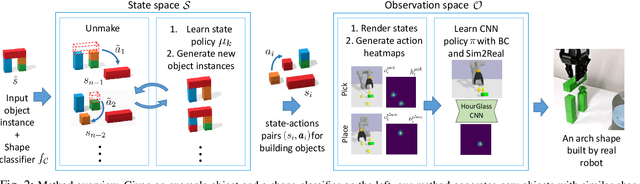
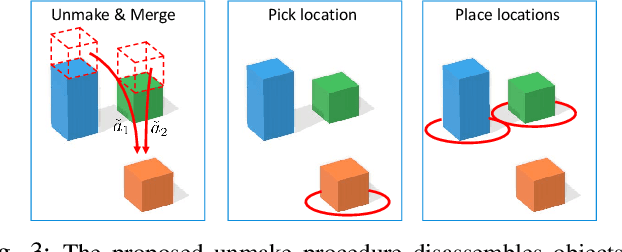
Manipulation and assembly tasks require non-trivial planning of actions depending on the environment and the final goal. Previous work in this domain often assembles particular instances of objects from known sets of primitives. In contrast, we here aim to handle varying sets of primitives and to construct different objects of the same shape category. Given a single object instance of a category, e.g. an arch, and a binary shape classifier, we learn a visual policy to assemble other instances of the same category. In particular, we propose a disassembly procedure and learn a state policy that discovers new object instances and their assembly plans in state space. We then render simulated states in the observation space and learn a heatmap representation to predict alternative actions from a given input image. To validate our approach, we first demonstrate its efficiency for building object categories in state space. We then show the success of our visual policies for building arches from different primitives. Moreover, we demonstrate (i) the reactive ability of our method to re-assemble objects using additional primitives and (ii) the robust performance of our policy for unseen primitives resembling building blocks used during training. Our visual assembly policies are trained with no real images and reach up to 95% success rate when evaluated on a real robot.
Combining learned skills and reinforcement learning for robotic manipulations
Aug 02, 2019

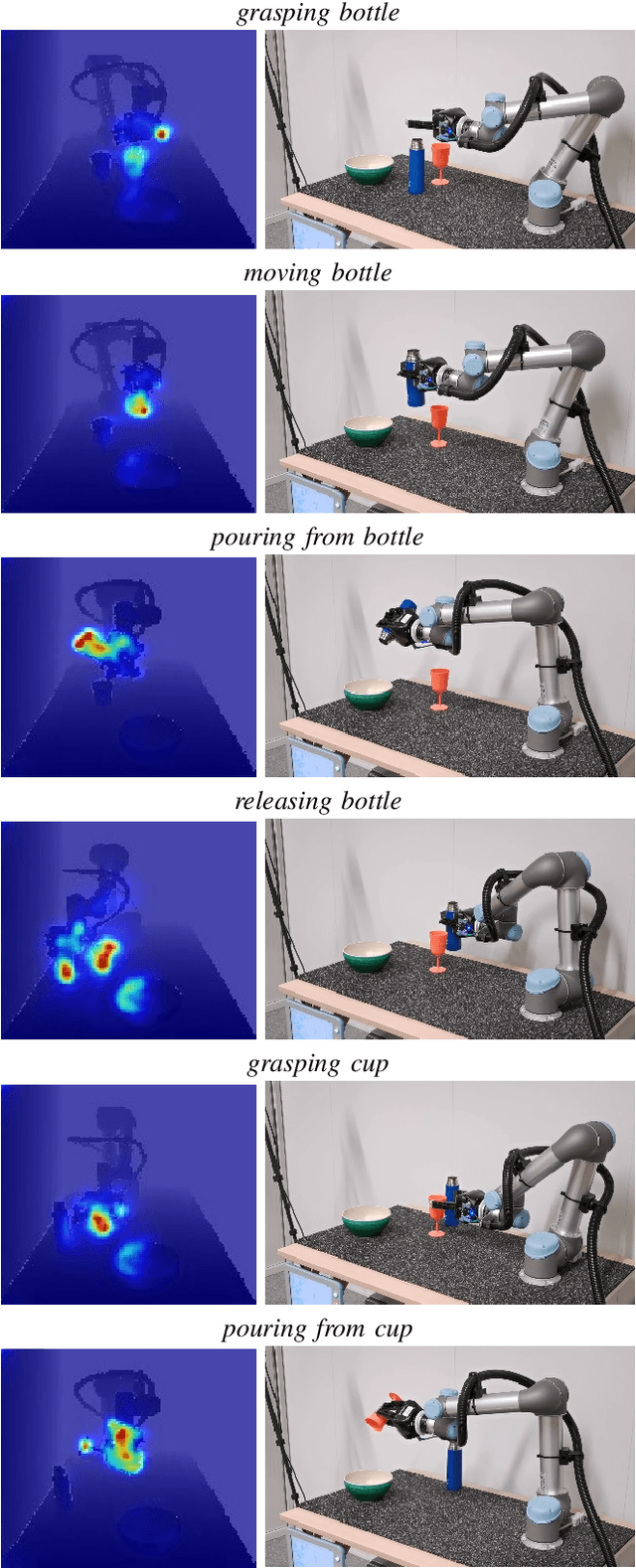

Manipulation tasks such as preparing a meal or assembling furniture remain highly challenging for robotics and vision. The supervised approach of imitation learning can handle short tasks but suffers from compounding errors and the need of many demonstrations for longer and more complex tasks. Reinforcement learning (RL) can find solutions beyond demonstrations but requires tedious and task-specific reward engineering for multi-step problems. In this work we address the difficulties of both methods and explore their combination. To this end, we propose a RL policies operating on pre-trained skills, that can learn composite manipulations using no intermediate rewards and no demonstrations of full tasks. We also propose an efficient training of basic skills from few synthetic demonstrated trajectories by exploring recent CNN architectures and data augmentation. We show successful learning of policies for composite manipulation tasks such as making a simple breakfast. Notably, our method achieves high success rates on a real robot, while using synthetic training data only.
Learning to Augment Synthetic Images for Sim2Real Policy Transfer
Mar 18, 2019
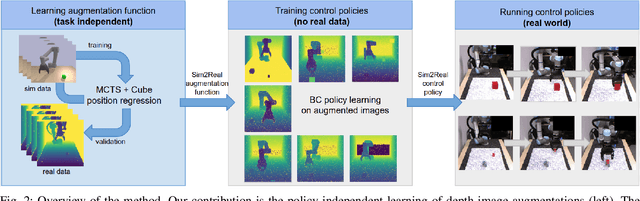
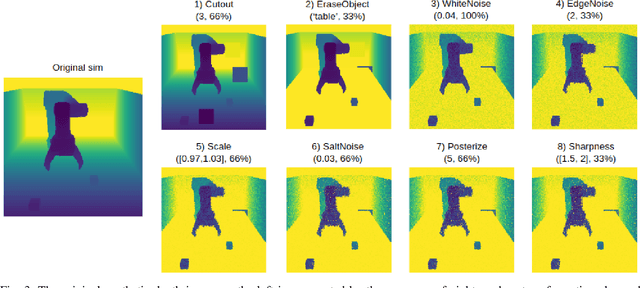

Vision and learning have made significant progress that could improve robotics policies for complex tasks and environments. Learning deep neural networks for image understanding, however, requires large amounts of domain-specific visual data. While collecting such data from real robots is possible, such an approach limits the scalability as learning policies typically requires thousands of trials. In this work we attempt to learn manipulation policies in simulated environments. Simulators enable scalability and provide access to the underlying world state during training. Policies learned in simulators, however, do not transfer well to real scenes given the domain gap between real and synthetic data. We follow recent work on domain randomization and augment synthetic images with sequences of random transformations. Our main contribution is to optimize the augmentation strategy for sim2real transfer and to enable domain-independent policy learning. We design an efficient search for depth image augmentations using object localization as a proxy task. Given the resulting sequence of random transformations, we use it to augment synthetic depth images during policy learning. Our augmentation strategy is policy-independent and enables policy learning with no real images. We demonstrate our approach to significantly improve accuracy on three manipulation tasks evaluated on a real robot.
Modulated Policy Hierarchies
Nov 30, 2018
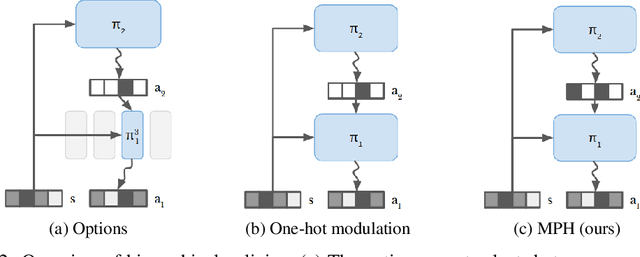
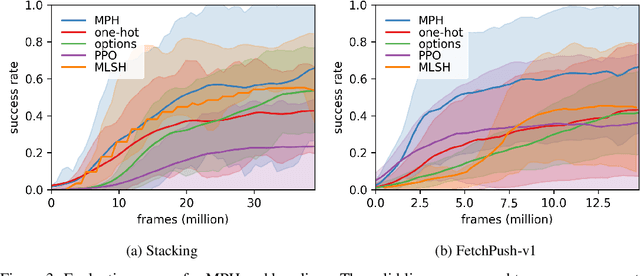

Solving tasks with sparse rewards is a main challenge in reinforcement learning. While hierarchical controllers are an intuitive approach to this problem, current methods often require manual reward shaping, alternating training phases, or manually defined sub tasks. We introduce modulated policy hierarchies (MPH), that can learn end-to-end to solve tasks from sparse rewards. To achieve this, we study different modulation signals and exploration for hierarchical controllers. Specifically, we find that communicating via bit-vectors is more efficient than selecting one out of multiple skills, as it enables mixing between them. To facilitate exploration, MPH uses its different time scales for temporally extended intrinsic motivation at each level of the hierarchy. We evaluate MPH on the robotics tasks of pushing and sparse block stacking, where it outperforms recent baselines.