 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge-Scale Joint Topic, Sentiment & User Preference Analysis for Online Reviews
Jan 14, 2019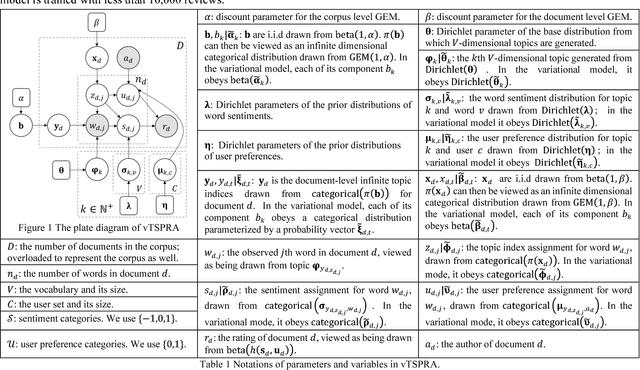
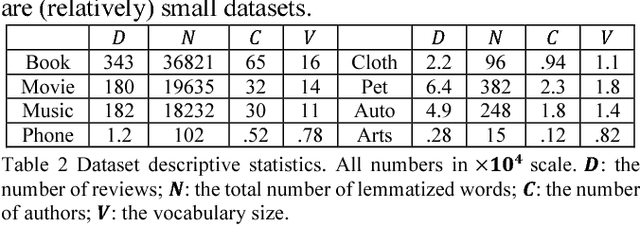
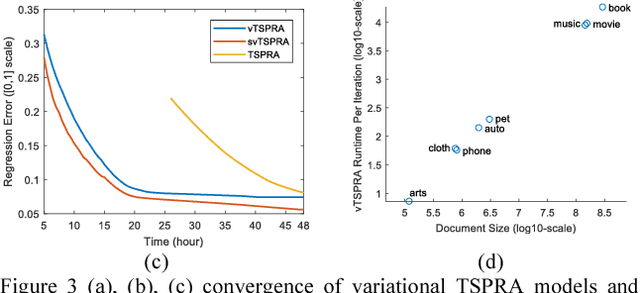
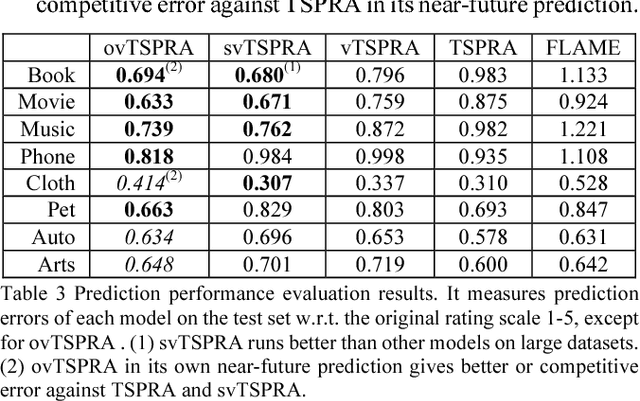
This paper presents a non-trivial reconstruction of a previous joint topic-sentiment-preference review model TSPRA with stick-breaking representation under the framework of variational inference (VI) and stochastic variational inference (SVI). TSPRA is a Gibbs Sampling based model that solves topics, word sentiments and user preferences altogether and has been shown to achieve good performance, but for large data set it can only learn from a relatively small sample. We develop the variational models vTSPRA and svTSPRA to improve the time use, and our new approach is capable of processing millions of reviews. We rebuild the generative process, improve the rating regression, solve and present the coordinate-ascent updates of variational parameters, and show the time complexity of each iteration is theoretically linear to the corpus size, and the experiments on Amazon data sets show it converges faster than TSPRA and attains better results given the same amount of time. In addition, we tune svTSPRA into an online algorithm ovTSPRA that can monitor oscillations of sentiment and preference overtime. Some interesting fluctuations are captured and possible explanations are provided. The results give strong visual evidence that user preference is better treated as an independent factor from sentiment.
Correlated Anomaly Detection from Large Streaming Data
Jan 14, 2019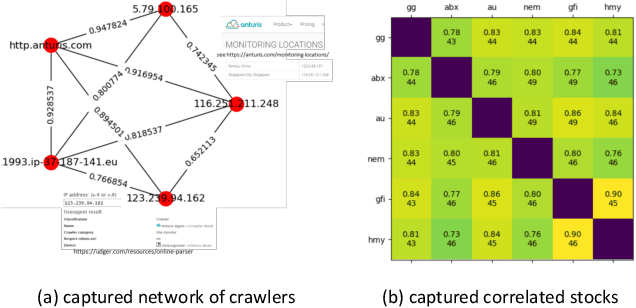
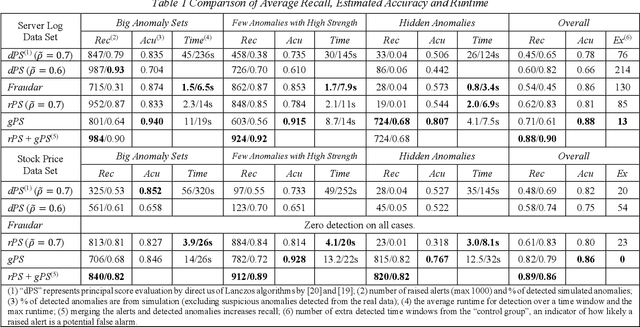
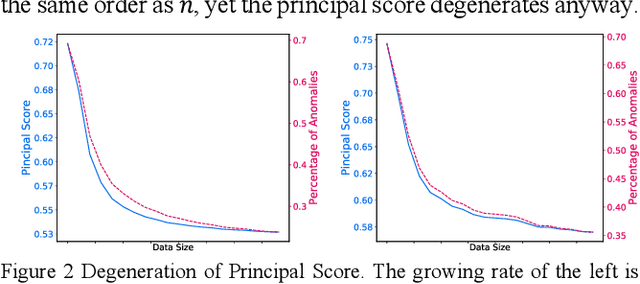
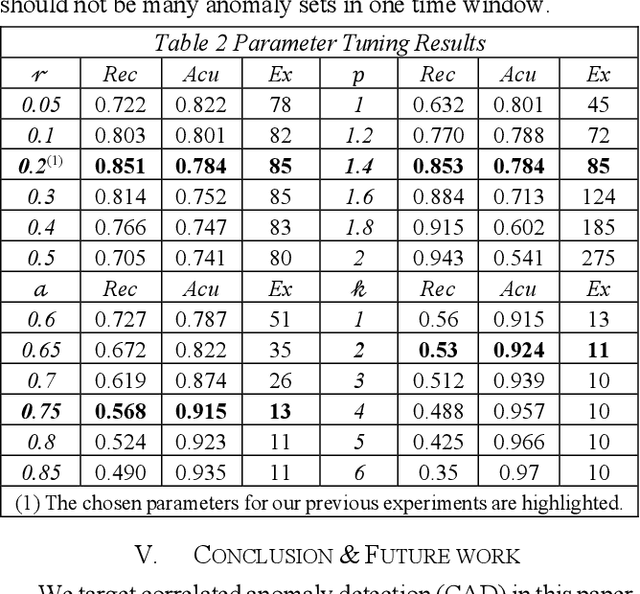
Correlated anomaly detection (CAD) from streaming data is a type of group anomaly detection and an essential task in useful real-time data mining applications like botnet detection, financial event detection, industrial process monitor, etc. The primary approach for this type of detection in previous researches is based on principal score (PS) of divided batches or sliding windows by computing top eigenvalues of the correlation matrix, e.g. the Lanczos algorithm. However, this paper brings up the phenomenon of principal score degeneration for large data set, and then mathematically and practically prove current PS-based methods are likely to fail for CAD on large-scale streaming data even if the number of correlated anomalies grows with the data size at a reasonable rate; in reality, anomalies tend to be the minority of the data, and this issue can be more serious. We propose a framework with two novel randomized algorithms rPS and gPS for better detection of correlated anomalies from large streaming data of various correlation strength. The experiment shows high and balanced recall and estimated accuracy of our framework for anomaly detection from a large server log data set and a U.S. stock daily price data set in comparison to direct principal score evaluation and some other recent group anomaly detection algorithms. Moreover, our techniques significantly improve the computation efficiency and scalability for principal score calculation.
Fast Botnet Detection From Streaming Logs Using Online Lanczos Method
Dec 19, 2018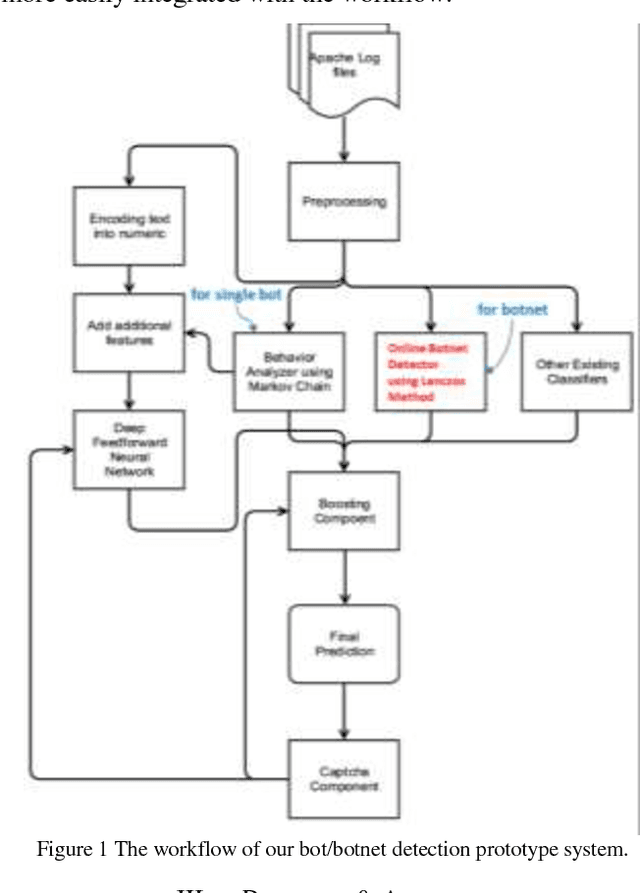
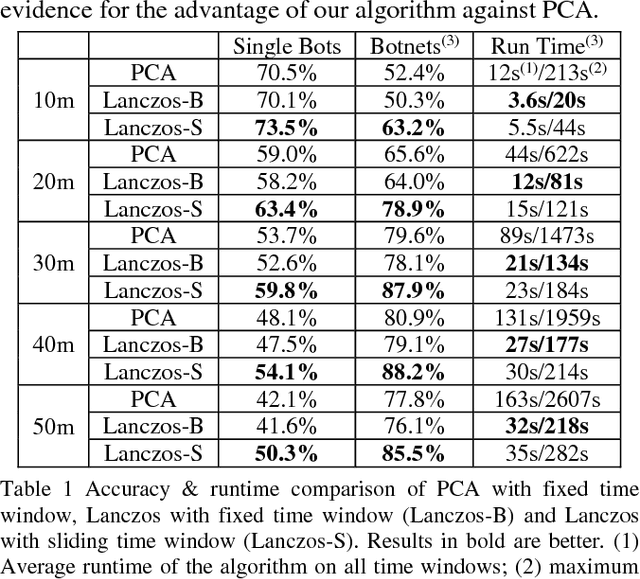


Botnet, a group of coordinated bots, is becoming the main platform of malicious Internet activities like DDOS, click fraud, web scraping, spam/rumor distribution, etc. This paper focuses on design and experiment of a new approach for botnet detection from streaming web server logs, motivated by its wide applicability, real-time protection capability, ease of use and better security of sensitive data. Our algorithm is inspired by a Principal Component Analysis (PCA) to capture correlation in data, and we are first to recognize and adapt Lanczos method to improve the time complexity of PCA-based botnet detection from cubic to sub-cubic, which enables us to more accurately and sensitively detect botnets with sliding time windows rather than fixed time windows. We contribute a generalized online correlation matrix update formula, and a new termination condition for Lanczos iteration for our purpose based on error bound and non-decreasing eigenvalues of symmetric matrices. On our dataset of an ecommerce website logs, experiments show the time cost of Lanczos method with different time windows are consistently only 20% to 25% of PCA.
A natural language interface to a graph-based bibliographic information retrieval system
Dec 10, 2016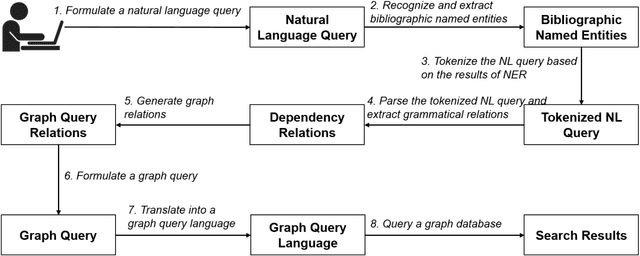

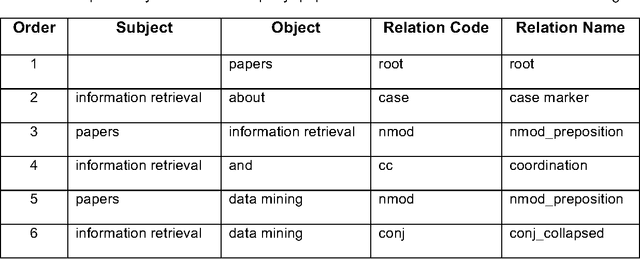
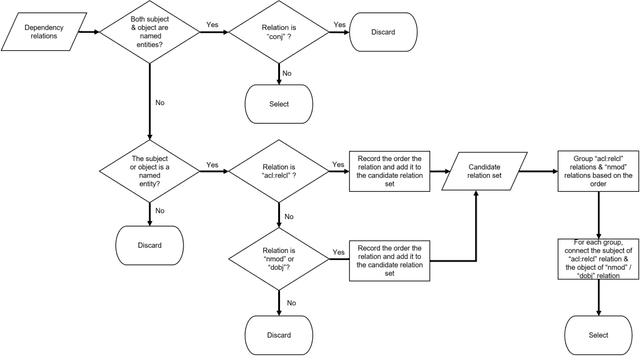
With the ever-increasing scientific literature, there is a need on a natural language interface to bibliographic information retrieval systems to retrieve related information effectively. In this paper, we propose a natural language interface, NLI-GIBIR, to a graph-based bibliographic information retrieval system. In designing NLI-GIBIR, we developed a novel framework that can be applicable to graph-based bibliographic information retrieval systems. Our framework integrates algorithms/heuristics for interpreting and analyzing natural language bibliographic queries. NLI-GIBIR allows users to search for a variety of bibliographic data through natural language. A series of text- and linguistic-based techniques are used to analyze and answer natural language queries, including tokenization, named entity recognition, and syntactic analysis. We find that our framework can effectively represents and addresses complex bibliographic information needs. Thus, the contributions of this paper are as follows: First, to our knowledge, it is the first attempt to propose a natural language interface to graph-based bibliographic information retrieval. Second, we propose a novel customized natural language processing framework that integrates a few original algorithms/heuristics for interpreting and analyzing natural language bibliographic queries. Third, we show that the proposed framework and natural language interface provide a practical solution in building real-world natural language interface-based bibliographic information retrieval systems. Our experimental results show that the presented system can correctly answer 39 out of 40 example natural language queries with varying lengths and complexities.