 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTCL: Enabling Fast and Efficient Cross-Hardware Tensor Program Optimization via Continual Learning
Apr 14, 2026Deep learning (DL) compilers rely on cost models and auto-tuning to optimize tensor programs for target hardware. However, existing approaches depend on large offline datasets, incurring high collection costs and offering suboptimal transferability across platforms. In this paper, we introduce TCL, a novel efficient and transferable compiler framework for fast tensor program optimization across diverse hardware platforms to address these challenges. Specifically, TCL is built on three core enablers: (1) the RDU Sampler, a data-efficient active learning strategy that selects only 10% of tensor programs by jointly optimizing Representativeness, Diversity, and Uncertainty, substantially reducing data collection costs while maintaining near-original model accuracy; (2) a new Mamba-based cost model that efficiently captures long-range schedule dependencies while achieving a favorable trade-off between prediction accuracy and computational cost through reduced parameterization and lightweight sequence modeling; and (3) a continuous knowledge distillation framework that effectively and progressively transfers knowledge across multiple hardware platforms while avoiding the parameter explosion and data dependency issues typically caused by traditional multi-task learning. Extensive experiments validate the effectiveness of each individual enabler and the holistic TCL framework. When optimizing a range of mainstream DL models on both CPU and GPU platforms, TCL achieves, on average, 16.8x and 12.48x faster tuning time, and 1.20x and 1.13x lower inference latency, respectively, compared to Tenset-MLP.
MaCP: Minimal yet Mighty Adaptation via Hierarchical Cosine Projection
May 29, 2025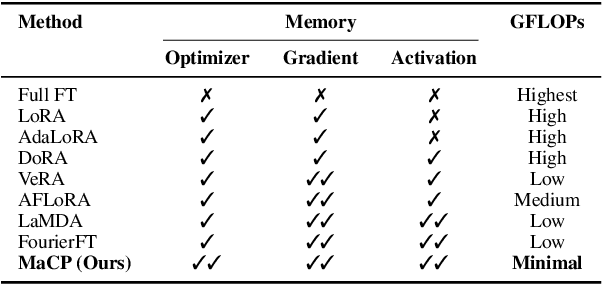
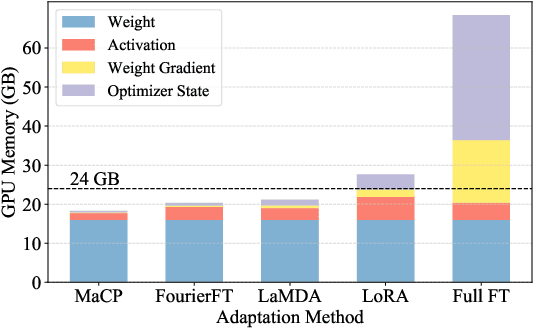
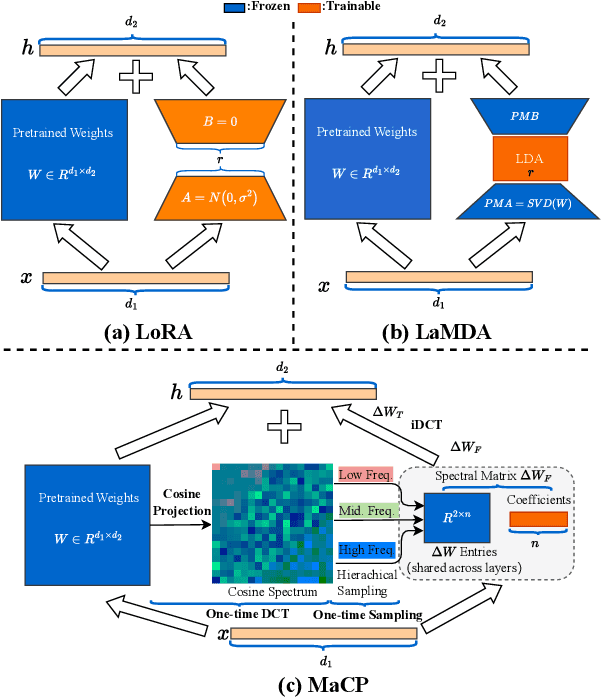
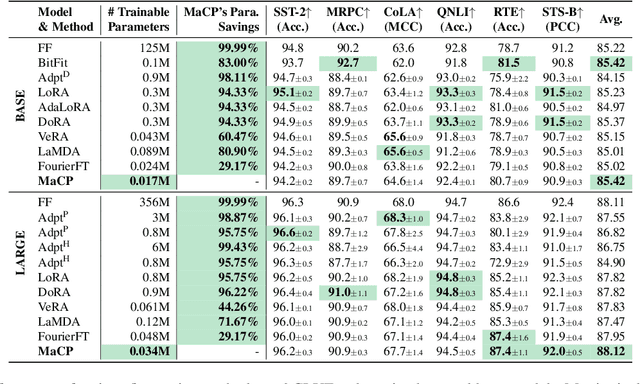
We present a new adaptation method MaCP, Minimal yet Mighty adaptive Cosine Projection, that achieves exceptional performance while requiring minimal parameters and memory for fine-tuning large foundation models. Its general idea is to exploit the superior energy compaction and decorrelation properties of cosine projection to improve both model efficiency and accuracy. Specifically, it projects the weight change from the low-rank adaptation into the discrete cosine space. Then, the weight change is partitioned over different levels of the discrete cosine spectrum, and each partition's most critical frequency components are selected. Extensive experiments demonstrate the effectiveness of MaCP across a wide range of single-modality tasks, including natural language understanding, natural language generation, text summarization, as well as multi-modality tasks such as image classification and video understanding. MaCP consistently delivers superior accuracy, significantly reduced computational complexity, and lower memory requirements compared to existing alternatives.
SSH: Sparse Spectrum Adaptation via Discrete Hartley Transformation
Feb 08, 2025



Low-rank adaptation (LoRA) has been demonstrated effective in reducing the trainable parameter number when fine-tuning a large foundation model (LLM). However, it still encounters computational and memory challenges when scaling to larger models or addressing more complex task adaptation. In this work, we introduce Sparse Spectrum Adaptation via Discrete Hartley Transformation (SSH), a novel approach that significantly reduces the number of trainable parameters while enhancing model performance. It selects the most informative spectral components across all layers, under the guidance of the initial weights after a discrete Hartley transformation (DHT). The lightweight inverse DHT then projects the spectrum back into the spatial domain for updates. Extensive experiments across both single-modality tasks such as language understanding and generation and multi-modality tasks such as video-text understanding demonstrate that SSH outperforms existing parameter-efficient fine-tuning (PEFT) methods while achieving substantial reductions in computational cost and memory requirements.
Finding Morton-Like Layouts for Multi-Dimensional Arrays Using Evolutionary Algorithms
Sep 13, 2023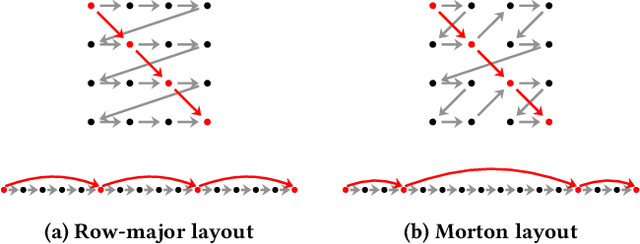


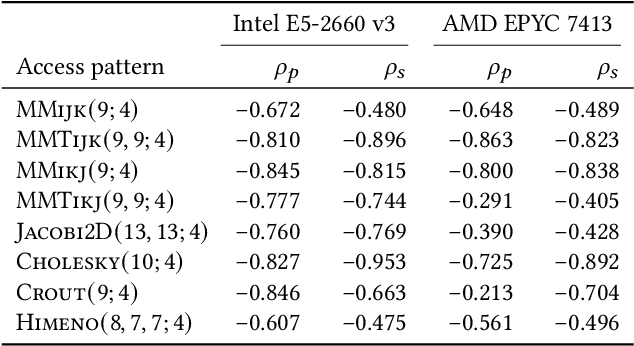
The layout of multi-dimensional data can have a significant impact on the efficacy of hardware caches and, by extension, the performance of applications. Common multi-dimensional layouts include the canonical row-major and column-major layouts as well as the Morton curve layout. In this paper, we describe how the Morton layout can be generalized to a very large family of multi-dimensional data layouts with widely varying performance characteristics. We posit that this design space can be efficiently explored using a combinatorial evolutionary methodology based on genetic algorithms. To this end, we propose a chromosomal representation for such layouts as well as a methodology for estimating the fitness of array layouts using cache simulation. We show that our fitness function correlates to kernel running time in real hardware, and that our evolutionary strategy allows us to find candidates with favorable simulated cache properties in four out of the eight real-world applications under consideration in a small number of generations. Finally, we demonstrate that the array layouts found using our evolutionary method perform well not only in simulated environments but that they can effect significant performance gains -- up to a factor ten in extreme cases -- in real hardware.
AutoDiCE: Fully Automated Distributed CNN Inference at the Edge
Jul 20, 2022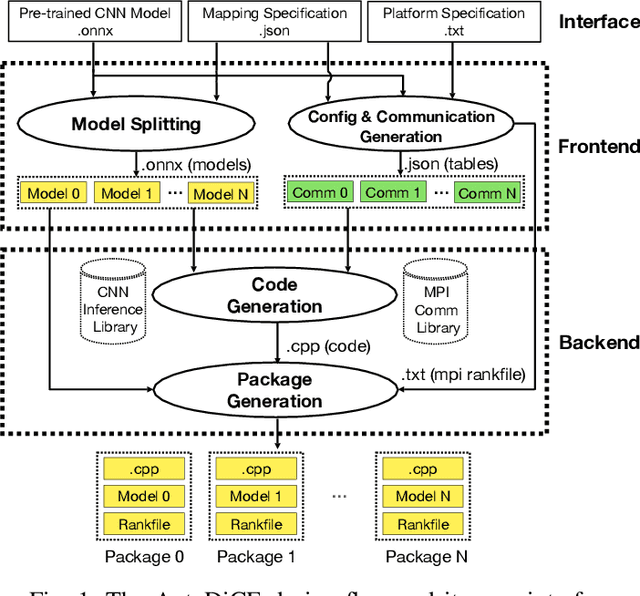
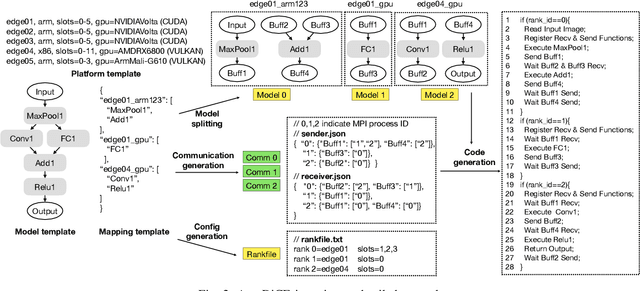
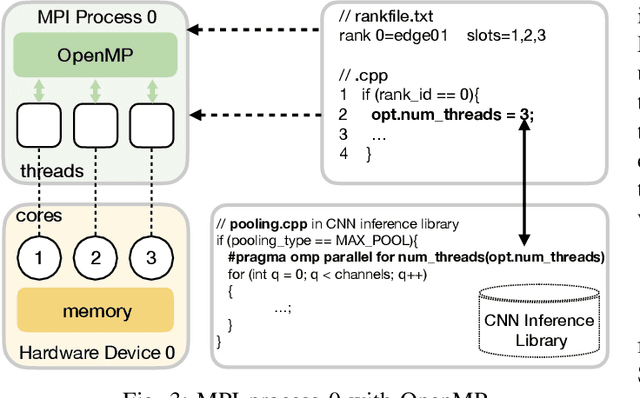
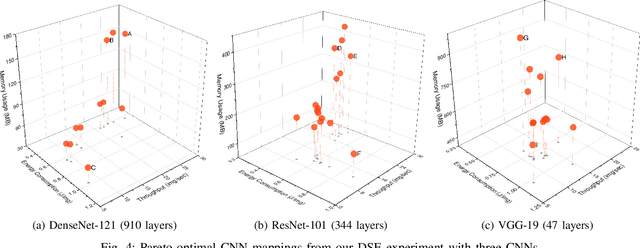
Deep Learning approaches based on Convolutional Neural Networks (CNNs) are extensively utilized and very successful in a wide range of application areas, including image classification and speech recognition. For the execution of trained CNNs, i.e. model inference, we nowadays witness a shift from the Cloud to the Edge. Unfortunately, deploying and inferring large, compute and memory intensive CNNs on edge devices is challenging because these devices typically have limited power budgets and compute/memory resources. One approach to address this challenge is to leverage all available resources across multiple edge devices to deploy and execute a large CNN by properly partitioning the CNN and running each CNN partition on a separate edge device. Although such distribution, deployment, and execution of large CNNs on multiple edge devices is a desirable and beneficial approach, there currently does not exist a design and programming framework that takes a trained CNN model, together with a CNN partitioning specification, and fully automates the CNN model splitting and deployment on multiple edge devices to facilitate distributed CNN inference at the Edge. Therefore, in this paper, we propose a novel framework, called AutoDiCE, for automated splitting of a CNN model into a set of sub-models and automated code generation for distributed and collaborative execution of these sub-models on multiple, possibly heterogeneous, edge devices, while supporting the exploitation of parallelism among and within the edge devices. Our experimental results show that AutoDiCE can deliver distributed CNN inference with reduced energy consumption and memory usage per edge device, and improved overall system throughput at the same time.
Exploring Task Mappings on Heterogeneous MPSoCs using a Bias-Elitist Genetic Algorithm
Jun 29, 2014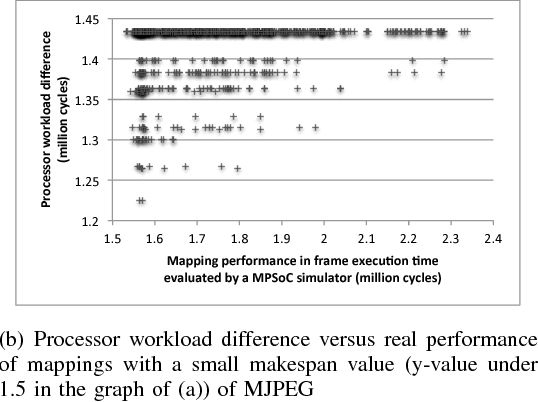
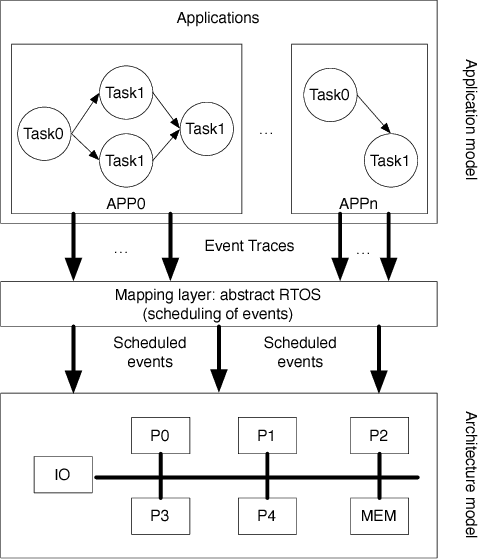
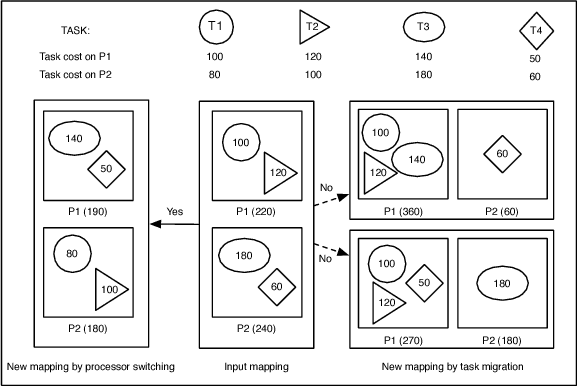
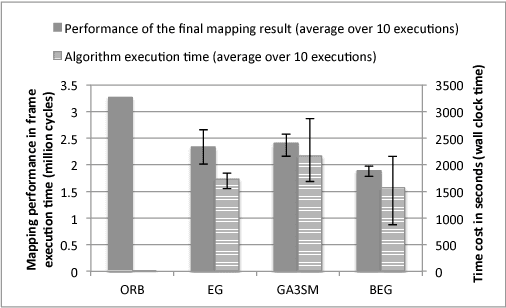
Exploration of task mappings plays a crucial role in achieving high performance in heterogeneous multi-processor system-on-chip (MPSoC) platforms. The problem of optimally mapping a set of tasks onto a set of given heterogeneous processors for maximal throughput has been known, in general, to be NP-complete. The problem is further exacerbated when multiple applications (i.e., bigger task sets) and the communication between tasks are also considered. Previous research has shown that Genetic Algorithms (GA) typically are a good choice to solve this problem when the solution space is relatively small. However, when the size of the problem space increases, classic genetic algorithms still suffer from the problem of long evolution times. To address this problem, this paper proposes a novel bias-elitist genetic algorithm that is guided by domain-specific heuristics to speed up the evolution process. Experimental results reveal that our proposed algorithm is able to handle large scale task mapping problems and produces high-quality mapping solutions in only a short time period.