 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInformation Retrieval for Climate Impact
Apr 01, 2025The purpose of the MANILA24 Workshop on information retrieval for climate impact was to bring together researchers from academia, industry, governments, and NGOs to identify and discuss core research problems in information retrieval to assess climate change impacts. The workshop aimed to foster collaboration by bringing communities together that have so far not been very well connected -- information retrieval, natural language processing, systematic reviews, impact assessments, and climate science. The workshop brought together a diverse set of researchers and practitioners interested in contributing to the development of a technical research agenda for information retrieval to assess climate change impacts.
Beyond Relevant Documents: A Knowledge-Intensive Approach for Query-Focused Summarization using Large Language Models
Aug 19, 2024Query-focused summarization (QFS) is a fundamental task in natural language processing with broad applications, including search engines and report generation. However, traditional approaches assume the availability of relevant documents, which may not always hold in practical scenarios, especially in highly specialized topics. To address this limitation, we propose a novel knowledge-intensive approach that reframes QFS as a knowledge-intensive task setup. This approach comprises two main components: a retrieval module and a summarization controller. The retrieval module efficiently retrieves potentially relevant documents from a large-scale knowledge corpus based on the given textual query, eliminating the dependence on pre-existing document sets. The summarization controller seamlessly integrates a powerful large language model (LLM)-based summarizer with a carefully tailored prompt, ensuring the generated summary is comprehensive and relevant to the query. To assess the effectiveness of our approach, we create a new dataset, along with human-annotated relevance labels, to facilitate comprehensive evaluation covering both retrieval and summarization performance. Extensive experiments demonstrate the superior performance of our approach, particularly its ability to generate accurate summaries without relying on the availability of relevant documents initially. This underscores our method's versatility and practical applicability across diverse query scenarios.
Scaling Up Query-Focused Summarization to Meet Open-Domain Question Answering
Dec 14, 2021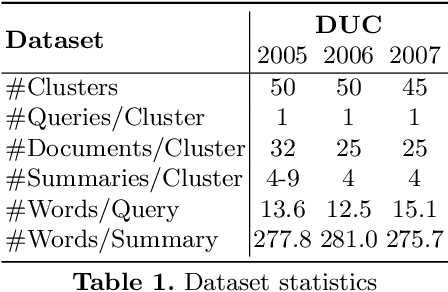
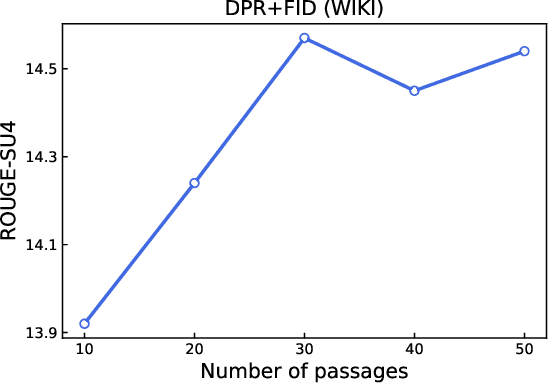
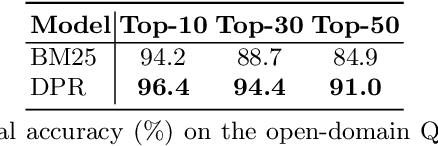
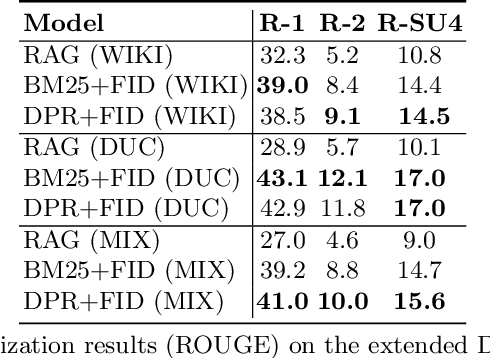
Query-focused summarization (QFS) requires generating a textual summary given a query using a set of relevant documents. However, in practice, such relevant documents are not readily available but should be first retrieved from a document collection. Therefore, we show how to extend this task to make it more realistic. Thereby the task setup also resembles the settings of the open-domain question answering task, where the answer is a summary of the top-retrieved documents. To address this extended task, we combine passage retrieval with text generation to produce the summary of the retrieved passages given the input query. We demonstrate the first evaluation results on the proposed task and show that a few samples are sufficient to fine-tune a large generative model with retrieved passages.