 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComposer 2 Technical Report
Mar 25, 2026Composer 2 is a specialized model designed for agentic software engineering. The model demonstrates strong long-term planning and coding intelligence while maintaining the ability to efficiently solve problems for interactive use. The model is trained in two phases: first, continued pretraining to improve the model's knowledge and latent coding ability, followed by large-scale reinforcement learning to improve end-to-end coding performance through stronger reasoning, accurate multi-step execution, and coherence on long-horizon realistic coding problems. We develop infrastructure to support training in the same Cursor harness that is used by the deployed model, with equivalent tools and structure, and use environments that match real problems closely. To measure the ability of the model on increasingly difficult tasks, we introduce a benchmark derived from real software engineering problems in large codebases including our own. Composer 2 is a frontier-level coding model and demonstrates a process for training strong domain-specialized models. On our CursorBench evaluations the model achieves a major improvement in accuracy compared to previous Composer models (61.3). On public benchmarks the model scores 61.7 on Terminal-Bench and 73.7 on SWE-bench Multilingual in our harness, comparable to state-of-the-art systems.
Horizon Reduction Makes RL Scalable
Jun 08, 2025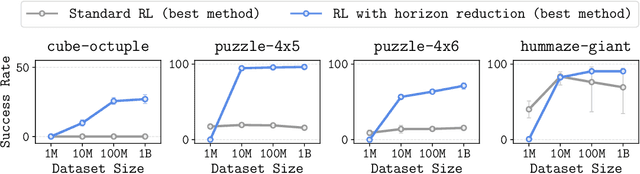
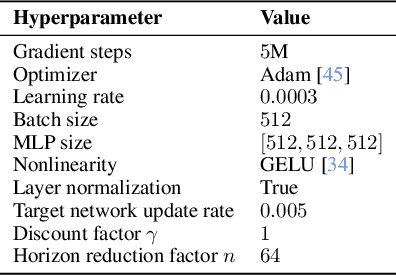

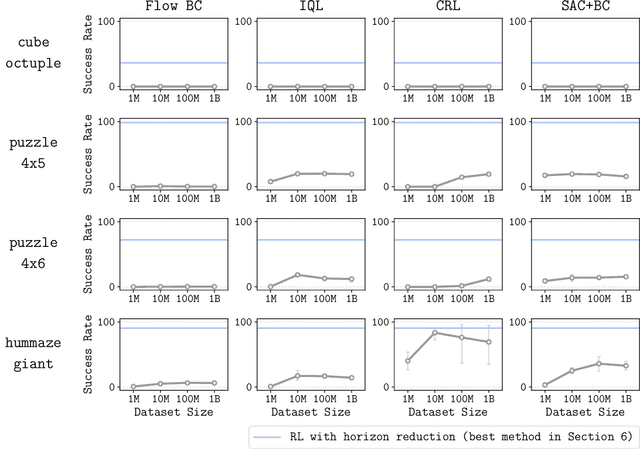
In this work, we study the scalability of offline reinforcement learning (RL) algorithms. In principle, a truly scalable offline RL algorithm should be able to solve any given problem, regardless of its complexity, given sufficient data, compute, and model capacity. We investigate if and how current offline RL algorithms match up to this promise on diverse, challenging, previously unsolved tasks, using datasets up to 1000x larger than typical offline RL datasets. We observe that despite scaling up data, many existing offline RL algorithms exhibit poor scaling behavior, saturating well below the maximum performance. We hypothesize that the horizon is the main cause behind the poor scaling of offline RL. We empirically verify this hypothesis through several analysis experiments, showing that long horizons indeed present a fundamental barrier to scaling up offline RL. We then show that various horizon reduction techniques substantially enhance scalability on challenging tasks. Based on our insights, we also introduce a minimal yet scalable method named SHARSA that effectively reduces the horizon. SHARSA achieves the best asymptotic performance and scaling behavior among our evaluation methods, showing that explicitly reducing the horizon unlocks the scalability of offline RL. Code: https://github.com/seohongpark/horizon-reduction
A Stable Whitening Optimizer for Efficient Neural Network Training
Jun 08, 2025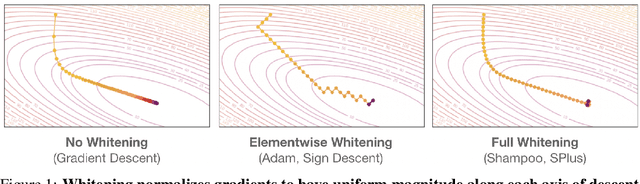



In this work, we take an experimentally grounded look at neural network optimization. Building on the Shampoo family of algorithms, we identify and alleviate three key issues, resulting in the proposed SPlus method. First, we find that naive Shampoo is prone to divergence when matrix-inverses are cached for long periods. We introduce an alternate bounded update combining a historical eigenbasis with instantaneous normalization, resulting in across-the-board stability and significantly lower computational requirements. Second, we adapt a shape-aware scaling to enable learning rate transfer across network width. Third, we find that high learning rates result in large parameter noise, and propose a simple iterate-averaging scheme which unblocks faster learning. To properly confirm these findings, we introduce a pointed Transformer training benchmark, considering three objectives (language modelling, image classification, and diffusion modelling) across different stages of training. On average, SPlus is able to reach the validation performance of Adam within 44% of the gradient steps and 62% of the wallclock time.
Diffusion Guidance Is a Controllable Policy Improvement Operator
May 29, 2025



At the core of reinforcement learning is the idea of learning beyond the performance in the data. However, scaling such systems has proven notoriously tricky. In contrast, techniques from generative modeling have proven remarkably scalable and are simple to train. In this work, we combine these strengths, by deriving a direct relation between policy improvement and guidance of diffusion models. The resulting framework, CFGRL, is trained with the simplicity of supervised learning, yet can further improve on the policies in the data. On offline RL tasks, we observe a reliable trend -- increased guidance weighting leads to increased performance. Of particular importance, CFGRL can operate without explicitly learning a value function, allowing us to generalize simple supervised methods (e.g., goal-conditioned behavioral cloning) to further prioritize optimality, gaining performance for "free" across the board.
OGBench: Benchmarking Offline Goal-Conditioned RL
Oct 26, 2024Offline goal-conditioned reinforcement learning (GCRL) is a major problem in reinforcement learning (RL) because it provides a simple, unsupervised, and domain-agnostic way to acquire diverse behaviors and representations from unlabeled data without rewards. Despite the importance of this setting, we lack a standard benchmark that can systematically evaluate the capabilities of offline GCRL algorithms. In this work, we propose OGBench, a new, high-quality benchmark for algorithms research in offline goal-conditioned RL. OGBench consists of 8 types of environments, 85 datasets, and reference implementations of 6 representative offline GCRL algorithms. We have designed these challenging and realistic environments and datasets to directly probe different capabilities of algorithms, such as stitching, long-horizon reasoning, and the ability to handle high-dimensional inputs and stochasticity. While representative algorithms may rank similarly on prior benchmarks, our experiments reveal stark strengths and weaknesses in these different capabilities, providing a strong foundation for building new algorithms. Project page: https://seohong.me/projects/ogbench
Leveraging Skills from Unlabeled Prior Data for Efficient Online Exploration
Oct 23, 2024



Unsupervised pretraining has been transformative in many supervised domains. However, applying such ideas to reinforcement learning (RL) presents a unique challenge in that fine-tuning does not involve mimicking task-specific data, but rather exploring and locating the solution through iterative self-improvement. In this work, we study how unlabeled prior trajectory data can be leveraged to learn efficient exploration strategies. While prior data can be used to pretrain a set of low-level skills, or as additional off-policy data for online RL, it has been unclear how to combine these ideas effectively for online exploration. Our method SUPE (Skills from Unlabeled Prior data for Exploration) demonstrates that a careful combination of these ideas compounds their benefits. Our method first extracts low-level skills using a variational autoencoder (VAE), and then pseudo-relabels unlabeled trajectories using an optimistic reward model, transforming prior data into high-level, task-relevant examples. Finally, SUPE uses these transformed examples as additional off-policy data for online RL to learn a high-level policy that composes pretrained low-level skills to explore efficiently. We empirically show that SUPE reliably outperforms prior strategies, successfully solving a suite of long-horizon, sparse-reward tasks. Code: https://github.com/rail-berkeley/supe.
Prioritized Generative Replay
Oct 23, 2024Sample-efficient online reinforcement learning often uses replay buffers to store experience for reuse when updating the value function. However, uniform replay is inefficient, since certain classes of transitions can be more relevant to learning. While prioritization of more useful samples is helpful, this strategy can also lead to overfitting, as useful samples are likely to be more rare. In this work, we instead propose a prioritized, parametric version of an agent's memory, using generative models to capture online experience. This paradigm enables (1) densification of past experience, with new generations that benefit from the generative model's generalization capacity and (2) guidance via a family of "relevance functions" that push these generations towards more useful parts of an agent's acquired history. We show this recipe can be instantiated using conditional diffusion models and simple relevance functions such as curiosity- or value-based metrics. Our approach consistently improves performance and sample efficiency in both state- and pixel-based domains. We expose the mechanisms underlying these gains, showing how guidance promotes diversity in our generated transitions and reduces overfitting. We also showcase how our approach can train policies with even higher update-to-data ratios than before, opening up avenues to better scale online RL agents.
One Step Diffusion via Shortcut Models
Oct 16, 2024



Diffusion models and flow-matching models have enabled generating diverse and realistic images by learning to transfer noise to data. However, sampling from these models involves iterative denoising over many neural network passes, making generation slow and expensive. Previous approaches for speeding up sampling require complex training regimes, such as multiple training phases, multiple networks, or fragile scheduling. We introduce shortcut models, a family of generative models that use a single network and training phase to produce high-quality samples in a single or multiple sampling steps. Shortcut models condition the network not only on the current noise level but also on the desired step size, allowing the model to skip ahead in the generation process. Across a wide range of sampling step budgets, shortcut models consistently produce higher quality samples than previous approaches, such as consistency models and reflow. Compared to distillation, shortcut models reduce complexity to a single network and training phase and additionally allow varying step budgets at inference time.
Is Value Learning Really the Main Bottleneck in Offline RL?
Jun 13, 2024While imitation learning requires access to high-quality data, offline reinforcement learning (RL) should, in principle, perform similarly or better with substantially lower data quality by using a value function. However, current results indicate that offline RL often performs worse than imitation learning, and it is often unclear what holds back the performance of offline RL. Motivated by this observation, we aim to understand the bottlenecks in current offline RL algorithms. While poor performance of offline RL is typically attributed to an imperfect value function, we ask: is the main bottleneck of offline RL indeed in learning the value function, or something else? To answer this question, we perform a systematic empirical study of (1) value learning, (2) policy extraction, and (3) policy generalization in offline RL problems, analyzing how these components affect performance. We make two surprising observations. First, we find that the choice of a policy extraction algorithm significantly affects the performance and scalability of offline RL, often more so than the value learning objective. For instance, we show that common value-weighted behavioral cloning objectives (e.g., AWR) do not fully leverage the learned value function, and switching to behavior-constrained policy gradient objectives (e.g., DDPG+BC) often leads to substantial improvements in performance and scalability. Second, we find that a big barrier to improving offline RL performance is often imperfect policy generalization on test-time states out of the support of the training data, rather than policy learning on in-distribution states. We then show that the use of suboptimal but high-coverage data or test-time policy training techniques can address this generalization issue in practice. Specifically, we propose two simple test-time policy improvement methods and show that these methods lead to better performance.
Unsupervised Zero-Shot Reinforcement Learning via Functional Reward Encodings
Feb 27, 2024



Can we pre-train a generalist agent from a large amount of unlabeled offline trajectories such that it can be immediately adapted to any new downstream tasks in a zero-shot manner? In this work, we present a functional reward encoding (FRE) as a general, scalable solution to this zero-shot RL problem. Our main idea is to learn functional representations of any arbitrary tasks by encoding their state-reward samples using a transformer-based variational auto-encoder. This functional encoding not only enables the pre-training of an agent from a wide diversity of general unsupervised reward functions, but also provides a way to solve any new downstream tasks in a zero-shot manner, given a small number of reward-annotated samples. We empirically show that FRE agents trained on diverse random unsupervised reward functions can generalize to solve novel tasks in a range of simulated robotic benchmarks, often outperforming previous zero-shot RL and offline RL methods. Code for this project is provided at: https://github.com/kvfrans/fre