 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeElasticTok: Adaptive Tokenization for Image and Video
Oct 10, 2024



Efficient video tokenization remains a key bottleneck in learning general purpose vision models that are capable of processing long video sequences. Prevailing approaches are restricted to encoding videos to a fixed number of tokens, where too few tokens will result in overly lossy encodings, and too many tokens will result in prohibitively long sequence lengths. In this work, we introduce ElasticTok, a method that conditions on prior frames to adaptively encode a frame into a variable number of tokens. To enable this in a computationally scalable way, we propose a masking technique that drops a random number of tokens at the end of each frames's token encoding. During inference, ElasticTok can dynamically allocate tokens when needed -- more complex data can leverage more tokens, while simpler data only needs a few tokens. Our empirical evaluations on images and video demonstrate the effectiveness of our approach in efficient token usage, paving the way for future development of more powerful multimodal models, world models, and agents.
World Model on Million-Length Video And Language With RingAttention
Feb 13, 2024
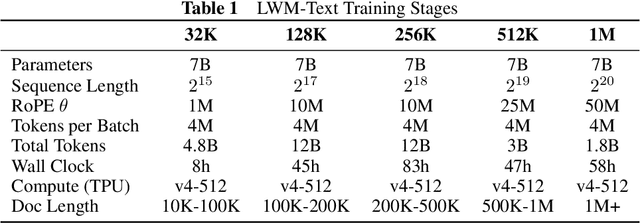

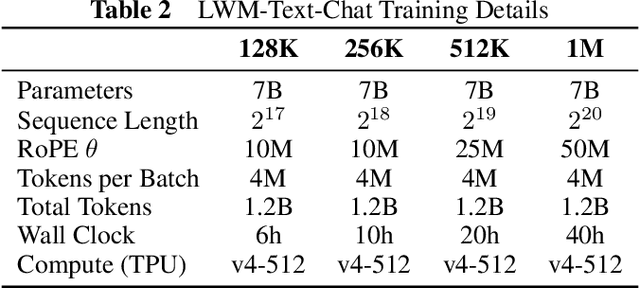
Current language models fall short in understanding aspects of the world not easily described in words, and struggle with complex, long-form tasks. Video sequences offer valuable temporal information absent in language and static images, making them attractive for joint modeling with language. Such models could develop a understanding of both human textual knowledge and the physical world, enabling broader AI capabilities for assisting humans. However, learning from millions of tokens of video and language sequences poses challenges due to memory constraints, computational complexity, and limited datasets. To address these challenges, we curate a large dataset of diverse videos and books, utilize the RingAttention technique to scalably train on long sequences, and gradually increase context size from 4K to 1M tokens. This paper makes the following contributions: (a) Largest context size neural network: We train one of the largest context size transformers on long video and language sequences, setting new benchmarks in difficult retrieval tasks and long video understanding. (b) Solutions for overcoming vision-language training challenges, including using masked sequence packing for mixing different sequence lengths, loss weighting to balance language and vision, and model-generated QA dataset for long sequence chat. (c) A highly-optimized implementation with RingAttention, masked sequence packing, and other key features for training on millions-length multimodal sequences. (d) Fully open-sourced a family of 7B parameter models capable of processing long text documents (LWM-Text, LWM-Text-Chat) and videos (LWM, LWM-Chat) of over 1M tokens. This work paves the way for training on massive datasets of long video and language to develop understanding of both human knowledge and the multimodal world, and broader capabilities.
Motion-Conditioned Image Animation for Video Editing
Nov 30, 2023



We introduce MoCA, a Motion-Conditioned Image Animation approach for video editing. It leverages a simple decomposition of the video editing problem into image editing followed by motion-conditioned image animation. Furthermore, given the lack of robust evaluation datasets for video editing, we introduce a new benchmark that measures edit capability across a wide variety of tasks, such as object replacement, background changes, style changes, and motion edits. We present a comprehensive human evaluation of the latest video editing methods along with MoCA, on our proposed benchmark. MoCA establishes a new state-of-the-art, demonstrating greater human preference win-rate, and outperforming notable recent approaches including Dreamix (63%), MasaCtrl (75%), and Tune-A-Video (72%), with especially significant improvements for motion edits.
ALP: Action-Aware Embodied Learning for Perception
Jun 16, 2023



Current methods in training and benchmarking vision models exhibit an over-reliance on passive, curated datasets. Although models trained on these datasets have shown strong performance in a wide variety of tasks such as classification, detection, and segmentation, they fundamentally are unable to generalize to an ever-evolving world due to constant out-of-distribution shifts of input data. Therefore, instead of training on fixed datasets, can we approach learning in a more human-centric and adaptive manner? In this paper, we introduce \textbf{A}ction-aware Embodied \textbf{L}earning for \textbf{P}erception (ALP), an embodied learning framework that incorporates action information into representation learning through a combination of optimizing policy gradients through reinforcement learning and inverse dynamics prediction objectives. Our method actively explores complex 3D environments to both learn generalizable task-agnostic representations as well as collect downstream training data. We show that ALP outperforms existing baselines in object detection and semantic segmentation. In addition, we show that by training on actively collected data more relevant to the environment and task, our method generalizes more robustly to downstream tasks compared to models pre-trained on fixed datasets such as ImageNet.
Video Prediction Models as Rewards for Reinforcement Learning
May 23, 2023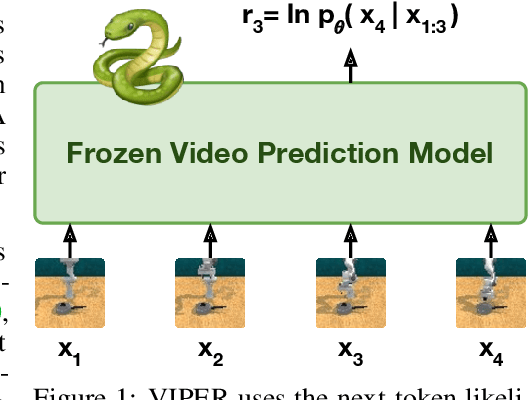

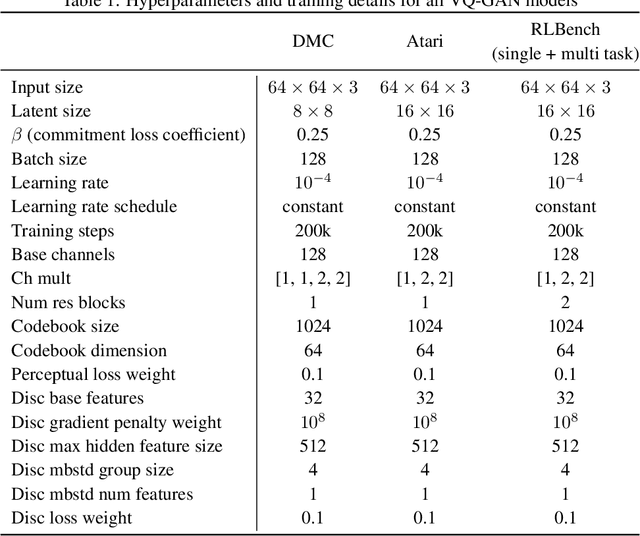

Specifying reward signals that allow agents to learn complex behaviors is a long-standing challenge in reinforcement learning. A promising approach is to extract preferences for behaviors from unlabeled videos, which are widely available on the internet. We present Video Prediction Rewards (VIPER), an algorithm that leverages pretrained video prediction models as action-free reward signals for reinforcement learning. Specifically, we first train an autoregressive transformer on expert videos and then use the video prediction likelihoods as reward signals for a reinforcement learning agent. VIPER enables expert-level control without programmatic task rewards across a wide range of DMC, Atari, and RLBench tasks. Moreover, generalization of the video prediction model allows us to derive rewards for an out-of-distribution environment where no expert data is available, enabling cross-embodiment generalization for tabletop manipulation. We see our work as starting point for scalable reward specification from unlabeled videos that will benefit from the rapid advances in generative modeling. Source code and datasets are available on the project website: https://escontrela.me
Language Quantized AutoEncoders: Towards Unsupervised Text-Image Alignment
Feb 03, 2023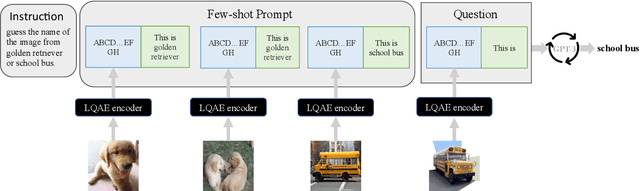
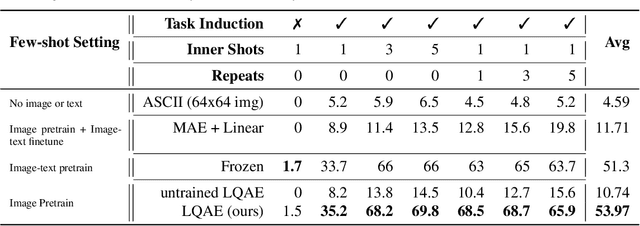
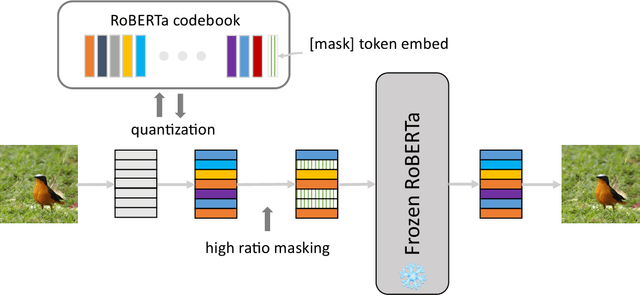
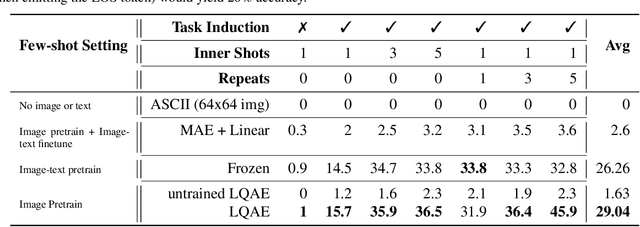
Recent progress in scaling up large language models has shown impressive capabilities in performing few-shot learning across a wide range of text-based tasks. However, a key limitation is that these language models fundamentally lack visual perception - a crucial attribute needed to extend these models to be able to interact with the real world and solve vision tasks, such as in visual-question answering and robotics. Prior works have largely connected image to text through pretraining and/or fine-tuning on curated image-text datasets, which can be a costly and expensive process. In order to resolve this limitation, we propose a simple yet effective approach called Language-Quantized AutoEncoder (LQAE), a modification of VQ-VAE that learns to align text-image data in an unsupervised manner by leveraging pretrained language models (e.g., BERT, RoBERTa). Our main idea is to encode image as sequences of text tokens by directly quantizing image embeddings using a pretrained language codebook. We then apply random masking followed by a BERT model, and have the decoder reconstruct the original image from BERT predicted text token embeddings. By doing so, LQAE learns to represent similar images with similar clusters of text tokens, thereby aligning these two modalities without the use of aligned text-image pairs. This enables few-shot image classification with large language models (e.g., GPT-3) as well as linear classification of images based on BERT text features. To the best of our knowledge, our work is the first work that uses unaligned images for multimodal tasks by leveraging the power of pretrained language models.
Temporally Consistent Video Transformer for Long-Term Video Prediction
Oct 05, 2022
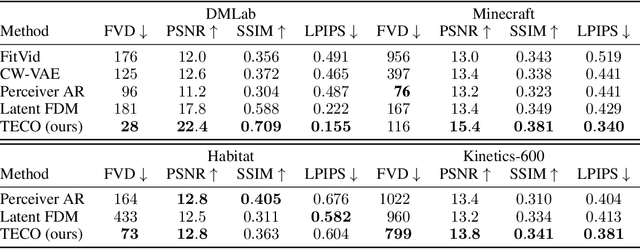
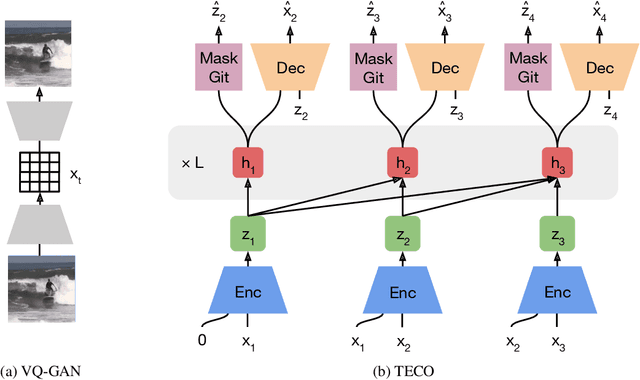
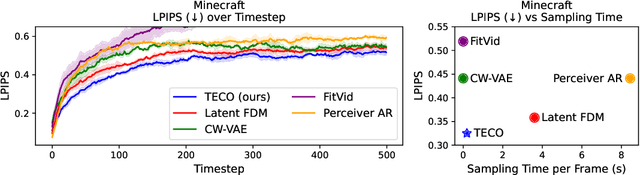
Generating long, temporally consistent video remains an open challenge in video generation. Primarily due to computational limitations, most prior methods limit themselves to training on a small subset of frames that are then extended to generate longer videos through a sliding window fashion. Although these techniques may produce sharp videos, they have difficulty retaining long-term temporal consistency due to their limited context length. In this work, we present Temporally Consistent Video Transformer (TECO), a vector-quantized latent dynamics video prediction model that learns compressed representations to efficiently condition on long videos of hundreds of frames during both training and generation. We use a MaskGit prior for dynamics prediction which enables both sharper and faster generations compared to prior work. Our experiments show that TECO outperforms SOTA baselines in a variety of video prediction benchmarks ranging from simple mazes in DMLab, large 3D worlds in Minecraft, and complex real-world videos from Kinetics-600. In addition, to better understand the capabilities of video prediction models in modeling temporal consistency, we introduce several challenging video prediction tasks consisting of agents randomly traversing 3D scenes of varying difficulty. This presents a challenging benchmark for video prediction in partially observable environments where a model must understand what parts of the scenes to re-create versus invent depending on its past observations or generations. Generated videos are available at https://wilson1yan.github.io/teco
Patch-based Object-centric Transformers for Efficient Video Generation
Jun 19, 2022
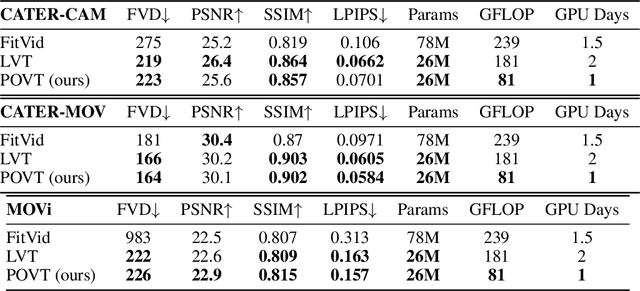
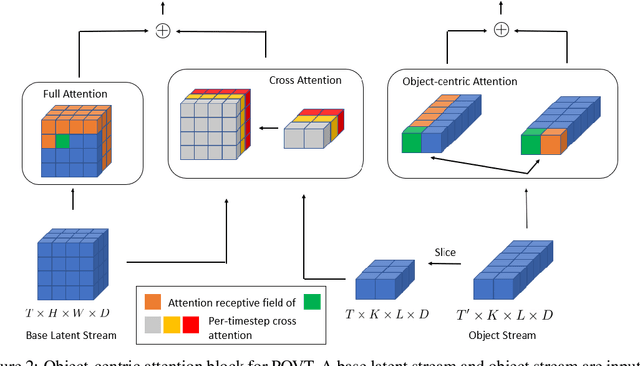
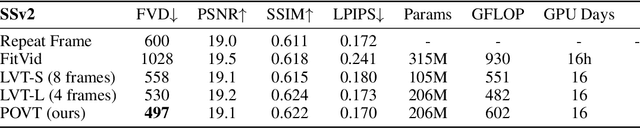
In this work, we present Patch-based Object-centric Video Transformer (POVT), a novel region-based video generation architecture that leverages object-centric information to efficiently model temporal dynamics in videos. We build upon prior work in video prediction via an autoregressive transformer over the discrete latent space of compressed videos, with an added modification to model object-centric information via bounding boxes. Due to better compressibility of object-centric representations, we can improve training efficiency by allowing the model to only access object information for longer horizon temporal information. When evaluated on various difficult object-centric datasets, our method achieves better or equal performance to other video generation models, while remaining computationally more efficient and scalable. In addition, we show that our method is able to perform object-centric controllability through bounding box manipulation, which may aid downstream tasks such as video editing, or visual planning. Samples are available at https://sites.google.com/view/povt-public
VideoGPT: Video Generation using VQ-VAE and Transformers
Apr 20, 2021

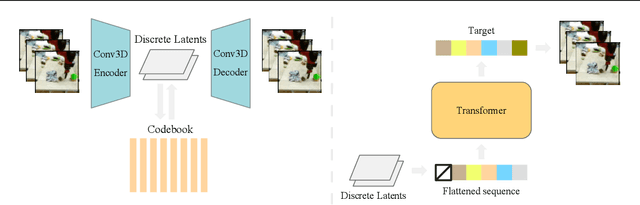
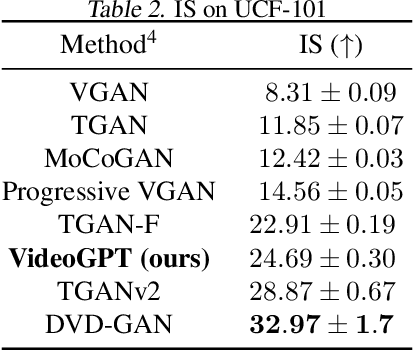
We present VideoGPT: a conceptually simple architecture for scaling likelihood based generative modeling to natural videos. VideoGPT uses VQ-VAE that learns downsampled discrete latent representations of a raw video by employing 3D convolutions and axial self-attention. A simple GPT-like architecture is then used to autoregressively model the discrete latents using spatio-temporal position encodings. Despite the simplicity in formulation and ease of training, our architecture is able to generate samples competitive with state-of-the-art GAN models for video generation on the BAIR Robot dataset, and generate high fidelity natural images from UCF-101 and Tumbler GIF Dataset (TGIF). We hope our proposed architecture serves as a reproducible reference for a minimalistic implementation of transformer based video generation models. Samples and code are available at https://wilson1yan.github.io/videogpt/index.html
Learning Predictive Representations for Deformable Objects Using Contrastive Estimation
Mar 11, 2020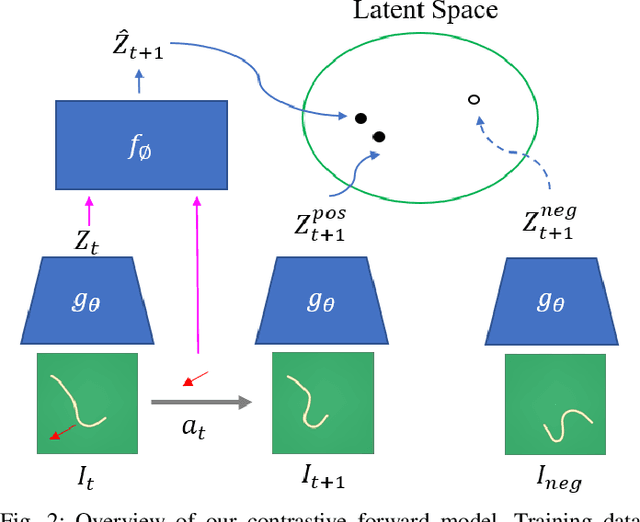

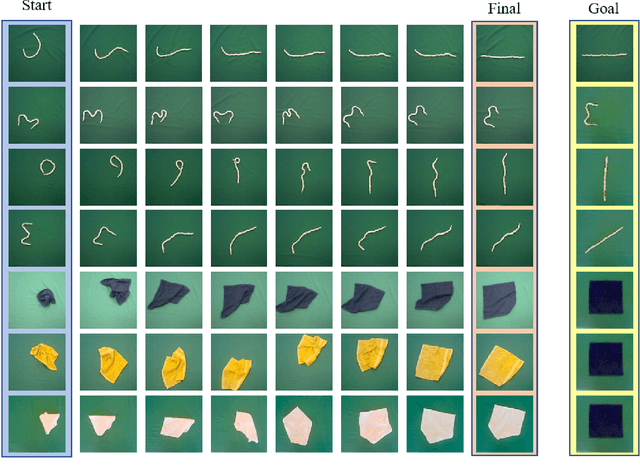

Using visual model-based learning for deformable object manipulation is challenging due to difficulties in learning plannable visual representations along with complex dynamic models. In this work, we propose a new learning framework that jointly optimizes both the visual representation model and the dynamics model using contrastive estimation. Using simulation data collected by randomly perturbing deformable objects on a table, we learn latent dynamics models for these objects in an offline fashion. Then, using the learned models, we use simple model-based planning to solve challenging deformable object manipulation tasks such as spreading ropes and cloths. Experimentally, we show substantial improvements in performance over standard model-based learning techniques across our rope and cloth manipulation suite. Finally, we transfer our visual manipulation policies trained on data purely collected in simulation to a real PR2 robot through domain randomization.