 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIn search of strong embedding extractors for speaker diarisation
Paper and Code
Oct 26, 2022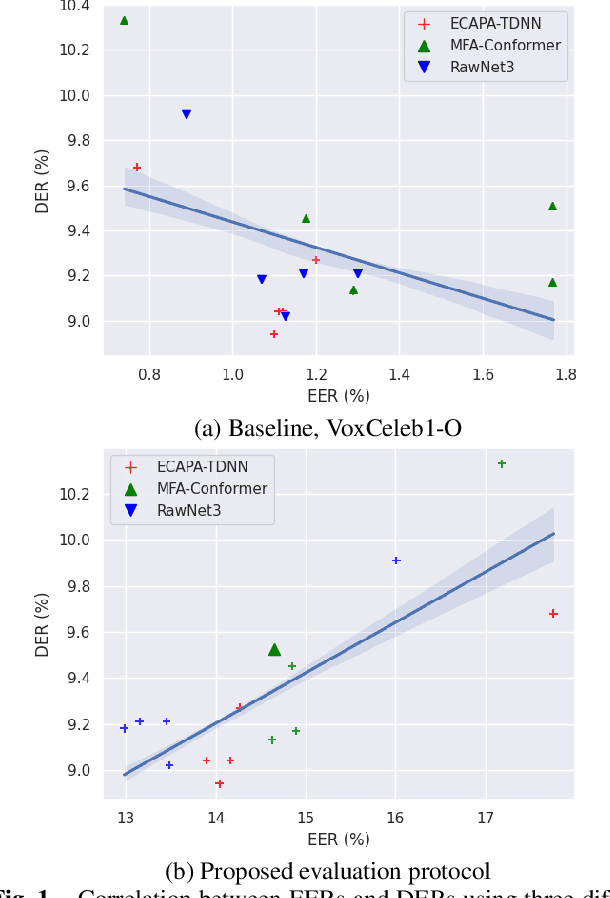
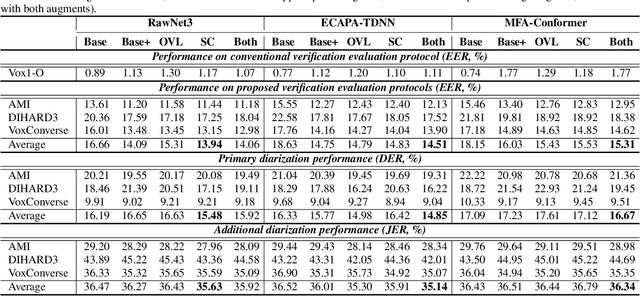
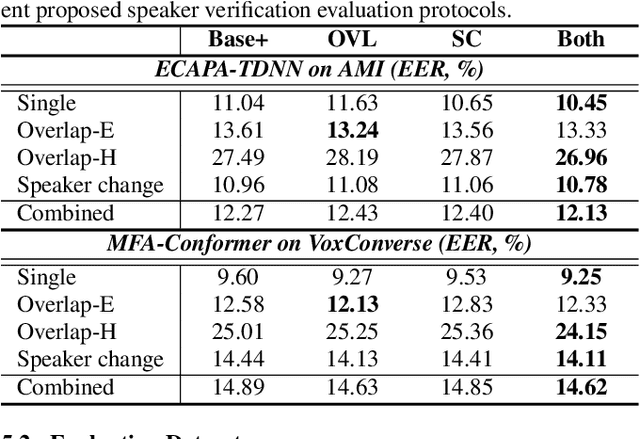
Speaker embedding extractors (EEs), which map input audio to a speaker discriminant latent space, are of paramount importance in speaker diarisation. However, there are several challenges when adopting EEs for diarisation, from which we tackle two key problems. First, the evaluation is not straightforward because the features required for better performance differ between speaker verification and diarisation. We show that better performance on widely adopted speaker verification evaluation protocols does not lead to better diarisation performance. Second, embedding extractors have not seen utterances in which multiple speakers exist. These inputs are inevitably present in speaker diarisation because of overlapped speech and speaker changes; they degrade the performance. To mitigate the first problem, we generate speaker verification evaluation protocols that mimic the diarisation scenario better. We propose two data augmentation techniques to alleviate the second problem, making embedding extractors aware of overlapped speech or speaker change input. One technique generates overlapped speech segments, and the other generates segments where two speakers utter sequentially. Extensive experimental results using three state-of-the-art speaker embedding extractors demonstrate that both proposed approaches are effective.