 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
A Systematic Literature Review of Retrieval-Augmented Generation: Techniques, Metrics, and Challenges
Aug 08, 2025This systematic review of the research literature on retrieval-augmented generation (RAG) provides a focused analysis of the most highly cited studies published between 2020 and May 2025. A total of 128 articles met our inclusion criteria. The records were retrieved from ACM Digital Library, IEEE Xplore, Scopus, ScienceDirect, and the Digital Bibliography and Library Project (DBLP). RAG couples a neural retriever with a generative language model, grounding output in up-to-date, non-parametric memory while retaining the semantic generalisation stored in model weights. Guided by the PRISMA 2020 framework, we (i) specify explicit inclusion and exclusion criteria based on citation count and research questions, (ii) catalogue datasets, architectures, and evaluation practices, and (iii) synthesise empirical evidence on the effectiveness and limitations of RAG. To mitigate citation-lag bias, we applied a lower citation-count threshold to papers published in 2025 so that emerging breakthroughs with naturally fewer citations were still captured. This review clarifies the current research landscape, highlights methodological gaps, and charts priority directions for future research.
Flowing from Words to Pixels: A Framework for Cross-Modality Evolution
Dec 19, 2024



Diffusion models, and their generalization, flow matching, have had a remarkable impact on the field of media generation. Here, the conventional approach is to learn the complex mapping from a simple source distribution of Gaussian noise to the target media distribution. For cross-modal tasks such as text-to-image generation, this same mapping from noise to image is learnt whilst including a conditioning mechanism in the model. One key and thus far relatively unexplored feature of flow matching is that, unlike Diffusion models, they are not constrained for the source distribution to be noise. Hence, in this paper, we propose a paradigm shift, and ask the question of whether we can instead train flow matching models to learn a direct mapping from the distribution of one modality to the distribution of another, thus obviating the need for both the noise distribution and conditioning mechanism. We present a general and simple framework, CrossFlow, for cross-modal flow matching. We show the importance of applying Variational Encoders to the input data, and introduce a method to enable Classifier-free guidance. Surprisingly, for text-to-image, CrossFlow with a vanilla transformer without cross attention slightly outperforms standard flow matching, and we show that it scales better with training steps and model size, while also allowing for interesting latent arithmetic which results in semantically meaningful edits in the output space. To demonstrate the generalizability of our approach, we also show that CrossFlow is on par with or outperforms the state-of-the-art for various cross-modal / intra-modal mapping tasks, viz. image captioning, depth estimation, and image super-resolution. We hope this paper contributes to accelerating progress in cross-modal media generation.
Movie Gen: A Cast of Media Foundation Models
Oct 17, 2024



We present Movie Gen, a cast of foundation models that generates high-quality, 1080p HD videos with different aspect ratios and synchronized audio. We also show additional capabilities such as precise instruction-based video editing and generation of personalized videos based on a user's image. Our models set a new state-of-the-art on multiple tasks: text-to-video synthesis, video personalization, video editing, video-to-audio generation, and text-to-audio generation. Our largest video generation model is a 30B parameter transformer trained with a maximum context length of 73K video tokens, corresponding to a generated video of 16 seconds at 16 frames-per-second. We show multiple technical innovations and simplifications on the architecture, latent spaces, training objectives and recipes, data curation, evaluation protocols, parallelization techniques, and inference optimizations that allow us to reap the benefits of scaling pre-training data, model size, and training compute for training large scale media generation models. We hope this paper helps the research community to accelerate progress and innovation in media generation models. All videos from this paper are available at https://go.fb.me/MovieGenResearchVideos.
The VoxCeleb Speaker Recognition Challenge: A Retrospective
Aug 27, 2024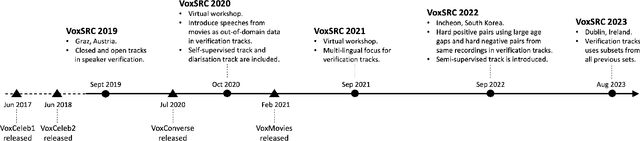
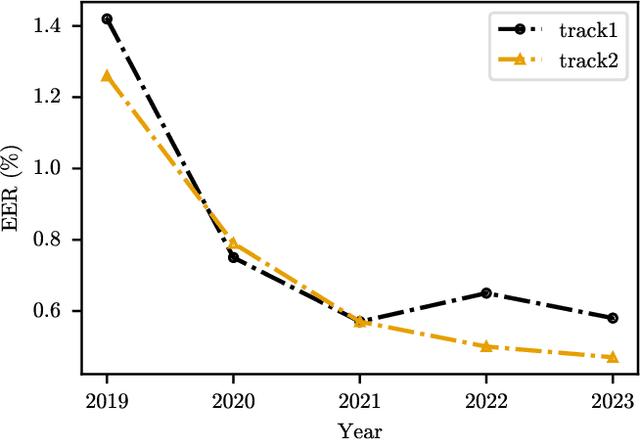
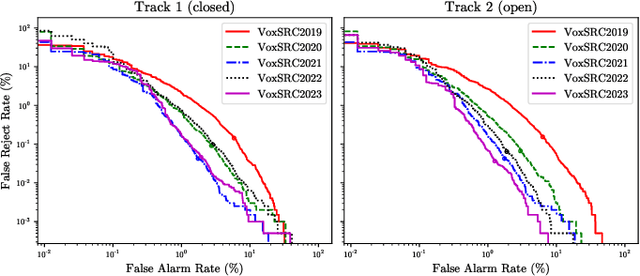
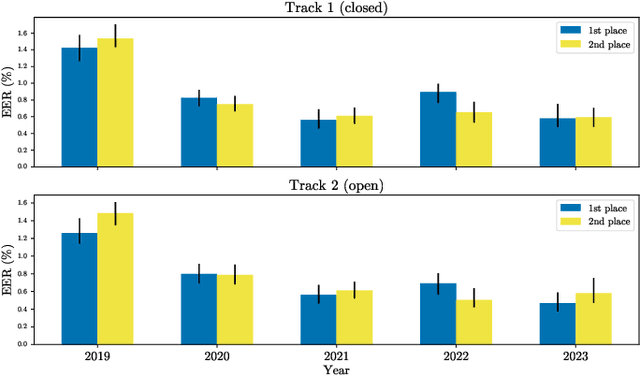
The VoxCeleb Speaker Recognition Challenges (VoxSRC) were a series of challenges and workshops that ran annually from 2019 to 2023. The challenges primarily evaluated the tasks of speaker recognition and diarisation under various settings including: closed and open training data; as well as supervised, self-supervised, and semi-supervised training for domain adaptation. The challenges also provided publicly available training and evaluation datasets for each task and setting, with new test sets released each year. In this paper, we provide a review of these challenges that covers: what they explored; the methods developed by the challenge participants and how these evolved; and also the current state of the field for speaker verification and diarisation. We chart the progress in performance over the five installments of the challenge on a common evaluation dataset and provide a detailed analysis of how each year's special focus affected participants' performance. This paper is aimed both at researchers who want an overview of the speaker recognition and diarisation field, and also at challenge organisers who want to benefit from the successes and avoid the mistakes of the VoxSRC challenges. We end with a discussion of the current strengths of the field and open challenges. Project page : https://mm.kaist.ac.kr/datasets/voxceleb/voxsrc/workshop.html
Generation, Distillation and Evaluation of Motivational Interviewing-Style Reflections with a Foundational Language Model
Feb 01, 2024



Large Foundational Language Models are capable of performing many tasks at a high level but are difficult to deploy in many applications because of their size and proprietary ownership. Many will be motivated to distill specific capabilities of foundational models into smaller models that can be owned and controlled. In the development of a therapeutic chatbot, we wish to distill a capability known as reflective listening, in which a therapist produces reflections of client speech. These reflections either restate what a client has said, or connect what was said to a relevant observation, idea or guess that encourages and guides the client to continue contemplation. In this paper, we present a method for distilling the generation of reflections from a Foundational Language Model (GPT-4) into smaller models. We first show that GPT-4, using zero-shot prompting, can generate reflections at near 100% success rate, superior to all previous methods. Using reflections generated by GPT-4, we fine-tune different sizes of the GPT-2 family. The GPT-2-small model achieves 83% success on a hold-out test set and the GPT-2 XL achieves 90% success. We also show that GPT-4 can help in the labor-intensive task of evaluating the quality of the distilled models, using it as a zero-shot classifier. Using triple-human review as a guide, the classifier achieves a Cohen-Kappa of 0.66, a substantial inter-rater reliability figure.
Motion-Conditioned Image Animation for Video Editing
Nov 30, 2023



We introduce MoCA, a Motion-Conditioned Image Animation approach for video editing. It leverages a simple decomposition of the video editing problem into image editing followed by motion-conditioned image animation. Furthermore, given the lack of robust evaluation datasets for video editing, we introduce a new benchmark that measures edit capability across a wide variety of tasks, such as object replacement, background changes, style changes, and motion edits. We present a comprehensive human evaluation of the latest video editing methods along with MoCA, on our proposed benchmark. MoCA establishes a new state-of-the-art, demonstrating greater human preference win-rate, and outperforming notable recent approaches including Dreamix (63%), MasaCtrl (75%), and Tune-A-Video (72%), with especially significant improvements for motion edits.
Emu Video: Factorizing Text-to-Video Generation by Explicit Image Conditioning
Nov 17, 2023We present Emu Video, a text-to-video generation model that factorizes the generation into two steps: first generating an image conditioned on the text, and then generating a video conditioned on the text and the generated image. We identify critical design decisions--adjusted noise schedules for diffusion, and multi-stage training--that enable us to directly generate high quality and high resolution videos, without requiring a deep cascade of models as in prior work. In human evaluations, our generated videos are strongly preferred in quality compared to all prior work--81% vs. Google's Imagen Video, 90% vs. Nvidia's PYOCO, and 96% vs. Meta's Make-A-Video. Our model outperforms commercial solutions such as RunwayML's Gen2 and Pika Labs. Finally, our factorizing approach naturally lends itself to animating images based on a user's text prompt, where our generations are preferred 96% over prior work.
Causal Video Summarizer for Video Exploration
Jul 04, 2023Recently, video summarization has been proposed as a method to help video exploration. However, traditional video summarization models only generate a fixed video summary which is usually independent of user-specific needs and hence limits the effectiveness of video exploration. Multi-modal video summarization is one of the approaches utilized to address this issue. Multi-modal video summarization has a video input and a text-based query input. Hence, effective modeling of the interaction between a video input and text-based query is essential to multi-modal video summarization. In this work, a new causality-based method named Causal Video Summarizer (CVS) is proposed to effectively capture the interactive information between the video and query to tackle the task of multi-modal video summarization. The proposed method consists of a probabilistic encoder and a probabilistic decoder. Based on the evaluation of the existing multi-modal video summarization dataset, experimental results show that the proposed approach is effective with the increase of +5.4% in accuracy and +4.92% increase of F 1- score, compared with the state-of-the-art method.
VoxSRC 2022: The Fourth VoxCeleb Speaker Recognition Challenge
Mar 06, 2023This paper summarises the findings from the VoxCeleb Speaker Recognition Challenge 2022 (VoxSRC-22), which was held in conjunction with INTERSPEECH 2022. The goal of this challenge was to evaluate how well state-of-the-art speaker recognition systems can diarise and recognise speakers from speech obtained "in the wild". The challenge consisted of: (i) the provision of publicly available speaker recognition and diarisation data from YouTube videos together with ground truth annotation and standardised evaluation software; and (ii) a public challenge and hybrid workshop held at INTERSPEECH 2022. We describe the four tracks of our challenge along with the baselines, methods, and results. We conclude with a discussion on the new domain-transfer focus of VoxSRC-22, and on the progression of the challenge from the previous three editions.