 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOne Step Diffusion via Shortcut Models
Oct 16, 2024



Diffusion models and flow-matching models have enabled generating diverse and realistic images by learning to transfer noise to data. However, sampling from these models involves iterative denoising over many neural network passes, making generation slow and expensive. Previous approaches for speeding up sampling require complex training regimes, such as multiple training phases, multiple networks, or fragile scheduling. We introduce shortcut models, a family of generative models that use a single network and training phase to produce high-quality samples in a single or multiple sampling steps. Shortcut models condition the network not only on the current noise level but also on the desired step size, allowing the model to skip ahead in the generation process. Across a wide range of sampling step budgets, shortcut models consistently produce higher quality samples than previous approaches, such as consistency models and reflow. Compared to distillation, shortcut models reduce complexity to a single network and training phase and additionally allow varying step budgets at inference time.
Learning to Model the World with Language
Jul 31, 2023



To interact with humans in the world, agents need to understand the diverse types of language that people use, relate them to the visual world, and act based on them. While current agents learn to execute simple language instructions from task rewards, we aim to build agents that leverage diverse language that conveys general knowledge, describes the state of the world, provides interactive feedback, and more. Our key idea is that language helps agents predict the future: what will be observed, how the world will behave, and which situations will be rewarded. This perspective unifies language understanding with future prediction as a powerful self-supervised learning objective. We present Dynalang, an agent that learns a multimodal world model that predicts future text and image representations and learns to act from imagined model rollouts. Unlike traditional agents that use language only to predict actions, Dynalang acquires rich language understanding by using past language also to predict future language, video, and rewards. In addition to learning from online interaction in an environment, Dynalang can be pretrained on datasets of text, video, or both without actions or rewards. From using language hints in grid worlds to navigating photorealistic scans of homes, Dynalang utilizes diverse types of language to improve task performance, including environment descriptions, game rules, and instructions.
Video Prediction Models as Rewards for Reinforcement Learning
May 23, 2023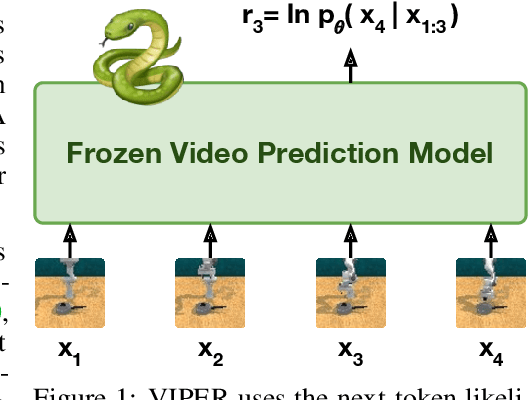


Specifying reward signals that allow agents to learn complex behaviors is a long-standing challenge in reinforcement learning. A promising approach is to extract preferences for behaviors from unlabeled videos, which are widely available on the internet. We present Video Prediction Rewards (VIPER), an algorithm that leverages pretrained video prediction models as action-free reward signals for reinforcement learning. Specifically, we first train an autoregressive transformer on expert videos and then use the video prediction likelihoods as reward signals for a reinforcement learning agent. VIPER enables expert-level control without programmatic task rewards across a wide range of DMC, Atari, and RLBench tasks. Moreover, generalization of the video prediction model allows us to derive rewards for an out-of-distribution environment where no expert data is available, enabling cross-embodiment generalization for tabletop manipulation. We see our work as starting point for scalable reward specification from unlabeled videos that will benefit from the rapid advances in generative modeling. Source code and datasets are available on the project website: https://escontrela.me
Mastering Diverse Domains through World Models
Jan 10, 2023



General intelligence requires solving tasks across many domains. Current reinforcement learning algorithms carry this potential but are held back by the resources and knowledge required to tune them for new tasks. We present DreamerV3, a general and scalable algorithm based on world models that outperforms previous approaches across a wide range of domains with fixed hyperparameters. These domains include continuous and discrete actions, visual and low-dimensional inputs, 2D and 3D worlds, different data budgets, reward frequencies, and reward scales. We observe favorable scaling properties of DreamerV3, with larger models directly translating to higher data-efficiency and final performance. Applied out of the box, DreamerV3 is the first algorithm to collect diamonds in Minecraft from scratch without human data or curricula, a long-standing challenge in artificial intelligence. Our general algorithm makes reinforcement learning broadly applicable and allows scaling to hard decision making problems.
Evaluating Long-Term Memory in 3D Mazes
Oct 24, 2022



Intelligent agents need to remember salient information to reason in partially-observed environments. For example, agents with a first-person view should remember the positions of relevant objects even if they go out of view. Similarly, to effectively navigate through rooms agents need to remember the floor plan of how rooms are connected. However, most benchmark tasks in reinforcement learning do not test long-term memory in agents, slowing down progress in this important research direction. In this paper, we introduce the Memory Maze, a 3D domain of randomized mazes specifically designed for evaluating long-term memory in agents. Unlike existing benchmarks, Memory Maze measures long-term memory separate from confounding agent abilities and requires the agent to localize itself by integrating information over time. With Memory Maze, we propose an online reinforcement learning benchmark, a diverse offline dataset, and an offline probing evaluation. Recording a human player establishes a strong baseline and verifies the need to build up and retain memories, which is reflected in their gradually increasing rewards within each episode. We find that current algorithms benefit from training with truncated backpropagation through time and succeed on small mazes, but fall short of human performance on the large mazes, leaving room for future algorithmic designs to be evaluated on the Memory Maze.
Temporally Consistent Video Transformer for Long-Term Video Prediction
Oct 05, 2022
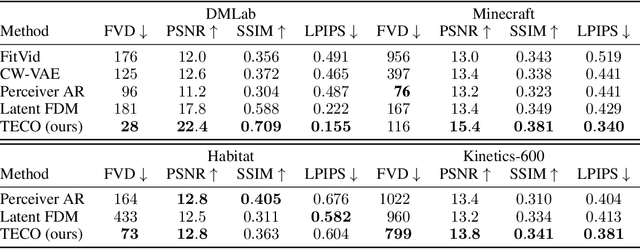
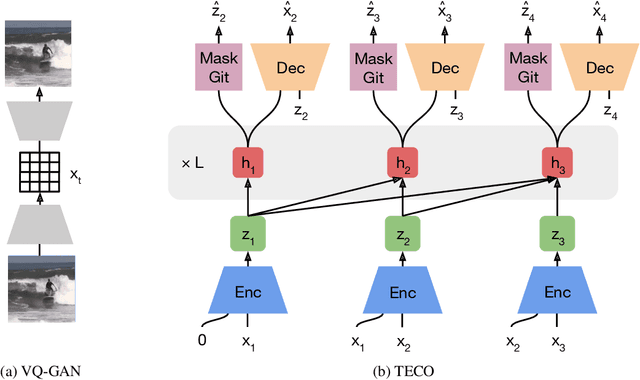
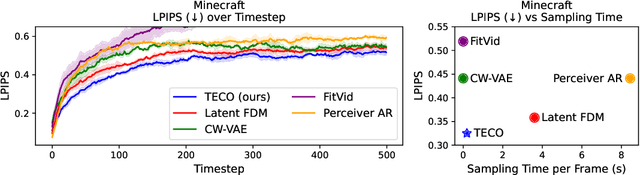
Generating long, temporally consistent video remains an open challenge in video generation. Primarily due to computational limitations, most prior methods limit themselves to training on a small subset of frames that are then extended to generate longer videos through a sliding window fashion. Although these techniques may produce sharp videos, they have difficulty retaining long-term temporal consistency due to their limited context length. In this work, we present Temporally Consistent Video Transformer (TECO), a vector-quantized latent dynamics video prediction model that learns compressed representations to efficiently condition on long videos of hundreds of frames during both training and generation. We use a MaskGit prior for dynamics prediction which enables both sharper and faster generations compared to prior work. Our experiments show that TECO outperforms SOTA baselines in a variety of video prediction benchmarks ranging from simple mazes in DMLab, large 3D worlds in Minecraft, and complex real-world videos from Kinetics-600. In addition, to better understand the capabilities of video prediction models in modeling temporal consistency, we introduce several challenging video prediction tasks consisting of agents randomly traversing 3D scenes of varying difficulty. This presents a challenging benchmark for video prediction in partially observable environments where a model must understand what parts of the scenes to re-create versus invent depending on its past observations or generations. Generated videos are available at https://wilson1yan.github.io/teco
Masked World Models for Visual Control
Jun 28, 2022
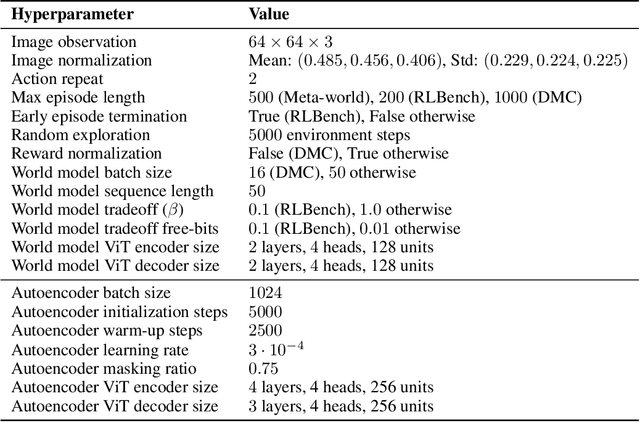


Visual model-based reinforcement learning (RL) has the potential to enable sample-efficient robot learning from visual observations. Yet the current approaches typically train a single model end-to-end for learning both visual representations and dynamics, making it difficult to accurately model the interaction between robots and small objects. In this work, we introduce a visual model-based RL framework that decouples visual representation learning and dynamics learning. Specifically, we train an autoencoder with convolutional layers and vision transformers (ViT) to reconstruct pixels given masked convolutional features, and learn a latent dynamics model that operates on the representations from the autoencoder. Moreover, to encode task-relevant information, we introduce an auxiliary reward prediction objective for the autoencoder. We continually update both autoencoder and dynamics model using online samples collected from environment interaction. We demonstrate that our decoupling approach achieves state-of-the-art performance on a variety of visual robotic tasks from Meta-world and RLBench, e.g., we achieve 81.7% success rate on 50 visual robotic manipulation tasks from Meta-world, while the baseline achieves 67.9%. Code is available on the project website: https://sites.google.com/view/mwm-rl.
DayDreamer: World Models for Physical Robot Learning
Jun 28, 2022
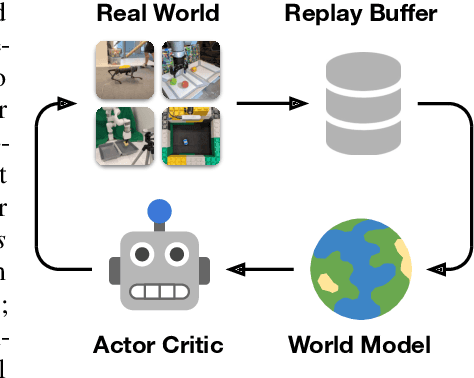
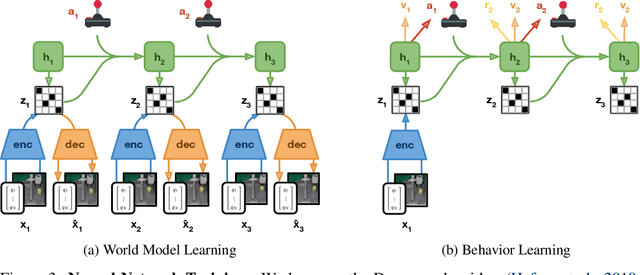

To solve tasks in complex environments, robots need to learn from experience. Deep reinforcement learning is a common approach to robot learning but requires a large amount of trial and error to learn, limiting its deployment in the physical world. As a consequence, many advances in robot learning rely on simulators. On the other hand, learning inside of simulators fails to capture the complexity of the real world, is prone to simulator inaccuracies, and the resulting behaviors do not adapt to changes in the world. The Dreamer algorithm has recently shown great promise for learning from small amounts of interaction by planning within a learned world model, outperforming pure reinforcement learning in video games. Learning a world model to predict the outcomes of potential actions enables planning in imagination, reducing the amount of trial and error needed in the real environment. However, it is unknown whether Dreamer can facilitate faster learning on physical robots. In this paper, we apply Dreamer to 4 robots to learn online and directly in the real world, without simulators. Dreamer trains a quadruped robot to roll off its back, stand up, and walk from scratch and without resets in only 1 hour. We then push the robot and find that Dreamer adapts within 10 minutes to withstand perturbations or quickly roll over and stand back up. On two different robotic arms, Dreamer learns to pick and place multiple objects directly from camera images and sparse rewards, approaching human performance. On a wheeled robot, Dreamer learns to navigate to a goal position purely from camera images, automatically resolving ambiguity about the robot orientation. Using the same hyperparameters across all experiments, we find that Dreamer is capable of online learning in the real world, establishing a strong baseline. We release our infrastructure for future applications of world models to robot learning.
Deep Hierarchical Planning from Pixels
Jun 08, 2022
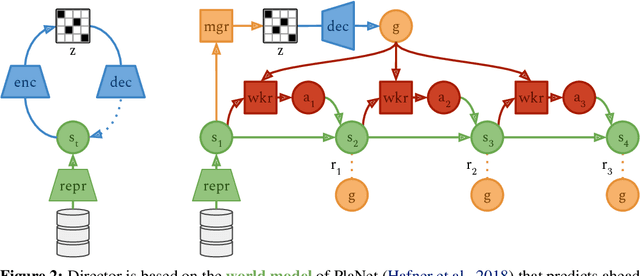

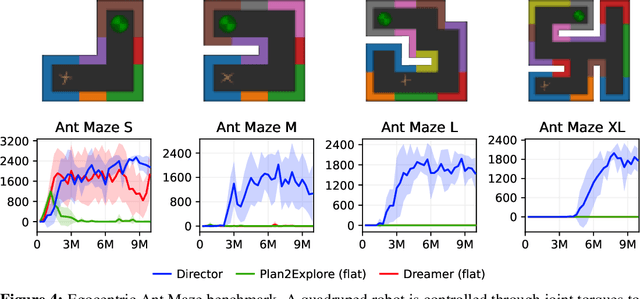
Intelligent agents need to select long sequences of actions to solve complex tasks. While humans easily break down tasks into subgoals and reach them through millions of muscle commands, current artificial intelligence is limited to tasks with horizons of a few hundred decisions, despite large compute budgets. Research on hierarchical reinforcement learning aims to overcome this limitation but has proven to be challenging, current methods rely on manually specified goal spaces or subtasks, and no general solution exists. We introduce Director, a practical method for learning hierarchical behaviors directly from pixels by planning inside the latent space of a learned world model. The high-level policy maximizes task and exploration rewards by selecting latent goals and the low-level policy learns to achieve the goals. Despite operating in latent space, the decisions are interpretable because the world model can decode goals into images for visualization. Director outperforms exploration methods on tasks with sparse rewards, including 3D maze traversal with a quadruped robot from an egocentric camera and proprioception, without access to the global position or top-down view that was used by prior work. Director also learns successful behaviors across a wide range of environments, including visual control, Atari games, and DMLab levels.
Information is Power: Intrinsic Control via Information Capture
Dec 07, 2021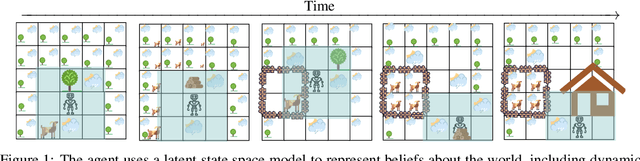


Humans and animals explore their environment and acquire useful skills even in the absence of clear goals, exhibiting intrinsic motivation. The study of intrinsic motivation in artificial agents is concerned with the following question: what is a good general-purpose objective for an agent? We study this question in dynamic partially-observed environments, and argue that a compact and general learning objective is to minimize the entropy of the agent's state visitation estimated using a latent state-space model. This objective induces an agent to both gather information about its environment, corresponding to reducing uncertainty, and to gain control over its environment, corresponding to reducing the unpredictability of future world states. We instantiate this approach as a deep reinforcement learning agent equipped with a deep variational Bayes filter. We find that our agent learns to discover, represent, and exercise control of dynamic objects in a variety of partially-observed environments sensed with visual observations without extrinsic reward.