 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCVAM-Pose: Conditional Variational Autoencoder for Multi-Object Monocular Pose Estimation
Oct 11, 2024



Estimating rigid objects' poses is one of the fundamental problems in computer vision, with a range of applications across automation and augmented reality. Most existing approaches adopt one network per object class strategy, depend heavily on objects' 3D models, depth data, and employ a time-consuming iterative refinement, which could be impractical for some applications. This paper presents a novel approach, CVAM-Pose, for multi-object monocular pose estimation that addresses these limitations. The CVAM-Pose method employs a label-embedded conditional variational autoencoder network, to implicitly abstract regularised representations of multiple objects in a single low-dimensional latent space. This autoencoding process uses only images captured by a projective camera and is robust to objects' occlusion and scene clutter. The classes of objects are one-hot encoded and embedded throughout the network. The proposed label-embedded pose regression strategy interprets the learnt latent space representations utilising continuous pose representations. Ablation tests and systematic evaluations demonstrate the scalability and efficiency of the CVAM-Pose method for multi-object scenarios. The proposed CVAM-Pose outperforms competing latent space approaches. For example, it is respectively 25% and 20% better than AAE and Multi-Path methods, when evaluated using the $\mathrm{AR_{VSD}}$ metric on the Linemod-Occluded dataset. It also achieves results somewhat comparable to methods reliant on 3D models reported in BOP challenges. Code available: https://github.com/JZhao12/CVAM-Pose
Distilling Knowledge from Resource Management Algorithms to Neural Networks: A Unified Training Assistance Approach
Aug 15, 2023



As a fundamental problem, numerous methods are dedicated to the optimization of signal-to-interference-plus-noise ratio (SINR), in a multi-user setting. Although traditional model-based optimization methods achieve strong performance, the high complexity raises the research of neural network (NN) based approaches to trade-off the performance and complexity. To fully leverage the high performance of traditional model-based methods and the low complexity of the NN-based method, a knowledge distillation (KD) based algorithm distillation (AD) method is proposed in this paper to improve the performance and convergence speed of the NN-based method, where traditional SINR optimization methods are employed as ``teachers" to assist the training of NNs, which are ``students", thus enhancing the performance of unsupervised and reinforcement learning techniques. This approach aims to alleviate common issues encountered in each of these training paradigms, including the infeasibility of obtaining optimal solutions as labels and overfitting in supervised learning, ensuring higher convergence performance in unsupervised learning, and improving training efficiency in reinforcement learning. Simulation results demonstrate the enhanced performance of the proposed AD-based methods compared to traditional learning methods. Remarkably, this research paves the way for the integration of traditional optimization insights and emerging NN techniques in wireless communication system optimization.
Yelp Reviews and Food Types: A Comparative Analysis of Ratings, Sentiments, and Topics
Jul 20, 2023This study examines the relationship between Yelp reviews and food types, investigating how ratings, sentiments, and topics vary across different types of food. Specifically, we analyze how ratings and sentiments of reviews vary across food types, cluster food types based on ratings and sentiments, infer review topics using machine learning models, and compare topic distributions among different food types. Our analyses reveal that some food types have similar ratings, sentiments, and topics distributions, while others have distinct patterns. We identify four clusters of food types based on ratings and sentiments and find that reviewers tend to focus on different topics when reviewing certain food types. These findings have important implications for understanding user behavior and cultural influence on digital media platforms and promoting cross-cultural understanding and appreciation.
Exploring the Emotional and Mental Well-Being of Individuals with Long COVID Through Twitter Analysis
Jul 11, 2023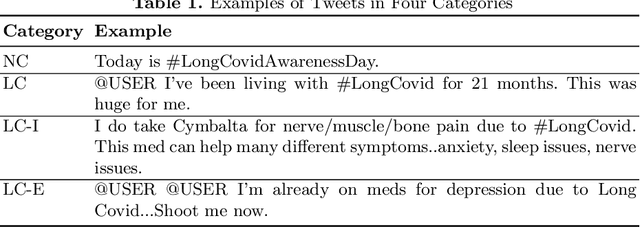
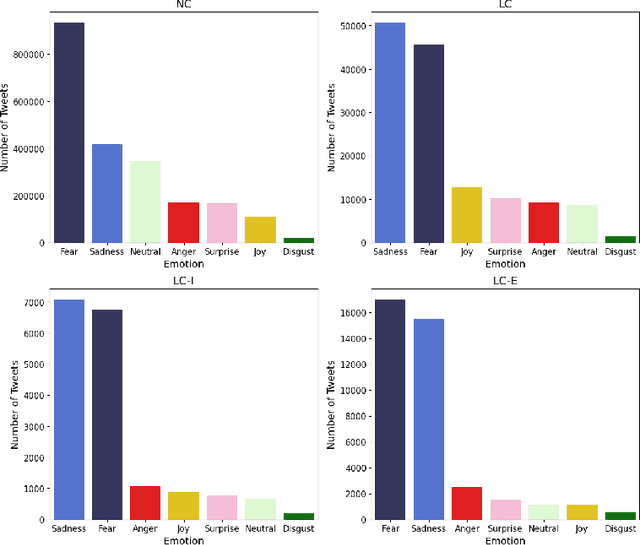
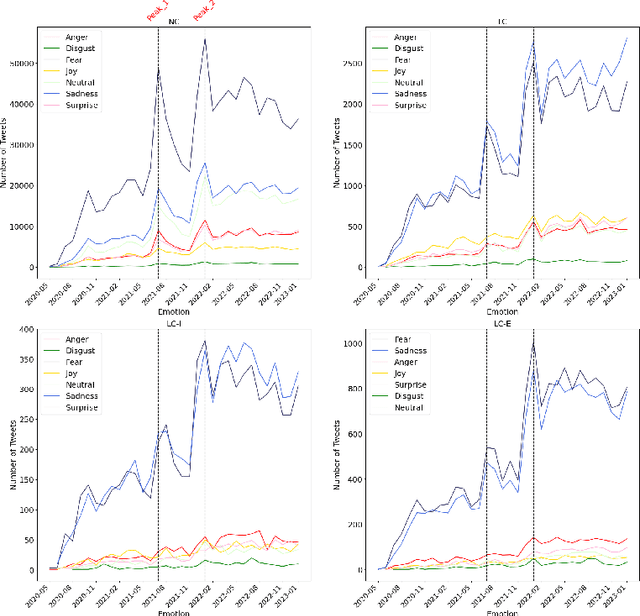
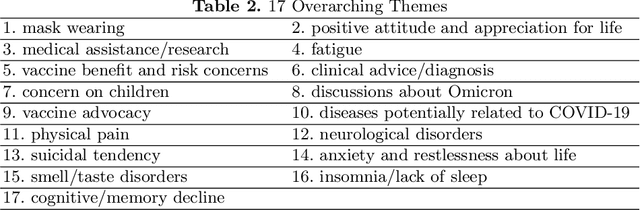
The COVID-19 pandemic has led to the emergence of Long COVID, a cluster of symptoms that persist after infection. Long COVID patients may also experience mental health challenges, making it essential to understand individuals' emotional and mental well-being. This study aims to gain a deeper understanding of Long COVID individuals' emotional and mental well-being, identify the topics that most concern them, and explore potential correlations between their emotions and social media activity. Specifically, we classify tweets into four categories based on the content, detect the presence of six basic emotions, and extract prevalent topics. Our analyses reveal that negative emotions dominated throughout the study period, with two peaks during critical periods, such as the outbreak of new COVID variants. The findings of this study have implications for policy and measures for addressing the mental health challenges of individuals with Long COVID and provide a foundation for future work.
Scalable Resource Management for Dynamic MEC: An Unsupervised Link-Output Graph Neural Network Approach
Jun 20, 2023



Deep learning has been successfully adopted in mobile edge computing (MEC) to optimize task offloading and resource allocation. However, the dynamics of edge networks raise two challenges in neural network (NN)-based optimization methods: low scalability and high training costs. Although conventional node-output graph neural networks (GNN) can extract features of edge nodes when the network scales, they fail to handle a new scalability issue whereas the dimension of the decision space may change as the network scales. To address the issue, in this paper, a novel link-output GNN (LOGNN)-based resource management approach is proposed to flexibly optimize the resource allocation in MEC for an arbitrary number of edge nodes with extremely low algorithm inference delay. Moreover, a label-free unsupervised method is applied to train the LOGNN efficiently, where the gradient of edge tasks processing delay with respect to the LOGNN parameters is derived explicitly. In addition, a theoretical analysis of the scalability of the node-output GNN and link-output GNN is performed. Simulation results show that the proposed LOGNN can efficiently optimize the MEC resource allocation problem in a scalable way, with an arbitrary number of servers and users. In addition, the proposed unsupervised training method has better convergence performance and speed than supervised learning and reinforcement learning-based training methods. The code is available at \url{https://github.com/UNIC-Lab/LOGNN}.
A Novel Multi-Objective Velocity-Free Boolean Particle Swarm Optimization
Oct 12, 2022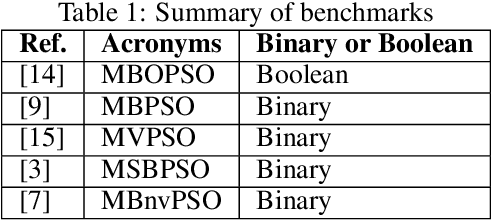
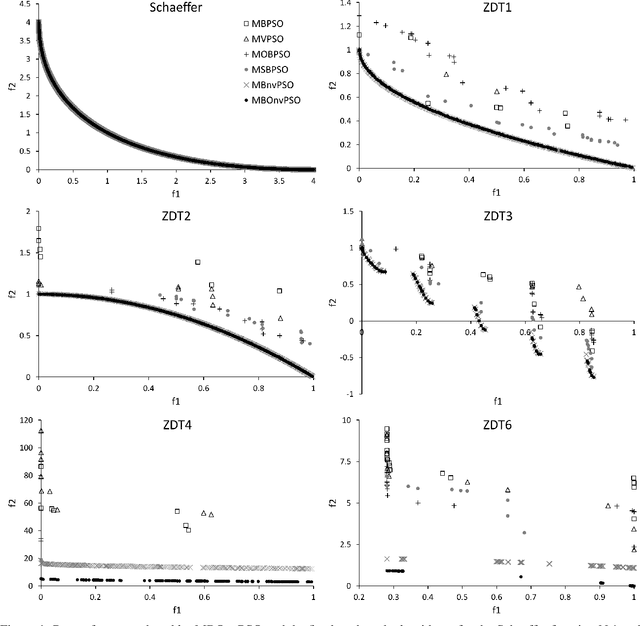

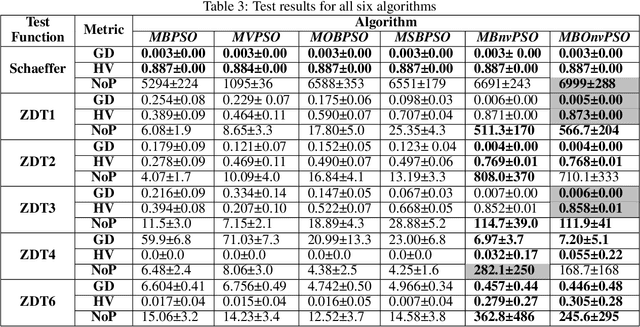
This paper extends boolean particle swarm optimization to a multi-objective setting, to our knowledge for the first time in the literature. Our proposed new boolean algorithm, MBOnvPSO, is notably simplified by the omission of a velocity update rule and has enhanced exploration ability due to the inclusion of a 'noise' term in the position update rule that prevents particles being trapped in local optima. Our algorithm additionally makes use of an external archive to store non-dominated solutions and implements crowding distance to encourage solution diversity. In benchmark tests, MBOnvPSO produced high quality Pareto fronts, when compared to benchmarked alternatives, for all of the multi-objective test functions considered, with competitive performance in search spaces with up to 600 discrete dimensions.
Correlated Anomaly Detection from Large Streaming Data
Jan 14, 2019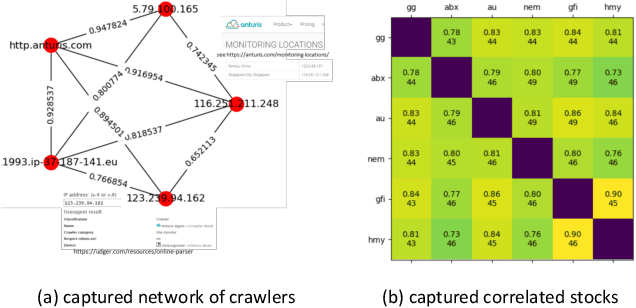
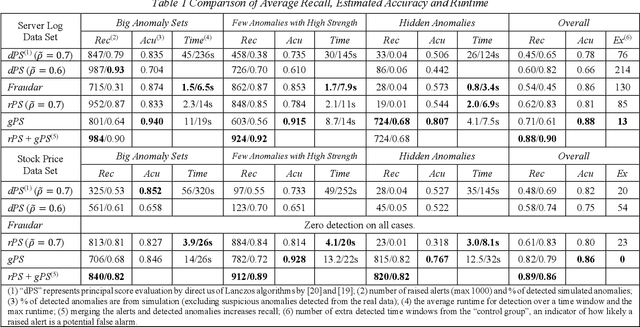
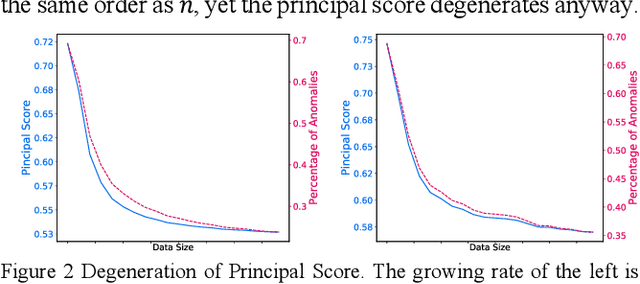
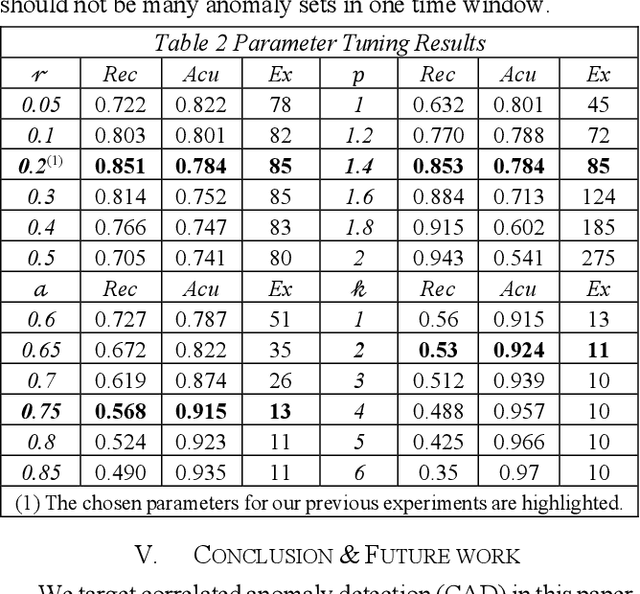
Correlated anomaly detection (CAD) from streaming data is a type of group anomaly detection and an essential task in useful real-time data mining applications like botnet detection, financial event detection, industrial process monitor, etc. The primary approach for this type of detection in previous researches is based on principal score (PS) of divided batches or sliding windows by computing top eigenvalues of the correlation matrix, e.g. the Lanczos algorithm. However, this paper brings up the phenomenon of principal score degeneration for large data set, and then mathematically and practically prove current PS-based methods are likely to fail for CAD on large-scale streaming data even if the number of correlated anomalies grows with the data size at a reasonable rate; in reality, anomalies tend to be the minority of the data, and this issue can be more serious. We propose a framework with two novel randomized algorithms rPS and gPS for better detection of correlated anomalies from large streaming data of various correlation strength. The experiment shows high and balanced recall and estimated accuracy of our framework for anomaly detection from a large server log data set and a U.S. stock daily price data set in comparison to direct principal score evaluation and some other recent group anomaly detection algorithms. Moreover, our techniques significantly improve the computation efficiency and scalability for principal score calculation.
Exploring Task Mappings on Heterogeneous MPSoCs using a Bias-Elitist Genetic Algorithm
Jun 29, 2014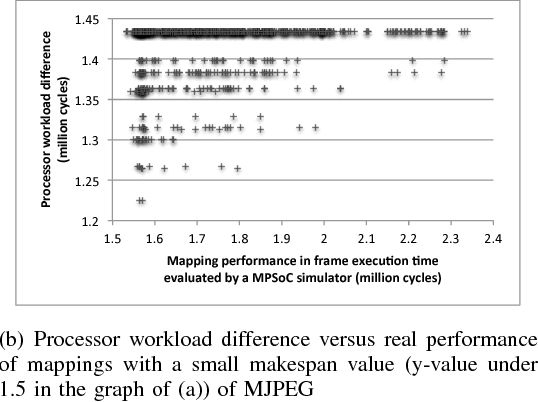
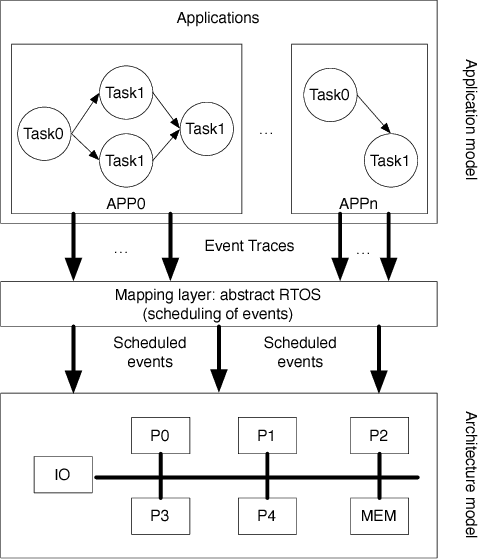
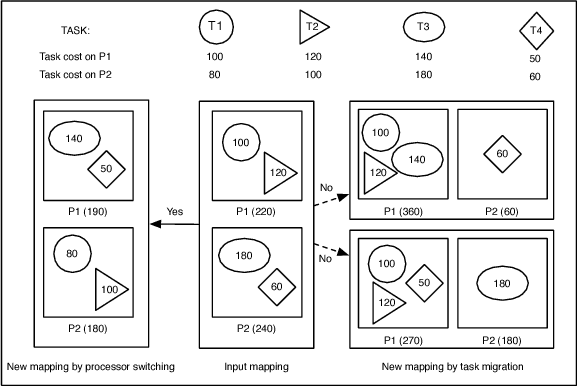
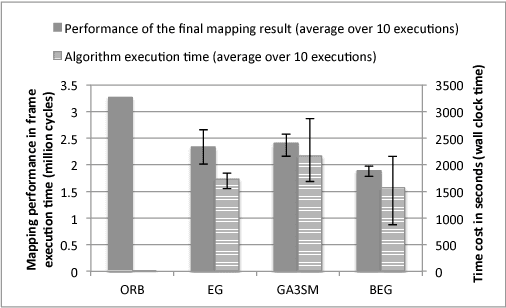
Exploration of task mappings plays a crucial role in achieving high performance in heterogeneous multi-processor system-on-chip (MPSoC) platforms. The problem of optimally mapping a set of tasks onto a set of given heterogeneous processors for maximal throughput has been known, in general, to be NP-complete. The problem is further exacerbated when multiple applications (i.e., bigger task sets) and the communication between tasks are also considered. Previous research has shown that Genetic Algorithms (GA) typically are a good choice to solve this problem when the solution space is relatively small. However, when the size of the problem space increases, classic genetic algorithms still suffer from the problem of long evolution times. To address this problem, this paper proposes a novel bias-elitist genetic algorithm that is guided by domain-specific heuristics to speed up the evolution process. Experimental results reveal that our proposed algorithm is able to handle large scale task mapping problems and produces high-quality mapping solutions in only a short time period.