 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpectral-Progressive Thought Flow for Lightweight Multimodal Reasoning
Jun 01, 2026Multimodal spatial reasoning often relies on long chains of intermediate textual and visual thoughts, where accumulating visual tokens and dense cross-modal attention incur substantial computation and memory overhead. To address this challenge, we propose Spectral-Progressive Thought Flow (SpecFlow), a novel lightweight multimodal spatial reasoning framework that represents intermediate visual thoughts in a fixed-size discrete cosine space. By exploiting strong energy compaction, SpecFlow preserves global layout and relational structure while introducing high-frequency details only when increased spatial precision is required. To align visual state evolution with linguistic intent, classifier-free guidance enables autoregressive textual thoughts to steer flow-based updates of the visual workspace/state without expanding the context. As a result, SpecFlow maintains a bounded visual workspace whose updates depend only on the current visual state and accumulated textual trace, enabling long-horizon inference with stable latency and memory usage independent of reasoning depth. Empirical results show that SpecFlow achieves competitive or superior reasoning performance while reducing computation and KV cache costs by up to 2.1 times.
A-MAR: Agent-based Multimodal Art Retrieval for Fine-Grained Artwork Understanding
Apr 21, 2026Understanding artworks requires multi-step reasoning over visual content and cultural, historical, and stylistic context. While recent multimodal large language models show promise in artwork explanation, they rely on implicit reasoning and internalized knowl- edge, limiting interpretability and explicit evidence grounding. We propose A-MAR, an Agent-based Multimodal Art Retrieval framework that explicitly conditions retrieval on structured reasoning plans. Given an artwork and a user query, A-MAR first decomposes the task into a structured reasoning plan that specifies the goals and evidence requirements for each step. Retrieval is then conditionedon this plan, enabling targeted evidence selection and supporting step-wise, grounded explanations. To evaluate agent-based multi- modal reasoning within the art domain, we introduce ArtCoT-QA. This diagnostic benchmark features multi-step reasoning chains for diverse art-related queries, enabling a granular analysis that extends beyond simple final answer accuracy. Experiments on SemArt and Artpedia show that A-MAR consistently outperforms static, non planned retrieval and strong MLLM baselines in final explanation quality, while evaluations on ArtCoT-QA further demonstrate its advantages in evidence grounding and multi-step reasoning ability. These results highlight the importance of reasoning-conditioned retrieval for knowledge-intensive multimodal understanding and position A-MAR as a step toward interpretable, goal-driven AI systems, with particular relevance to cultural industries. The code and data are available at: https://github.com/ShuaiWang97/A-MAR.
A Novel Automatic Framework for Speaker Drift Detection in Synthesized Speech
Apr 07, 2026Recent diffusion-based text-to-speech (TTS) models achieve high naturalness and expressiveness, yet often suffer from speaker drift, a subtle, gradual shift in perceived speaker identity within a single utterance. This underexplored phenomenon undermines the coherence of synthetic speech, especially in long-form or interactive settings. We introduce the first automatic framework for detecting speaker drift by formulating it as a binary classification task over utterance-level speaker consistency. Our method computes cosine similarity across overlapping segments of synthesized speech and prompts large language models (LLMs) with structured representations to assess drift. We provide theoretical guarantees for cosine-based drift detection and demonstrate that speaker embeddings exhibit meaningful geometric clustering on the unit sphere. To support evaluation, we construct a high-quality synthetic benchmark with human-validated speaker drift annotations. Experiments with multiple state-of-the-art LLMs confirm the viability of this embedding-to-reasoning pipeline. Our work establishes speaker drift as a standalone research problem and bridges geometric signal analysis with LLM-based perceptual reasoning in modern TTS.
Are a Thousand Words Better Than a Single Picture? Beyond Images -- A Framework for Multi-Modal Knowledge Graph Dataset Enrichment
Mar 17, 2026Multi-Modal Knowledge Graphs (MMKGs) benefit from visual information, yet large-scale image collection is hard to curate and often excludes ambiguous but relevant visuals (e.g., logos, symbols, abstract scenes). We present Beyond Images, an automatic data-centric enrichment pipeline with optional human auditing. This pipeline operates in three stages: (1) large-scale retrieval of additional entity-related images, (2) conversion of all visual inputs into textual descriptions to ensure that ambiguous images contribute usable semantics rather than noise, and (3) fusion of multi-source descriptions using a large language model (LLM) to generate concise, entity-aligned summaries. These summaries replace or augment the text modality in standard MMKG models without changing their architectures or loss functions. Across three public MMKG datasets and multiple baseline models, we observe consistent gains (up to 7% Hits@1 overall). Furthermore, on a challenging subset of entities with visually ambiguous logos and symbols, converting images into text yields large improvements (201.35% MRR and 333.33% Hits@1). Additionally, we release a lightweight Text-Image Consistency Check Interface for optional targeted audits, improving description quality and dataset reliability. Our results show that scaling image coverage and converting ambiguous visuals into text is a practical path to stronger MMKG completion. Code, datasets, and supplementary materials are available at https://github.com/pengyu-zhang/Beyond-Images.
DeepEyeNet: Generating Medical Report for Retinal Images
Sep 16, 2025The increasing prevalence of retinal diseases poses a significant challenge to the healthcare system, as the demand for ophthalmologists surpasses the available workforce. This imbalance creates a bottleneck in diagnosis and treatment, potentially delaying critical care. Traditional methods of generating medical reports from retinal images rely on manual interpretation, which is time-consuming and prone to errors, further straining ophthalmologists' limited resources. This thesis investigates the potential of Artificial Intelligence (AI) to automate medical report generation for retinal images. AI can quickly analyze large volumes of image data, identifying subtle patterns essential for accurate diagnosis. By automating this process, AI systems can greatly enhance the efficiency of retinal disease diagnosis, reducing doctors' workloads and enabling them to focus on more complex cases. The proposed AI-based methods address key challenges in automated report generation: (1) A multi-modal deep learning approach captures interactions between textual keywords and retinal images, resulting in more comprehensive medical reports; (2) Improved methods for medical keyword representation enhance the system's ability to capture nuances in medical terminology; (3) Strategies to overcome RNN-based models' limitations, particularly in capturing long-range dependencies within medical descriptions; (4) Techniques to enhance the interpretability of the AI-based report generation system, fostering trust and acceptance in clinical practice. These methods are rigorously evaluated using various metrics and achieve state-of-the-art performance. This thesis demonstrates AI's potential to revolutionize retinal disease diagnosis by automating medical report generation, ultimately improving clinical efficiency, diagnostic accuracy, and patient care.
MaCP: Minimal yet Mighty Adaptation via Hierarchical Cosine Projection
May 29, 2025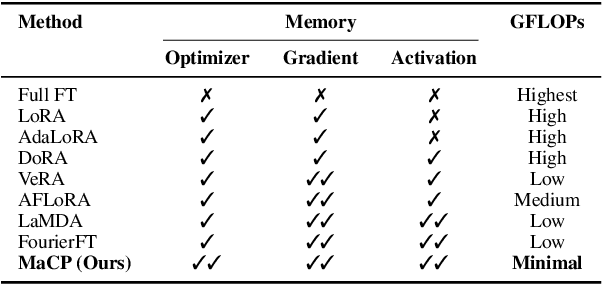
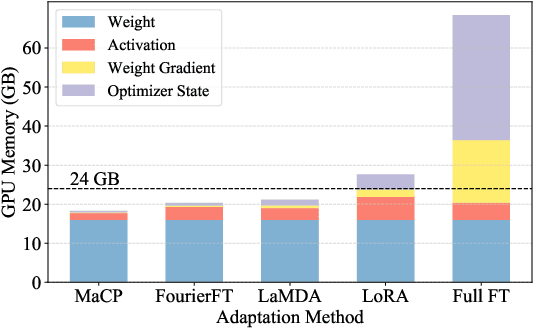
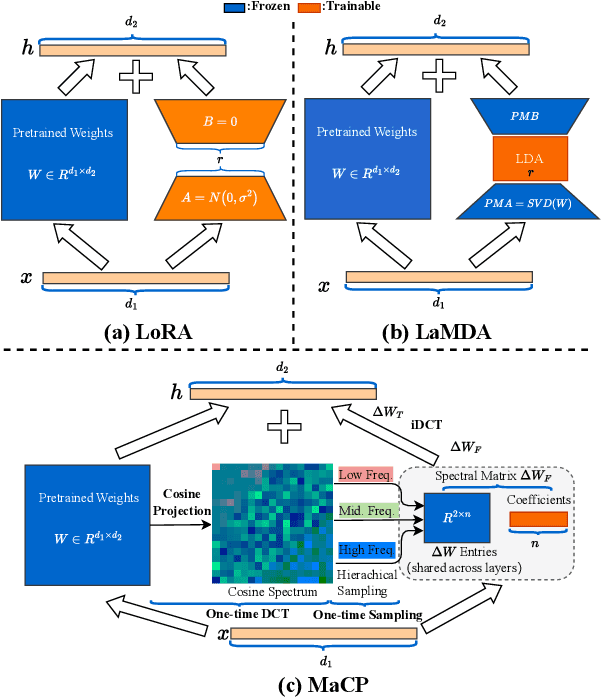
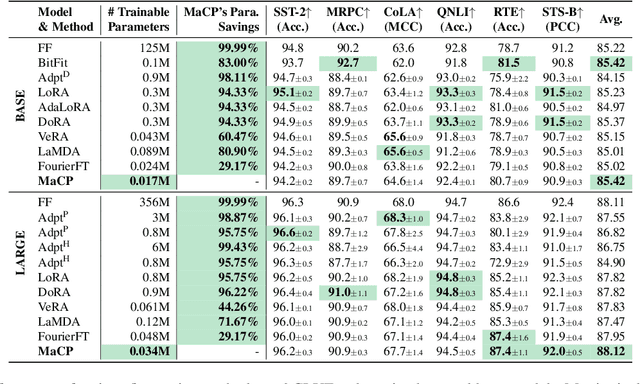
We present a new adaptation method MaCP, Minimal yet Mighty adaptive Cosine Projection, that achieves exceptional performance while requiring minimal parameters and memory for fine-tuning large foundation models. Its general idea is to exploit the superior energy compaction and decorrelation properties of cosine projection to improve both model efficiency and accuracy. Specifically, it projects the weight change from the low-rank adaptation into the discrete cosine space. Then, the weight change is partitioned over different levels of the discrete cosine spectrum, and each partition's most critical frequency components are selected. Extensive experiments demonstrate the effectiveness of MaCP across a wide range of single-modality tasks, including natural language understanding, natural language generation, text summarization, as well as multi-modality tasks such as image classification and video understanding. MaCP consistently delivers superior accuracy, significantly reduced computational complexity, and lower memory requirements compared to existing alternatives.
SSH: Sparse Spectrum Adaptation via Discrete Hartley Transformation
Feb 08, 2025



Low-rank adaptation (LoRA) has been demonstrated effective in reducing the trainable parameter number when fine-tuning a large foundation model (LLM). However, it still encounters computational and memory challenges when scaling to larger models or addressing more complex task adaptation. In this work, we introduce Sparse Spectrum Adaptation via Discrete Hartley Transformation (SSH), a novel approach that significantly reduces the number of trainable parameters while enhancing model performance. It selects the most informative spectral components across all layers, under the guidance of the initial weights after a discrete Hartley transformation (DHT). The lightweight inverse DHT then projects the spectrum back into the spatial domain for updates. Extensive experiments across both single-modality tasks such as language understanding and generation and multi-modality tasks such as video-text understanding demonstrate that SSH outperforms existing parameter-efficient fine-tuning (PEFT) methods while achieving substantial reductions in computational cost and memory requirements.
Gradient Weight-normalized Low-rank Projection for Efficient LLM Training
Dec 27, 2024Large Language Models (LLMs) have shown remarkable performance across various tasks, but the escalating demands on computational resources pose significant challenges, particularly in the extensive utilization of full fine-tuning for downstream tasks. To address this, parameter-efficient fine-tuning (PEFT) methods have been developed, but they often underperform compared to full fine-tuning and struggle with memory efficiency. In this work, we introduce Gradient Weight-Normalized Low-Rank Projection (GradNormLoRP), a novel approach that enhances both parameter and memory efficiency while maintaining comparable performance to full fine-tuning. GradNormLoRP normalizes the weight matrix to improve gradient conditioning, facilitating better convergence during optimization. Additionally, it applies low-rank approximations to the weight and gradient matrices, significantly reducing memory usage during training. Extensive experiments demonstrate that our 8-bit GradNormLoRP reduces optimizer memory usage by up to 89.5% and enables the pre-training of large LLMs, such as LLaMA 7B, on consumer-level GPUs like the NVIDIA RTX 4090, without additional inference costs. Moreover, GradNormLoRP outperforms existing low-rank methods in fine-tuning tasks. For instance, when fine-tuning the RoBERTa model on all GLUE tasks with a rank of 8, GradNormLoRP achieves an average score of 80.65, surpassing LoRA's score of 79.23. These results underscore GradNormLoRP as a promising alternative for efficient LLM pre-training and fine-tuning. Source code and Appendix: https://github.com/Jhhuangkay/Gradient-Weight-normalized-Low-rank-Projection-for-Efficient-LLM-Training
Image2Text2Image: A Novel Framework for Label-Free Evaluation of Image-to-Text Generation with Text-to-Image Diffusion Models
Nov 08, 2024



Evaluating the quality of automatically generated image descriptions is a complex task that requires metrics capturing various dimensions, such as grammaticality, coverage, accuracy, and truthfulness. Although human evaluation provides valuable insights, its cost and time-consuming nature pose limitations. Existing automated metrics like BLEU, ROUGE, METEOR, and CIDEr attempt to fill this gap, but they often exhibit weak correlations with human judgment. To address this challenge, we propose a novel evaluation framework called Image2Text2Image, which leverages diffusion models, such as Stable Diffusion or DALL-E, for text-to-image generation. In the Image2Text2Image framework, an input image is first processed by a selected image captioning model, chosen for evaluation, to generate a textual description. Using this generated description, a diffusion model then creates a new image. By comparing features extracted from the original and generated images, we measure their similarity using a designated similarity metric. A high similarity score suggests that the model has produced a faithful textual description, while a low score highlights discrepancies, revealing potential weaknesses in the model's performance. Notably, our framework does not rely on human-annotated reference captions, making it a valuable tool for assessing image captioning models. Extensive experiments and human evaluations validate the efficacy of our proposed Image2Text2Image evaluation framework. The code and dataset will be published to support further research in the community.
Parameter-Efficient Fine-Tuning via Selective Discrete Cosine Transform
Oct 09, 2024In the era of large language models, parameter-efficient fine-tuning (PEFT) has been extensively studied. However, these approaches usually rely on the space domain, which encounters storage challenges especially when handling extensive adaptations or larger models. The frequency domain, in contrast, is more effective in compressing trainable parameters while maintaining the expressive capability. In this paper, we propose a novel Selective Discrete Cosine Transformation (sDCTFT) fine-tuning scheme to push this frontier. Its general idea is to exploit the superior energy compaction and decorrelation properties of DCT to improve both model efficiency and accuracy. Specifically, it projects the weight change from the low-rank adaptation into the discrete cosine space. Then, the weight change is partitioned over different levels of the discrete cosine spectrum, and the most critical frequency components in each partition are selected. Extensive experiments on four benchmark datasets demonstrate the superior accuracy, reduced computational cost, and lower storage requirements of the proposed method over the prior arts. For instance, when performing instruction tuning on the LLaMA3.1-8B model, sDCTFT outperforms LoRA with just 0.05M trainable parameters compared to LoRA's 38.2M, and surpasses FourierFT with 30\% less trainable parameters. The source code will be publicly available.